 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecRNet: Towards Faster and More Accessible Audio DeepFake Detection
Paper and Code
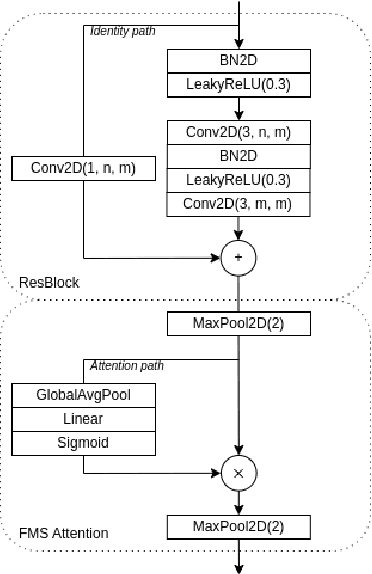
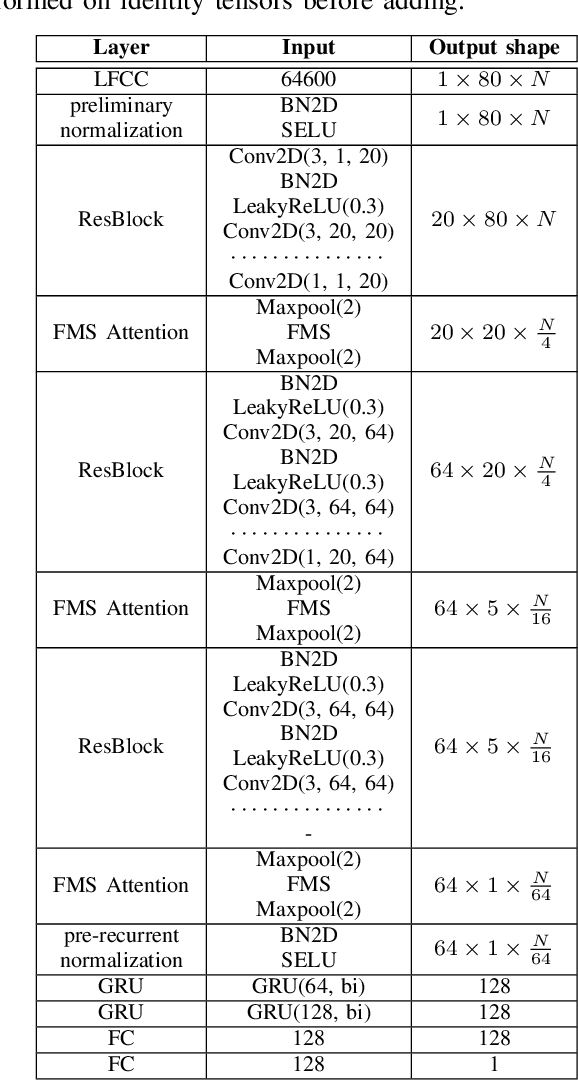
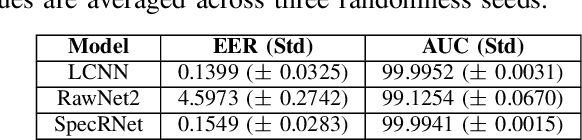
Audio DeepFakes are utterances generated with the use of deep neural networks. They are highly misleading and pose a threat due to use in fake news, impersonation, or extortion. In this work, we focus on increasing accessibility to the audio DeepFake detection methods by providing SpecRNet, a neural network architecture characterized by a quick inference time and low computational requirements. Our benchmark shows that SpecRNet, requiring up to about 40% less time to process an audio sample, provides performance comparable to LCNN architecture - one of the best audio DeepFake detection models. Such a method can not only be used by online multimedia services to verify a large bulk of content uploaded daily but also, thanks to its low requirements, by average citizens to evaluate materials on their devices. In addition, we provide benchmarks in three unique settings that confirm the correctness of our model. They reflect scenarios of low-resource datasets, detection on short utterances and limited attacks benchmark in which we take a closer look at the influence of particular attacks on given architectures.