 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Audio Prototype EXplanations for Classification Tasks
May 11, 2026Explainable AI (XAI) has achieved remarkable success in image classification, yet the audio domain lacks equally mature solutions. Current methods apply vision-based attribution techniques to spectrograms, overlooking fundamental differences between visual and acoustic signals. While prototype reasoning is promising, acoustic similarity remains multidimensional. We introduce APEX (Audio Prototype EXplanations), a post-hoc framework for interpreting pre-trained audio classifiers. Crucially, APEX requires no fine-tuning of the original backbone and strictly preserves output invariance. APEX disentangles explanations into four perspectives: Square-based prototypes to localize transient events, Time-based for temporal patterns, Frequency-based highlighting spectral bands, and Time-Frequency-based integrating both. This yields intuitive, example-based explanations that respect acoustic properties, providing greater semantic clarity than standard gradient-based methods.
Enhancing Speaker Verification with Whispered Speech via Post-Processing
Apr 22, 2026Speaker verification is a task of confirming an individual's identity through the analysis of their voice. Whispered speech differs from phonated speech in acoustic characteristics, which degrades the performance of speaker verification systems in real-life scenarios, including avoiding fully phonated speech to protect privacy, disrupt others, or when the lack of full vocalization is dictated by a disease. In this paper we propose a model with a training recipe to obtain more robust representations against whispered speech hindrances. The proposed system employs an encoder--decoder structure built atop a fine-tuned speaker verification backbone, optimized jointly using cosine similarity--based classification and triplet loss. We gain relative improvement of 22.26\% compared to the baseline (baseline 6.77\% vs ours 5.27\%) in normal vs whispered speech trials, achieving AUC of 98.16\%. In tests comparing whispered to whispered, our model attains an EER of 1.88\% with AUC equal to 99.73\%, which represents a 15\% relative enhancement over the prior leading ReDimNet-B2. We also offer a summary of the most popular and state-of-the-art speaker verification models in terms of their performance with whispered speech. Additionally, we evaluate how these models perform under noisy audios, obtaining that generally the same relative level of noise degrades the performance of speaker verification more significantly on whispered speech than on normal speech.
XSPLAIN: XAI-enabling Splat-based Prototype Learning for Attribute-aware INterpretability
Feb 10, 20263D Gaussian Splatting (3DGS) has rapidly become a standard for high-fidelity 3D reconstruction, yet its adoption in multiple critical domains is hindered by the lack of interpretability of the generation models as well as classification of the Splats. While explainability methods exist for other 3D representations, like point clouds, they typically rely on ambiguous saliency maps that fail to capture the volumetric coherence of Gaussian primitives. We introduce XSPLAIN, the first ante-hoc, prototype-based interpretability framework designed specifically for 3DGS classification. Our approach leverages a voxel-aggregated PointNet backbone and a novel, invertible orthogonal transformation that disentangles feature channels for interpretability while strictly preserving the original decision boundaries. Explanations are grounded in representative training examples, enabling intuitive ``this looks like that'' reasoning without any degradation in classification performance. A rigorous user study (N=51) demonstrates a decisive preference for our approach: participants selected XSPLAIN explanations 48.4\% of the time as the best, significantly outperforming baselines $(p<0.001)$, showing that XSPLAIN provides transparency and user trust. The source code for this work is available at: https://github.com/Solvro/ml-splat-xai
A Hypernetwork-Based Approach to KAN Representation of Audio Signals
Mar 04, 2025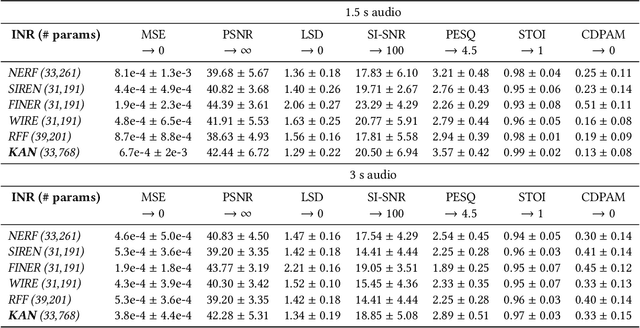
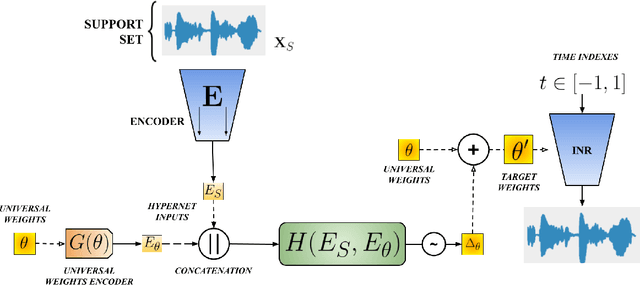


Implicit neural representations (INR) have gained prominence for efficiently encoding multimedia data, yet their applications in audio signals remain limited. This study introduces the Kolmogorov-Arnold Network (KAN), a novel architecture using learnable activation functions, as an effective INR model for audio representation. KAN demonstrates superior perceptual performance over previous INRs, achieving the lowest Log-SpectralDistance of 1.29 and the highest Perceptual Evaluation of Speech Quality of 3.57 for 1.5 s audio. To extend KAN's utility, we propose FewSound, a hypernetwork-based architecture that enhances INR parameter updates. FewSound outperforms the state-of-the-art HyperSound, with a 33.3% improvement in MSE and 60.87% in SI-SNR. These results show KAN as a robust and adaptable audio representation with the potential for scalability and integration into various hypernetwork frameworks. The source code can be accessed at https://github.com/gmum/fewsound.git.
Counteracting temporal attacks in Video Copy Detection
Jan 19, 2025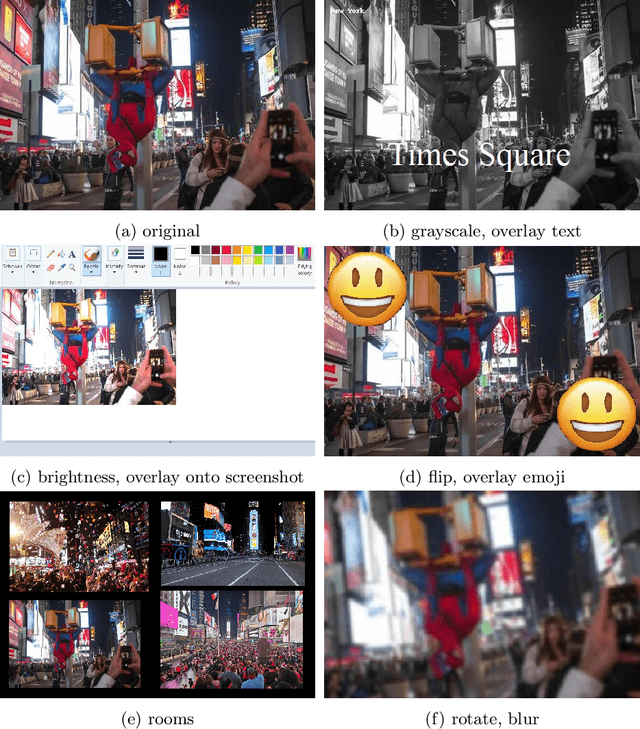
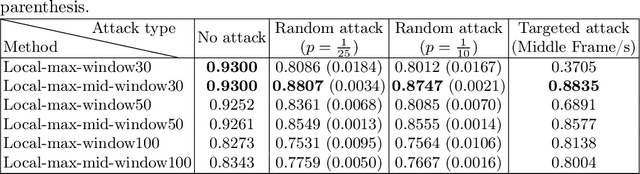
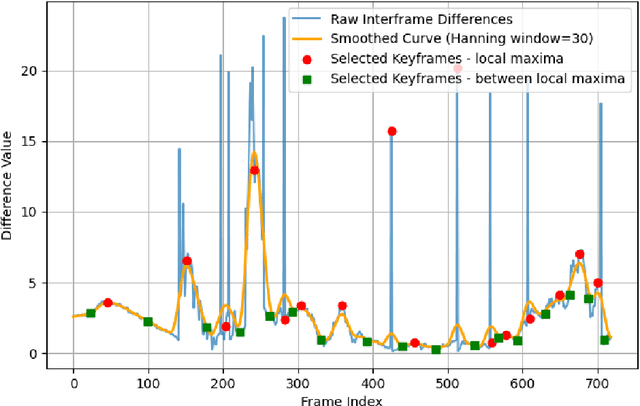

Video Copy Detection (VCD) plays a crucial role in copyright protection and content verification by identifying duplicates and near-duplicates in large-scale video databases. The META AI Challenge on video copy detection provided a benchmark for evaluating state-of-the-art methods, with the Dual-level detection approach emerging as a winning solution. This method integrates Video Editing Detection and Frame Scene Detection to handle adversarial transformations and large datasets efficiently. However, our analysis reveals significant limitations in the VED component, particularly in its ability to handle exact copies. Moreover, Dual-level detection shows vulnerability to temporal attacks. To address it, we propose an improved frame selection strategy based on local maxima of interframe differences, which enhances robustness against adversarial temporal modifications while significantly reducing computational overhead. Our method achieves an increase of 1.4 to 5.8 times in efficiency over the standard 1 FPS approach. Compared to Dual-level detection method, our approach maintains comparable micro-average precision ($\mu$AP) while also demonstrating improved robustness against temporal attacks. Given 56\% reduced representation size and the inference time of more than 2 times faster, our approach is more suitable to real-world resource restriction.
Are audio DeepFake detection models polyglots?
Dec 23, 2024



Since the majority of audio DeepFake (DF) detection methods are trained on English-centric datasets, their applicability to non-English languages remains largely unexplored. In this work, we present a benchmark for the multilingual audio DF detection challenge by evaluating various adaptation strategies. Our experiments focus on analyzing models trained on English benchmark datasets, as well as intra-linguistic (same-language) and cross-linguistic adaptation approaches. Our results indicate considerable variations in detection efficacy, highlighting the difficulties of multilingual settings. We show that limiting the dataset to English negatively impacts the efficacy, while stressing the importance of the data in the target language.
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset
Jan 17, 2024



Text-to-Speech (TTS) technology brings significant advantages, such as giving a voice to those with speech impairments, but also enables audio deepfakes and spoofs. The former mislead individuals and may propagate misinformation, while the latter undermine voice biometric security systems. AI-based detection can help to address these challenges by automatically differentiating between genuine and fabricated voice recordings. However, these models are only as good as their training data, which currently is severely limited due to an overwhelming concentration on English and Chinese audio in anti-spoofing databases, thus restricting its worldwide effectiveness. In response, this paper presents the Multi-Language Audio Anti-Spoof Dataset (MLAAD), created using 52 TTS models, comprising 19 different architectures, to generate 160.1 hours of synthetic voice in 23 different languages. We train and evaluate three state-of-the-art deepfake detection models with MLAAD, and observe that MLAAD demonstrates superior performance over comparable datasets like InTheWild or FakeOrReal when used as a training resource. Furthermore, in comparison with the renowned ASVspoof 2019 dataset, MLAAD proves to be a complementary resource. In tests across eight datasets, MLAAD and ASVspoof 2019 alternately outperformed each other, both excelling on four datasets. By publishing MLAAD and making trained models accessible via an interactive webserver , we aim to democratize antispoofing technology, making it accessible beyond the realm of specialists, thus contributing to global efforts against audio spoofing and deepfakes.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023



With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
Defense Against Adversarial Attacks on Audio DeepFake Detection
Dec 30, 2022



Audio DeepFakes are artificially generated utterances created using deep learning methods with the main aim to fool the listeners, most of such audio is highly convincing. Their quality is sufficient to pose a serious threat in terms of security and privacy, such as the reliability of news or defamation. To prevent the threats, multiple neural networks-based methods to detect generated speech have been proposed. In this work, we cover the topic of adversarial attacks, which decrease the performance of detectors by adding superficial (difficult to spot by a human) changes to input data. Our contribution contains evaluating the robustness of 3 detection architectures against adversarial attacks in two scenarios (white-box and using transferability mechanism) and enhancing it later by the use of adversarial training performed by our novel adaptive training method.
SpecRNet: Towards Faster and More Accessible Audio DeepFake Detection
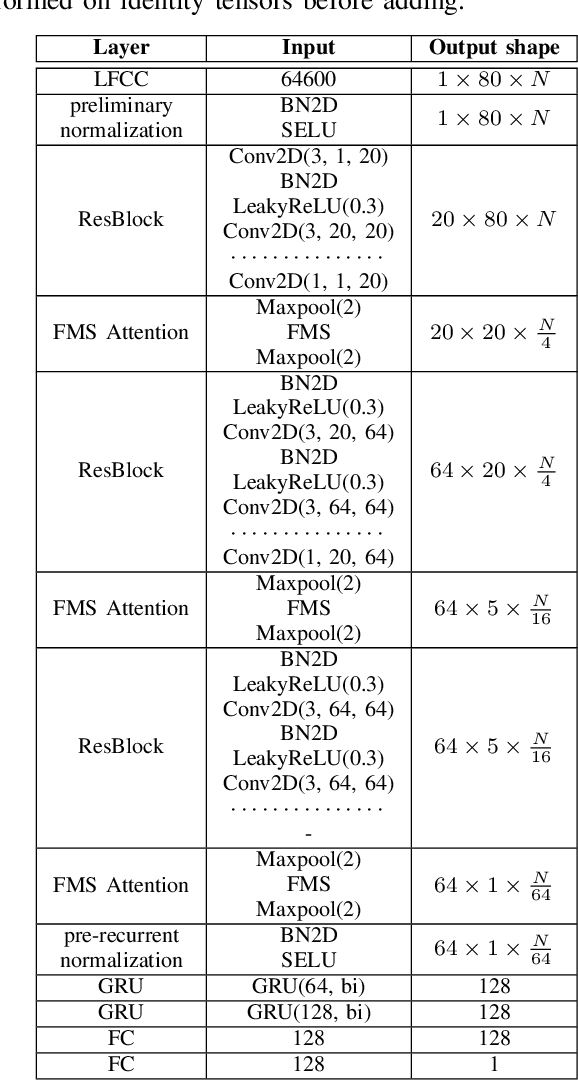
Oct 12, 2022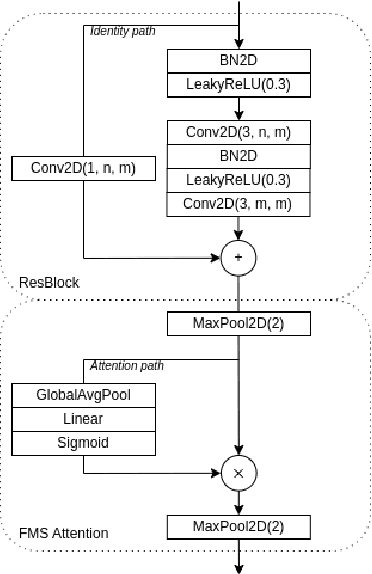
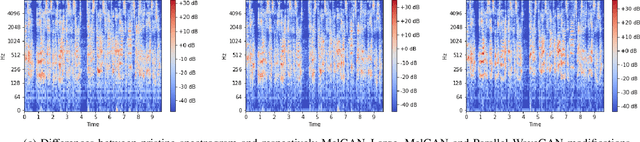
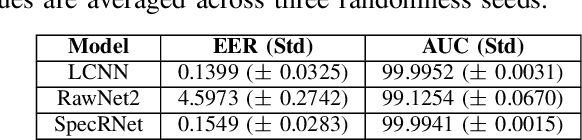
Audio DeepFakes are utterances generated with the use of deep neural networks. They are highly misleading and pose a threat due to use in fake news, impersonation, or extortion. In this work, we focus on increasing accessibility to the audio DeepFake detection methods by providing SpecRNet, a neural network architecture characterized by a quick inference time and low computational requirements. Our benchmark shows that SpecRNet, requiring up to about 40% less time to process an audio sample, provides performance comparable to LCNN architecture - one of the best audio DeepFake detection models. Such a method can not only be used by online multimedia services to verify a large bulk of content uploaded daily but also, thanks to its low requirements, by average citizens to evaluate materials on their devices. In addition, we provide benchmarks in three unique settings that confirm the correctness of our model. They reflect scenarios of low-resource datasets, detection on short utterances and limited attacks benchmark in which we take a closer look at the influence of particular attacks on given architectures.