 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagarela - A Portuguese speech dataset from podcasts
Mar 16, 2026Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours of podcast audio, specifically curated for training automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably, its scale rivals English's GigaSpeech (10kh), enabling state-of-the-art Portuguese models. To ensure data quality, the corpus was subjected to an audio pre-processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were previously trained on high-fidelity transcriptions generated by proprietary APIs, ensuring a high level of initial accuracy. Finally, to validate the effectiveness of this new resource, we present ASR and TTS models trained exclusively on our dataset and evaluate their performance, demonstrating its potential to drive the development of more robust and natural speech technologies for Portuguese. The dataset is released publicly, available at https://freds0.github.io/TAGARELA/, to foster the development of robust speech technologies.
The Impact of Prosodic Segmentation on Speech Synthesis of Spontaneous Speech
Nov 06, 2025Spontaneous speech presents several challenges for speech synthesis, particularly in capturing the natural flow of conversation, including turn-taking, pauses, and disfluencies. Although speech synthesis systems have made significant progress in generating natural and intelligible speech, primarily through architectures that implicitly model prosodic features such as pitch, intensity, and duration, the construction of datasets with explicit prosodic segmentation and their impact on spontaneous speech synthesis remains largely unexplored. This paper evaluates the effects of manual and automatic prosodic segmentation annotations in Brazilian Portuguese on the quality of speech synthesized by a non-autoregressive model, FastSpeech 2. Experimental results show that training with prosodic segmentation produced slightly more intelligible and acoustically natural speech. While automatic segmentation tends to create more regular segments, manual prosodic segmentation introduces greater variability, which contributes to more natural prosody. Analysis of neutral declarative utterances showed that both training approaches reproduced the expected nuclear accent pattern, but the prosodic model aligned more closely with natural pre-nuclear contours. To support reproducibility and future research, all datasets, source codes, and trained models are publicly available under the CC BY-NC-ND 4.0 license.
HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
Jun 04, 2025This paper introduces HiFiTTS-2, a large-scale speech dataset designed for high-bandwidth speech synthesis. The dataset is derived from LibriVox audiobooks, and contains approximately 36.7k hours of English speech for 22.05 kHz training, and 31.7k hours for 44.1 kHz training. We present our data processing pipeline, including bandwidth estimation, segmentation, text preprocessing, and multi-speaker detection. The dataset is accompanied by detailed utterance and audiobook metadata generated by our pipeline, enabling researchers to apply data quality filters to adapt the dataset to various use cases. Experimental results demonstrate that our data pipeline and resulting dataset can facilitate the training of high-quality, zero-shot text-to-speech (TTS) models at high bandwidths.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025
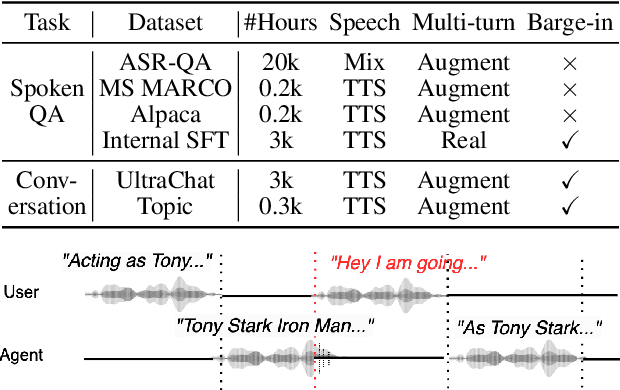
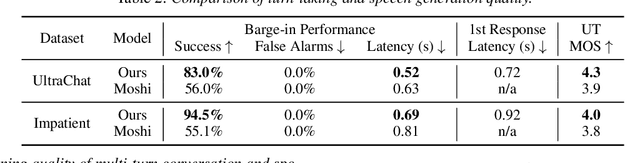

Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Feb 07, 2025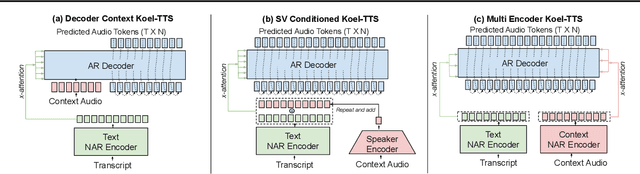
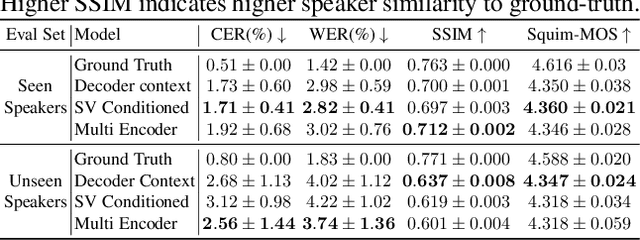
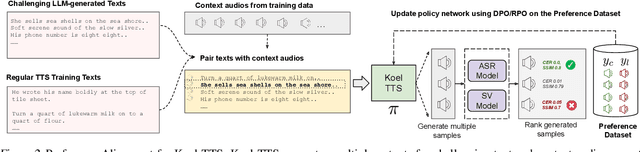
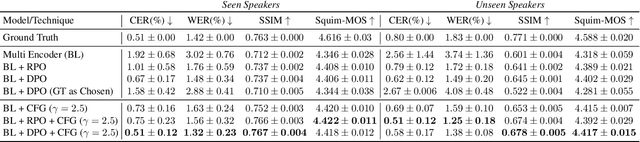
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
FreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Sep 18, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Jun 07, 2024Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset
Jan 17, 2024



Text-to-Speech (TTS) technology brings significant advantages, such as giving a voice to those with speech impairments, but also enables audio deepfakes and spoofs. The former mislead individuals and may propagate misinformation, while the latter undermine voice biometric security systems. AI-based detection can help to address these challenges by automatically differentiating between genuine and fabricated voice recordings. However, these models are only as good as their training data, which currently is severely limited due to an overwhelming concentration on English and Chinese audio in anti-spoofing databases, thus restricting its worldwide effectiveness. In response, this paper presents the Multi-Language Audio Anti-Spoof Dataset (MLAAD), created using 52 TTS models, comprising 19 different architectures, to generate 160.1 hours of synthetic voice in 23 different languages. We train and evaluate three state-of-the-art deepfake detection models with MLAAD, and observe that MLAAD demonstrates superior performance over comparable datasets like InTheWild or FakeOrReal when used as a training resource. Furthermore, in comparison with the renowned ASVspoof 2019 dataset, MLAAD proves to be a complementary resource. In tests across eight datasets, MLAAD and ASVspoof 2019 alternately outperformed each other, both excelling on four datasets. By publishing MLAAD and making trained models accessible via an interactive webserver , we aim to democratize antispoofing technology, making it accessible beyond the realm of specialists, thus contributing to global efforts against audio spoofing and deepfakes.
Evaluation of Speech Representations for MOS prediction
Jun 16, 2023



In this paper, we evaluate feature extraction models for predicting speech quality. We also propose a model architecture to compare embeddings of supervised learning and self-supervised learning models with embeddings of speaker verification models to predict the metric MOS. Our experiments were performed on the VCC2018 dataset and a Brazilian-Portuguese dataset called BRSpeechMOS, which was created for this work. The results show that the Whisper model is appropriate in all scenarios: with both the VCC2018 and BRSpeech- MOS datasets. Among the supervised and self-supervised learning models using BRSpeechMOS, Whisper-Small achieved the best linear correlation of 0.6980, and the speaker verification model, SpeakerNet, had linear correlation of 0.6963. Using VCC2018, the best supervised and self-supervised learning model, Whisper-Large, achieved linear correlation of 0.7274, and the best model speaker verification, TitaNet, achieved a linear correlation of 0.6933. Although the results of the speaker verification models are slightly lower, the SpeakerNet model has only 5M parameters, making it suitable for real-time applications, and the TitaNet model produces an embedding of size 192, the smallest among all the evaluated models. The experiment results are reproducible with publicly available source-code1 .