 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision for Geo-Temporal Deep Research Systems: Towards Comprehensive, Transparent, and Reproducible Geo-Temporal Information Synthesis
Jun 17, 2025The emergence of Large Language Models (LLMs) has transformed information access, with current LLMs also powering deep research systems that can generate comprehensive report-style answers, through planned iterative search, retrieval, and reasoning. Still, current deep research systems lack the geo-temporal capabilities that are essential for answering context-rich questions involving geographic and/or temporal constraints, frequently occurring in domains like public health, environmental science, or socio-economic analysis. This paper reports our vision towards next generation systems, identifying important technical, infrastructural, and evaluative challenges in integrating geo-temporal reasoning into deep research pipelines. We argue for augmenting retrieval and synthesis processes with the ability to handle geo-temporal constraints, supported by open and reproducible infrastructures and rigorous evaluation protocols. Our vision outlines a path towards more advanced and geo-temporally aware deep research systems, of potential impact to the future of AI-driven information access.
Evaluation of Code LLMs on Geospatial Code Generation
Oct 06, 2024Software development support tools have been studied for a long time, with recent approaches using Large Language Models (LLMs) for code generation. These models can generate Python code for data science and machine learning applications. LLMs are helpful for software engineers because they increase productivity in daily work. An LLM can also serve as a "mentor" for inexperienced software developers, and be a viable learning support. High-quality code generation with LLMs can also be beneficial in geospatial data science. However, this domain poses different challenges, and code generation LLMs are typically not evaluated on geospatial tasks. Here, we show how we constructed an evaluation benchmark for code generation models, based on a selection of geospatial tasks. We categorised geospatial tasks based on their complexity and required tools. Then, we created a dataset with tasks that test model capabilities in spatial reasoning, spatial data processing, and geospatial tools usage. The dataset consists of specific coding problems that were manually created for high quality. For every problem, we proposed a set of test scenarios that make it possible to automatically check the generated code for correctness. In addition, we tested a selection of existing code generation LLMs for code generation in the geospatial domain. We share our dataset and reproducible evaluation code on a public GitHub repository, arguing that this can serve as an evaluation benchmark for new LLMs in the future. Our dataset will hopefully contribute to the development new models capable of solving geospatial coding tasks with high accuracy. These models will enable the creation of coding assistants tailored for geospatial applications.
SRAI: Towards Standardization of Geospatial AI
Oct 23, 2023Spatial Representations for Artificial Intelligence (srai) is a Python library for working with geospatial data. The library can download geospatial data, split a given area into micro-regions using multiple algorithms and train an embedding model using various architectures. It includes baseline models as well as more complex methods from published works. Those capabilities make it possible to use srai in a complete pipeline for geospatial task solving. The proposed library is the first step to standardize the geospatial AI domain toolset. It is fully open-source and published under Apache 2.0 licence.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023



With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
highway2vec -- representing OpenStreetMap microregions with respect to their road network characteristics
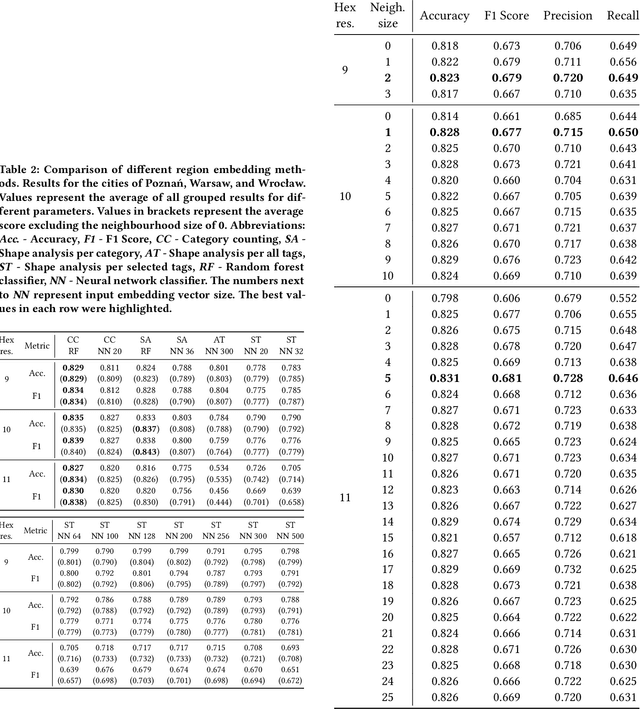
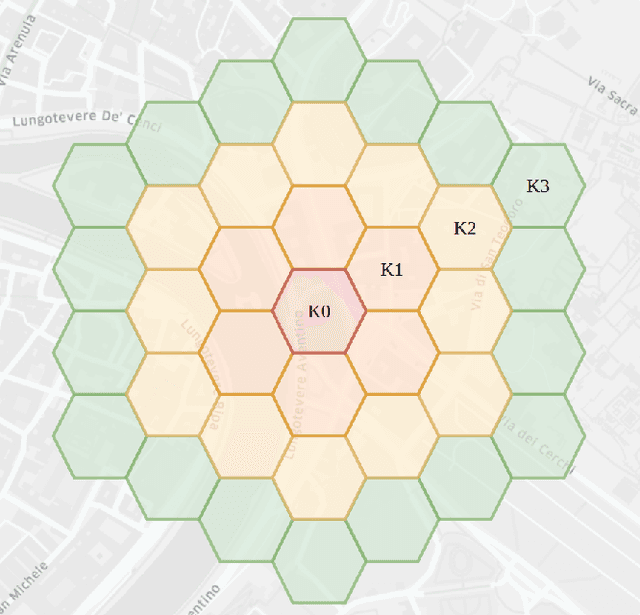
Apr 26, 2023Recent years brought advancements in using neural networks for representation learning of various language or visual phenomena. New methods freed data scientists from hand-crafting features for common tasks. Similarly, problems that require considering the spatial variable can benefit from pretrained map region representations instead of manually creating feature tables that one needs to prepare to solve a task. However, very few methods for map area representation exist, especially with respect to road network characteristics. In this paper, we propose a method for generating microregions' embeddings with respect to their road infrastructure characteristics. We base our representations on OpenStreetMap road networks in a selection of cities and use the H3 spatial index to allow reproducible and scalable representation learning. We obtained vector representations that detect how similar map hexagons are in the road networks they contain. Additionally, we observe that embeddings yield a latent space with meaningful arithmetic operations. Finally, clustering methods allowed us to draft a high-level typology of obtained representations. We are confident that this contribution will aid data scientists working on infrastructure-related prediction tasks with spatial variables.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
gtfs2vec -- Learning GTFS Embeddings for comparing Public Transport Offer in Microregions
Nov 02, 2021

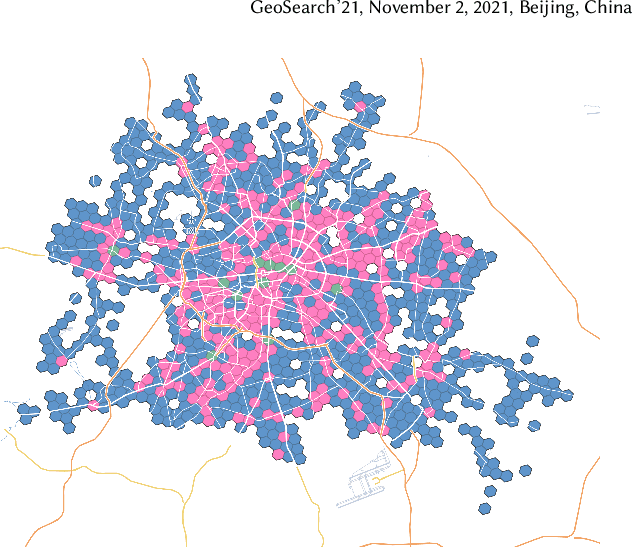
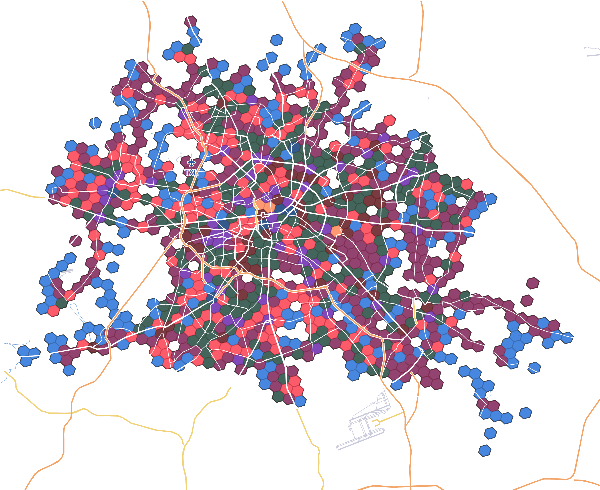
We selected 48 European cities and gathered their public transport timetables in the GTFS format. We utilized Uber's H3 spatial index to divide each city into hexagonal micro-regions. Based on the timetables data we created certain features describing the quantity and variety of public transport availability in each region. Next, we trained an auto-associative deep neural network to embed each of the regions. Having such prepared representations, we then used a hierarchical clustering approach to identify similar regions. To do so, we utilized an agglomerative clustering algorithm with a euclidean distance between regions and Ward's method to minimize in-cluster variance. Finally, we analyzed the obtained clusters at different levels to identify some number of clusters that qualitatively describe public transport availability. We showed that our typology matches the characteristics of analyzed cities and allows succesful searching for areas with similar public transport schedule characteristics.
Transfer Learning Approach to Bicycle-sharing Systems' Station Location Planning using OpenStreetMap Data
Nov 01, 2021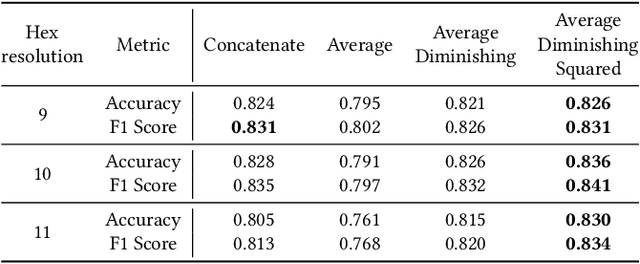
Bicycle-sharing systems (BSS) have become a daily reality for many citizens of larger, wealthier cities in developed regions. However, planning the layout of bicycle-sharing stations usually requires expensive data gathering, surveying travel behavior and trip modelling followed by station layout optimization. Many smaller cities and towns, especially in developing areas, may have difficulty financing such projects. Planning a BSS also takes a considerable amount of time. Yet as the pandemic has shown us, municipalities will face the need to adapt rapidly to mobility shifts, which include citizens leaving public transport for bicycles. Laying out a bike sharing system quickly will become critical in addressing the increase in bike demand. This paper addresses the problem of cost and time in BSS layout design and proposes a new solution to streamline and facilitate the process of such planning by using spatial embedding methods. Based only on publicly available data from OpenStreetMap, and station layouts from 34 cities in Europe, a method has been developed to divide cities into micro-regions using the Uber H3 discrete global grid system and to indicate regions where it is worth placing a station based on existing systems in different cities using transfer learning. The result of the work is a mechanism to support planners in their decision making when planning a station layout with a choice of reference cities.
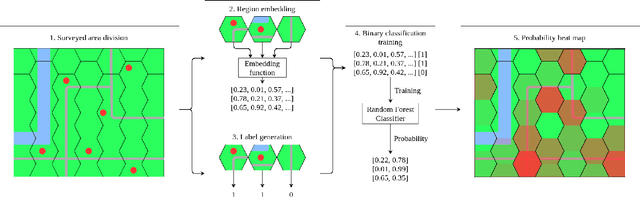
Hex2vec -- Context-Aware Embedding H3 Hexagons with OpenStreetMap Tags
Nov 01, 2021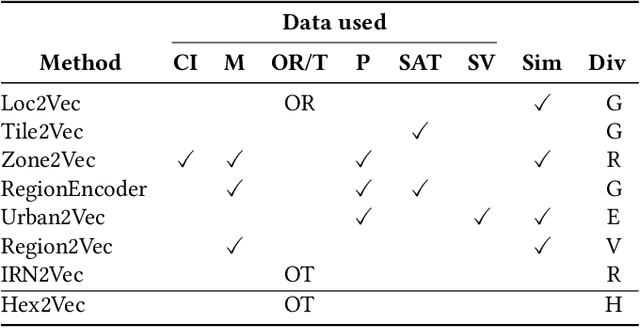
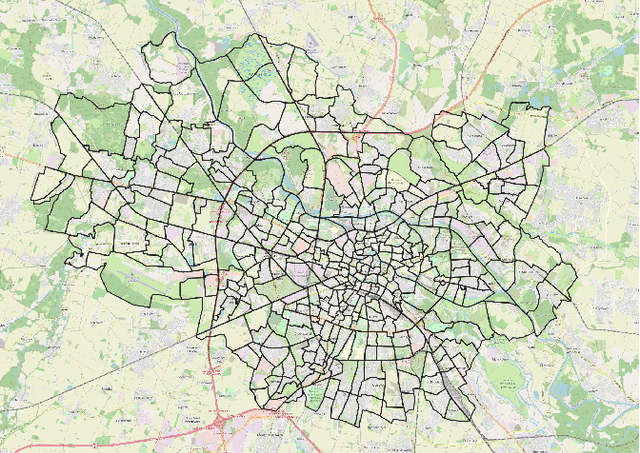
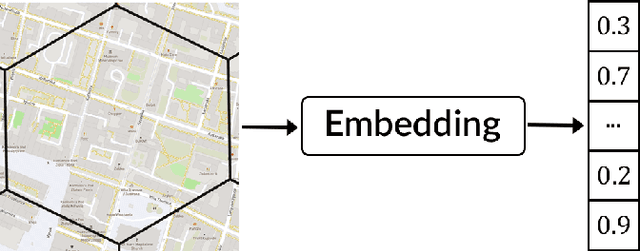
Representation learning of spatial and geographic data is a rapidly developing field which allows for similarity detection between areas and high-quality inference using deep neural networks. Past approaches however concentrated on embedding raster imagery (maps, street or satellite photos), mobility data or road networks. In this paper we propose the first approach to learning vector representations of OpenStreetMap regions with respect to urban functions and land-use in a micro-region grid. We identify a subset of OSM tags related to major characteristics of land-use, building and urban region functions, types of water, green or other natural areas. Through manual verification of tagging quality, we selected 36 cities were for training region representations. Uber's H3 index was used to divide the cities into hexagons, and OSM tags were aggregated for each hexagon. We propose the hex2vec method based on the Skip-gram model with negative sampling. The resulting vector representations showcase semantic structures of the map characteristics, similar to ones found in vector-based language models. We also present insights from region similarity detection in six Polish cities and propose a region typology obtained through agglomerative clustering.
Spatial Data Mining of Public Transport Incidents reported in Social Media
Oct 11, 2021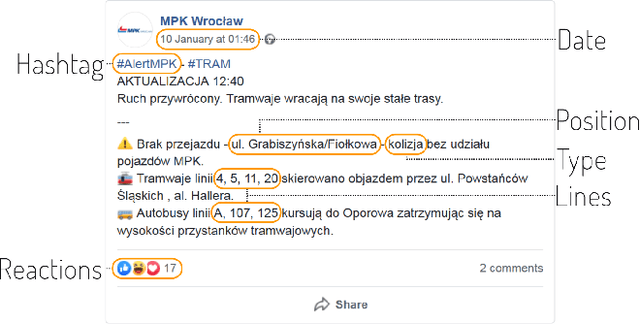
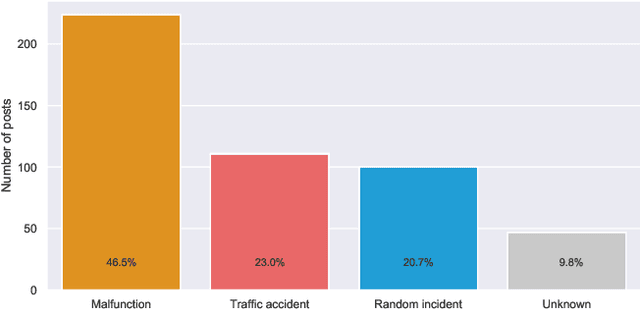
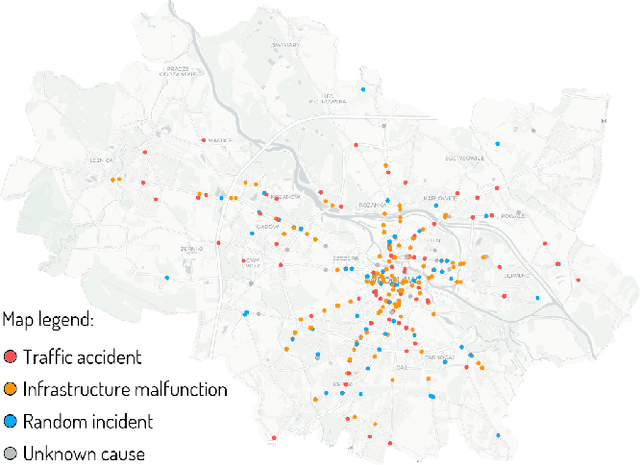
Public transport agencies use social media as an essential tool for communicating mobility incidents to passengers. However, while the short term, day-to-day information about transport phenomena is usually posted in social media with low latency, its availability is short term as the content is rarely made an aggregated form. Social media communication of transport phenomena usually lacks GIS annotations as most social media platforms do not allow attaching non-POI GPS coordinates to posts. As a result, the analysis of transport phenomena information is minimal. We collected three years of social media posts of a polish public transport company with user comments. Through exploration, we infer a six-class transport information typology. We successfully build an information type classifier for social media posts, detect stop names in posts, and relate them to GPS coordinates, obtaining a spatial understanding of long-term aggregated phenomena. We show that our approach enables citizen science and use it to analyze the impact of three years of infrastructure incidents on passenger mobility, and the sentiment and reaction scale towards each of the events. All these results are achieved for Polish, an under-resourced language when it comes to spatial language understanding, especially in social media contexts. To improve the situation, we released two of our annotated data sets: social media posts with incident type labels and matched stop names and social media comments with the annotated sentiment. We also opensource the experimental codebase.