 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved DeepFake Detection Using Whisper Features
Jun 02, 2023



With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
Defense Against Adversarial Attacks on Audio DeepFake Detection
Dec 30, 2022



Audio DeepFakes are artificially generated utterances created using deep learning methods with the main aim to fool the listeners, most of such audio is highly convincing. Their quality is sufficient to pose a serious threat in terms of security and privacy, such as the reliability of news or defamation. To prevent the threats, multiple neural networks-based methods to detect generated speech have been proposed. In this work, we cover the topic of adversarial attacks, which decrease the performance of detectors by adding superficial (difficult to spot by a human) changes to input data. Our contribution contains evaluating the robustness of 3 detection architectures against adversarial attacks in two scenarios (white-box and using transferability mechanism) and enhancing it later by the use of adversarial training performed by our novel adaptive training method.
SpecRNet: Towards Faster and More Accessible Audio DeepFake Detection
Oct 12, 2022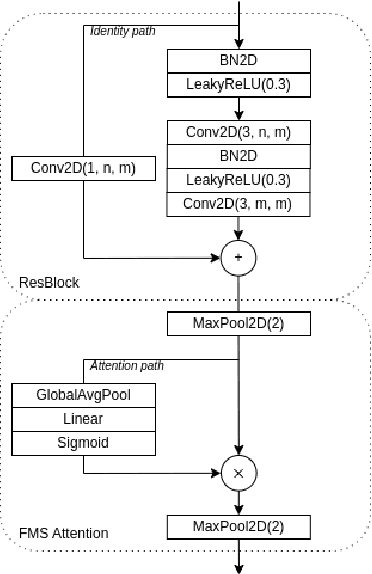
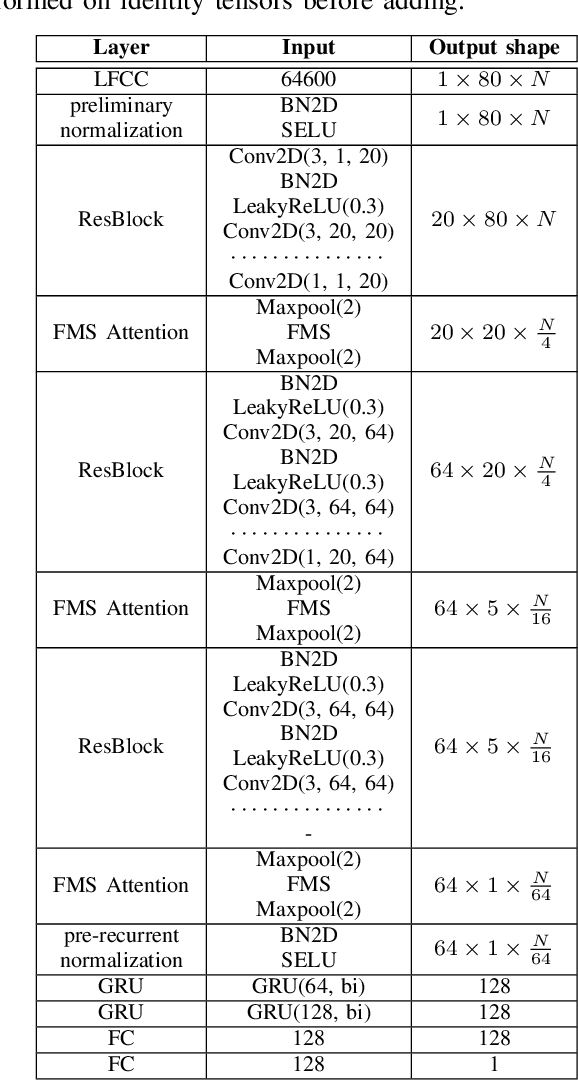
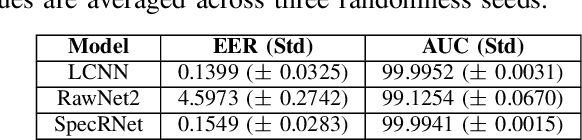
Audio DeepFakes are utterances generated with the use of deep neural networks. They are highly misleading and pose a threat due to use in fake news, impersonation, or extortion. In this work, we focus on increasing accessibility to the audio DeepFake detection methods by providing SpecRNet, a neural network architecture characterized by a quick inference time and low computational requirements. Our benchmark shows that SpecRNet, requiring up to about 40% less time to process an audio sample, provides performance comparable to LCNN architecture - one of the best audio DeepFake detection models. Such a method can not only be used by online multimedia services to verify a large bulk of content uploaded daily but also, thanks to its low requirements, by average citizens to evaluate materials on their devices. In addition, we provide benchmarks in three unique settings that confirm the correctness of our model. They reflect scenarios of low-resource datasets, detection on short utterances and limited attacks benchmark in which we take a closer look at the influence of particular attacks on given architectures.
Attack Agnostic Dataset: Towards Generalization and Stabilization of Audio DeepFake Detection
Jun 27, 2022
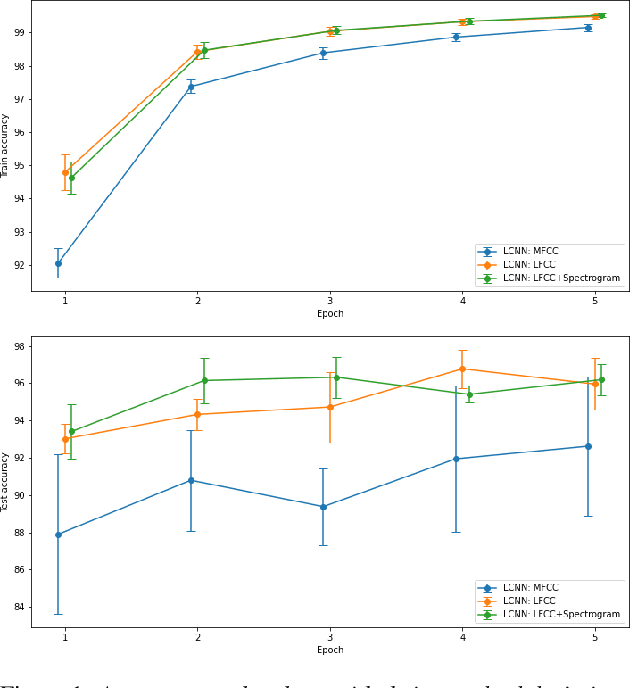


Audio DeepFakes allow the creation of high-quality, convincing utterances and therefore pose a threat due to its potential applications such as impersonation or fake news. Methods for detecting these manipulations should be characterized by good generalization and stability leading to robustness against attacks conducted with techniques that are not explicitly included in the training. In this work, we introduce Attack Agnostic Dataset - a combination of two audio DeepFakes and one anti-spoofing datasets that, thanks to the disjoint use of attacks, can lead to better generalization of detection methods. We present a thorough analysis of current DeepFake detection methods and consider different audio features (front-ends). In addition, we propose a model based on LCNN with LFCC and mel-spectrogram front-end, which not only is characterized by a good generalization and stability results but also shows improvement over LFCC-based mode - we decrease standard deviation on all folds and EER in two folds by up to 5%.
End-to-End Unsupervised Document Image Blind Denoising
May 19, 2021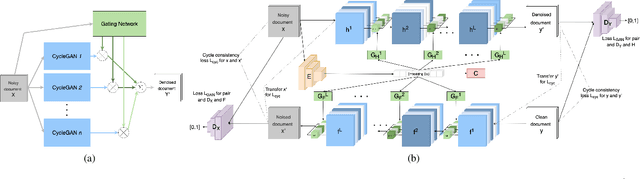

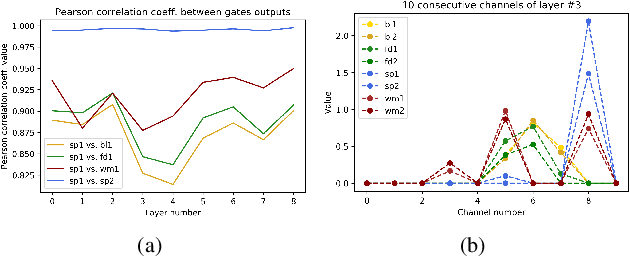
Removing noise from scanned pages is a vital step before their submission to optical character recognition (OCR) system. Most available image denoising methods are supervised where the pairs of noisy/clean pages are required. However, this assumption is rarely met in real settings. Besides, there is no single model that can remove various noise types from documents. Here, we propose a unified end-to-end unsupervised deep learning model, for the first time, that can effectively remove multiple types of noise, including salt \& pepper noise, blurred and/or faded text, as well as watermarks from documents at various levels of intensity. We demonstrate that the proposed model significantly improves the quality of scanned images and the OCR of the pages on several test datasets.
Robust watermarking with double detector-discriminator approach
Jun 06, 2020
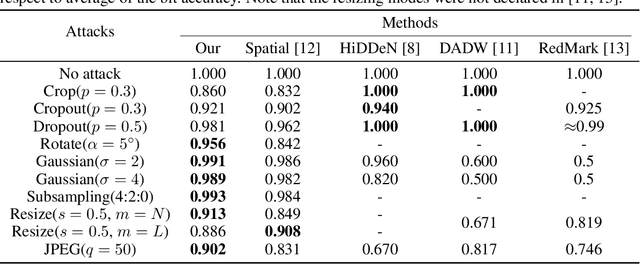

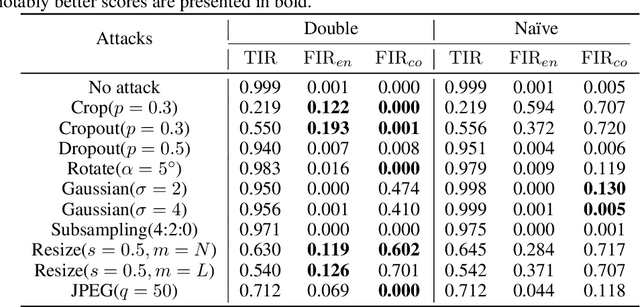
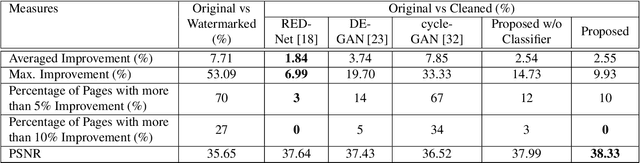
In this paper we present a novel deep framework for a watermarking - a technique of embedding a transparent message into an image in a way that allows retrieving the message from a (perturbed) copy, so that copyright infringement can be tracked. For this technique, it is essential to extract the information from the image even after imposing some digital processing operations on it. Our framework outperforms recent methods in the context of robustness against not only spectrum of attacks (e.g. rotation, resizing, Gaussian smoothing) but also against compression, especially JPEG. The bit accuracy of our method is at least 0.86 for all types of distortions. We also achieved 0.90 bit accuracy for JPEG while recent methods provided at most 0.83. Our method retains high transparency and capacity as well. Moreover, we present our double detector-discriminator approach - a scheme to detect and discriminate if the image contains the embedded message or not, which is crucial for real-life watermarking systems and up to now was not investigated using neural networks. With this, we design a testing formula to validate our extended approach and compared it with a common procedure. We also present an alternative method of balancing between image quality and robustness on attacks which is easily applicable to the framework.