 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
Jun 16, 2026Neural Text-to-Speech (TTS) systems achieve remarkable quality on short utterances but long-form speech generation shows prosodic drift, speaker inconsistencies and sentence boundary artifacts. Existing approaches either compress sequences, increase context length or naively concatenate independently synthesized chunks. We present an inference-time approach called MagpieTTS-LF that enables MagpieTTS to produce coherent long-form speech without model retraining. Our method introduces three key innovations: (1) soft attention priors to guide monotonic alignment while preserving past and future context; (2) a stateful inference algorithm that maintains context across sentence chunks, ensuring prosodic continuity; (3) history-aware text encoding that uses past text for discourse-level prosodic planning. Experiments on long texts show significant improvements in long-range intelligibility, prosodic coherence, speaker consistency, and boundary naturalness compared to other baselines.
HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
Jun 04, 2025This paper introduces HiFiTTS-2, a large-scale speech dataset designed for high-bandwidth speech synthesis. The dataset is derived from LibriVox audiobooks, and contains approximately 36.7k hours of English speech for 22.05 kHz training, and 31.7k hours for 44.1 kHz training. We present our data processing pipeline, including bandwidth estimation, segmentation, text preprocessing, and multi-speaker detection. The dataset is accompanied by detailed utterance and audiobook metadata generated by our pipeline, enabling researchers to apply data quality filters to adapt the dataset to various use cases. Experimental results demonstrate that our data pipeline and resulting dataset can facilitate the training of high-quality, zero-shot text-to-speech (TTS) models at high bandwidths.
Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Sep 18, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.
Codec-ASR: Training Performant Automatic Speech Recognition Systems with Discrete Speech Representations
Jul 03, 2024
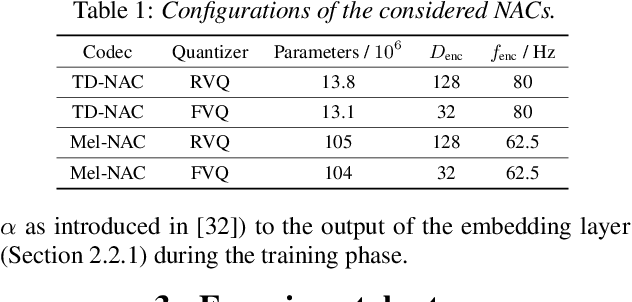

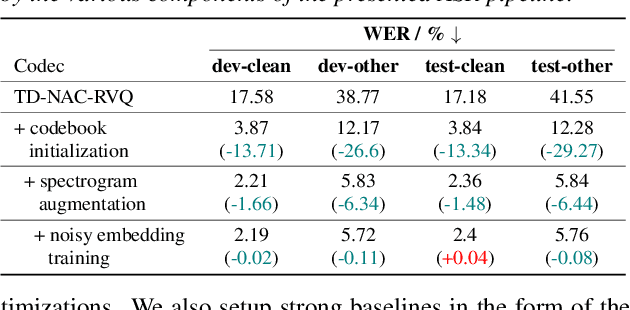
Discrete speech representations have garnered recent attention for their efficacy in training transformer-based models for various speech-related tasks such as automatic speech recognition (ASR), translation, speaker verification, and joint speech-text foundational models. In this work, we present a comprehensive analysis on building ASR systems with discrete codes. We investigate different methods for codec training such as quantization schemes and time-domain vs spectral feature encodings. We further explore ASR training techniques aimed at enhancing performance, training efficiency, and noise robustness. Drawing upon our findings, we introduce a codec ASR pipeline that outperforms Encodec at similar bit-rate. Remarkably, it also surpasses the state-of-the-art results achieved by strong self-supervised models on the 143 languages ML-SUPERB benchmark despite being smaller in size and pretrained on significantly less data.
Spectral Codecs: Spectrogram-Based Audio Codecs for High Quality Speech Synthesis
Jun 07, 2024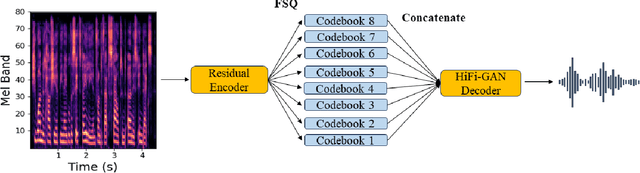

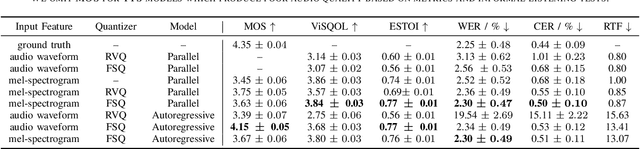
Historically, most speech models in machine-learning have used the mel-spectrogram as a speech representation. Recently, discrete audio tokens produced by neural audio codecs have become a popular alternate speech representation for speech synthesis tasks such as text-to-speech (TTS). However, the data distribution produced by such codecs is too complex for some TTS models to predict, hence requiring large autoregressive models to get reasonable quality. Typical audio codecs compress and reconstruct the time-domain audio signal. We propose a spectral codec which compresses the mel-spectrogram and reconstructs the time-domain audio signal. A study of objective audio quality metrics suggests that our spectral codec has comparable perceptual quality to equivalent audio codecs. Furthermore, non-autoregressive TTS models trained with the proposed spectral codec generate audio with significantly higher quality than when trained with mel-spectrograms or audio codecs.
Improving fairness in speaker verification via Group-adapted Fusion Network
Feb 23, 2022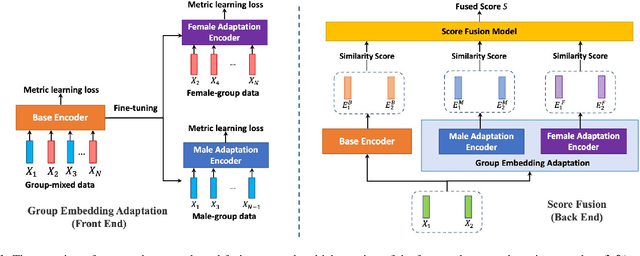
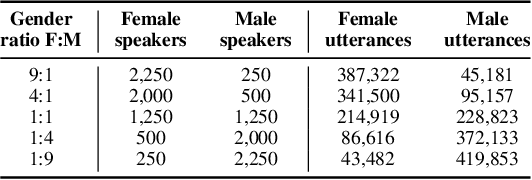

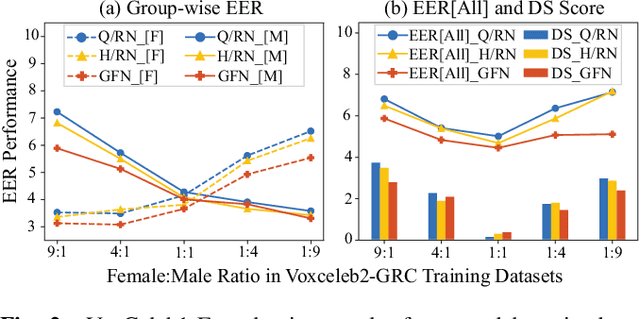
Modern speaker verification models use deep neural networks to encode utterance audio into discriminative embedding vectors. During the training process, these networks are typically optimized to differentiate arbitrary speakers. This learning process biases the learning of fine voice characteristics towards dominant demographic groups, which can lead to an unfair performance disparity across different groups. This is observed especially with underrepresented demographic groups sharing similar voice characteristics. In this work, we investigate the fairness of speaker verification models on controlled datasets with imbalanced gender distributions, providing direct evidence that model performance suffers for underrepresented groups. To mitigate this disparity we propose the group-adapted fusion network (GFN) architecture, a modular architecture based on group embedding adaptation and score fusion. We show that our method alleviates model unfairness by improving speaker verification both overall and for individual groups. Given imbalanced group representation in training, our proposed method achieves overall equal error rate (EER) reduction of 9.6% to 29.0% relative, reduces minority group EER by 13.7% to 18.6%, and results in 20.0% to 25.4% less EER disparity, compared to baselines. The approach is applicable to other types of training data skew in speaker recognition systems.