 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
Jun 04, 2025This paper introduces HiFiTTS-2, a large-scale speech dataset designed for high-bandwidth speech synthesis. The dataset is derived from LibriVox audiobooks, and contains approximately 36.7k hours of English speech for 22.05 kHz training, and 31.7k hours for 44.1 kHz training. We present our data processing pipeline, including bandwidth estimation, segmentation, text preprocessing, and multi-speaker detection. The dataset is accompanied by detailed utterance and audiobook metadata generated by our pipeline, enabling researchers to apply data quality filters to adapt the dataset to various use cases. Experimental results demonstrate that our data pipeline and resulting dataset can facilitate the training of high-quality, zero-shot text-to-speech (TTS) models at high bandwidths.
Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Feb 07, 2025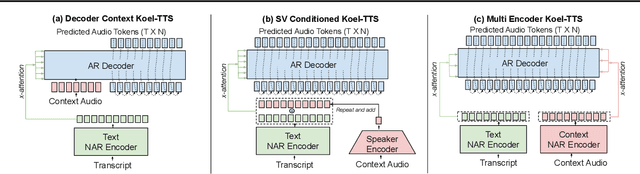
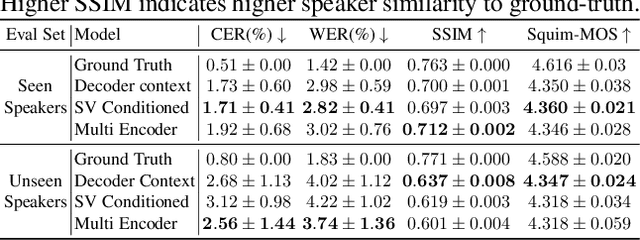
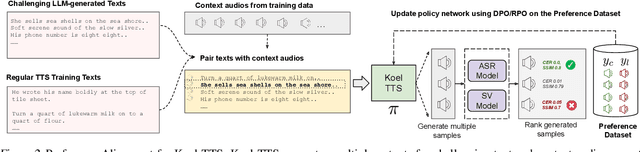
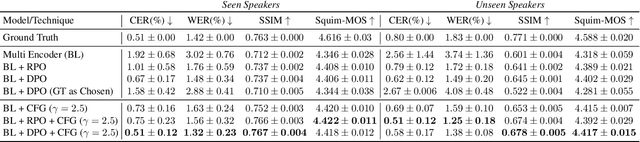
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits
Jan 07, 2025



Neural speech editing advancements have raised concerns about their misuse in spoofing attacks. Traditional partially edited speech corpora primarily focus on cut-and-paste edits, which, while maintaining speaker consistency, often introduce detectable discontinuities. Recent methods, like A\textsuperscript{3}T and Voicebox, improve transitions by leveraging contextual information. To foster spoofing detection research, we introduce the Speech INfilling Edit (SINE) dataset, created with Voicebox. We detailed the process of re-implementing Voicebox training and dataset creation. Subjective evaluations confirm that speech edited using this novel technique is more challenging to detect than conventional cut-and-paste methods. Despite human difficulty, experimental results demonstrate that self-supervised-based detectors can achieve remarkable performance in detection, localization, and generalization across different edit methods. The dataset and related models will be made publicly available.
LLaVA-UHD v2: an MLLM Integrating High-Resolution Feature Pyramid via Hierarchical Window Transformer
Dec 18, 2024In multimodal large language models (MLLMs), vision transformers (ViTs) are widely employed for visual encoding. However, their performance in solving universal MLLM tasks is not satisfactory. We attribute it to a lack of information from diverse visual levels, impeding alignment with the various semantic granularity required for language generation. To address this issue, we present LLaVA-UHD v2, an advanced MLLM centered around a Hierarchical window transformer that enables capturing diverse visual granularity by constructing and integrating a high-resolution feature pyramid. As a vision-language projector, Hiwin transformer comprises two primary modules: (i) an inverse feature pyramid, constructed by a ViT-derived feature up-sampling process utilizing high-frequency details from an image pyramid, and (ii) hierarchical window attention, focusing on a set of key sampling features within cross-scale windows to condense multi-level feature maps. Extensive experiments demonstrate that LLaVA-UHD v2 achieves superior performance over existing MLLMs on popular benchmarks. Notably, our design brings an average boost of 3.7% across 14 benchmarks compared with the baseline method, 9.3% on DocVQA for instance. We make all the data, model checkpoint, and code publicly available to facilitate future research.
NeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Nov 08, 2024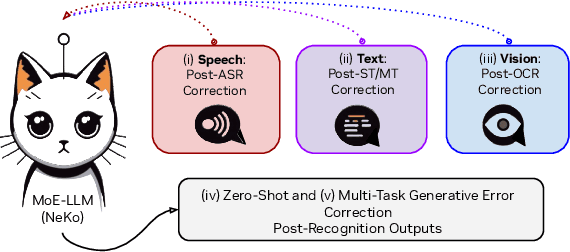
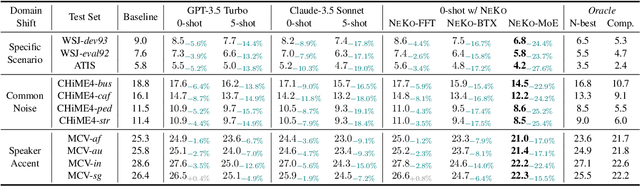
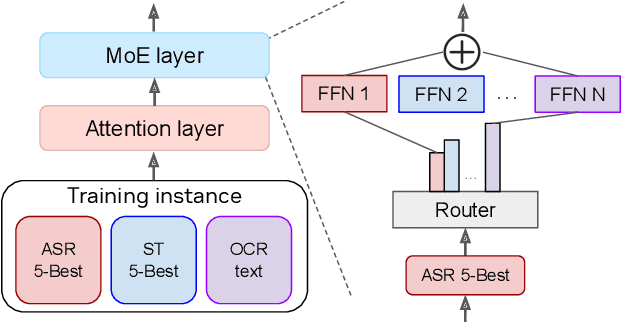
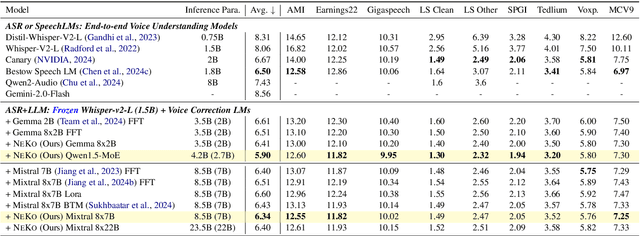
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert'' of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset's tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.
A Unified Framework for Contrastive Learning from a Perspective of Affinity Matrix
Nov 26, 2022In recent years, a variety of contrastive learning based unsupervised visual representation learning methods have been designed and achieved great success in many visual tasks. Generally, these methods can be roughly classified into four categories: (1) standard contrastive methods with an InfoNCE like loss, such as MoCo and SimCLR; (2) non-contrastive methods with only positive pairs, such as BYOL and SimSiam; (3) whitening regularization based methods, such as W-MSE and VICReg; and (4) consistency regularization based methods, such as CO2. In this study, we present a new unified contrastive learning representation framework (named UniCLR) suitable for all the above four kinds of methods from a novel perspective of basic affinity matrix. Moreover, three variants, i.e., SimAffinity, SimWhitening and SimTrace, are presented based on UniCLR. In addition, a simple symmetric loss, as a new consistency regularization term, is proposed based on this framework. By symmetrizing the affinity matrix, we can effectively accelerate the convergence of the training process. Extensive experiments have been conducted to show that (1) the proposed UniCLR framework can achieve superior results on par with and even be better than the state of the art, (2) the proposed symmetric loss can significantly accelerate the convergence of models, and (3) SimTrace can avoid the mode collapse problem by maximizing the trace of a whitened affinity matrix without relying on asymmetry designs or stop-gradients.
NDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022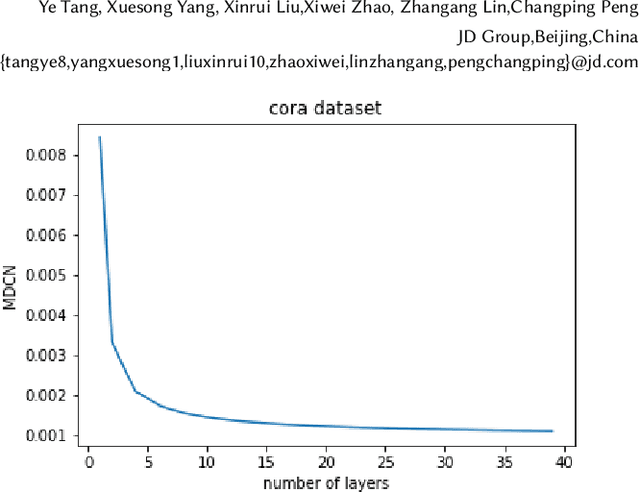
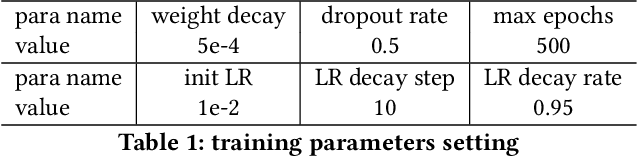
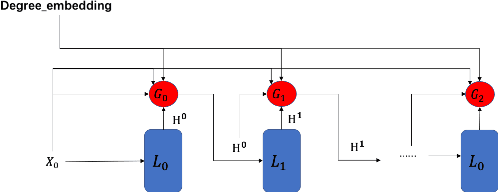
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021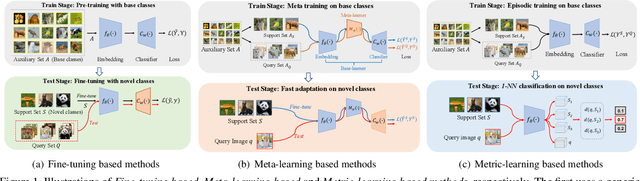
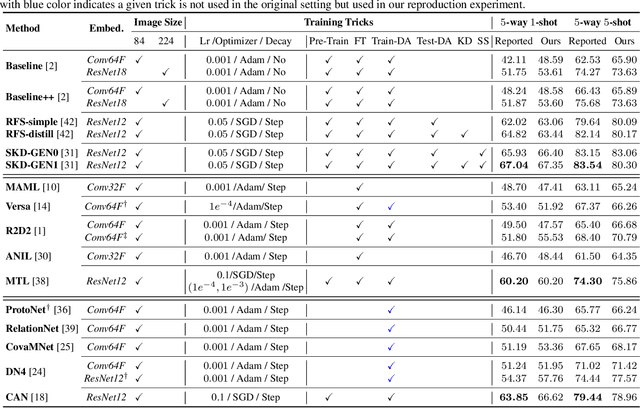
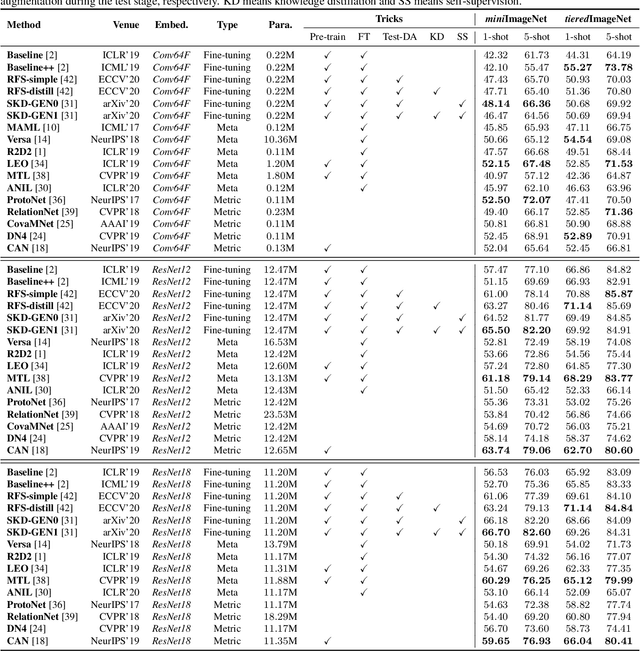
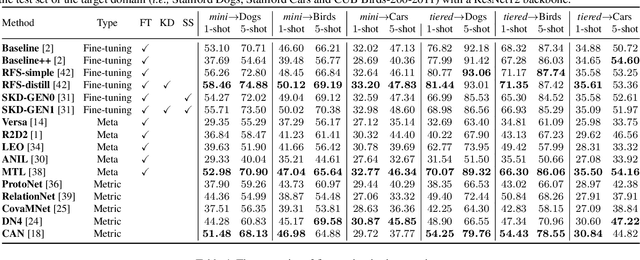
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning
Jul 22, 2021
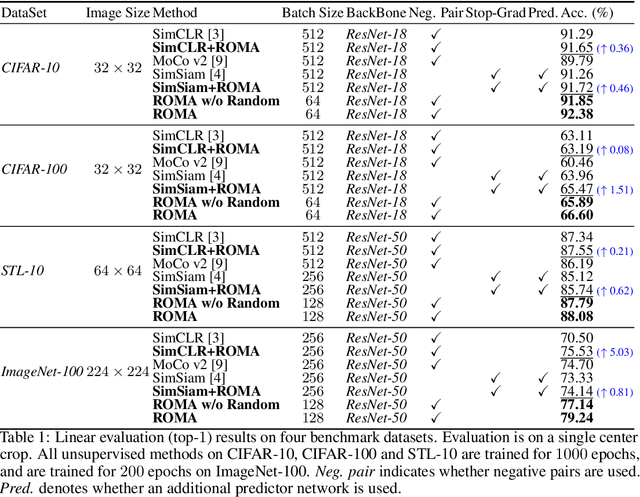
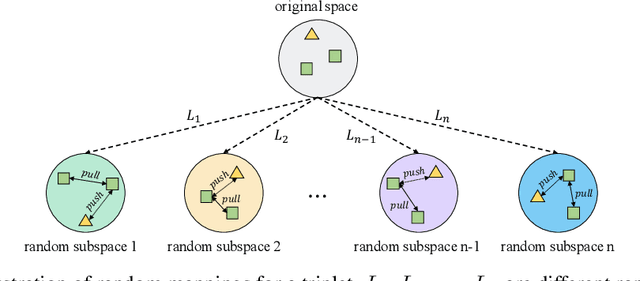

Contrastive self-supervised learning (SSL) has achieved great success in unsupervised visual representation learning by maximizing the similarity between two augmented views of the same image (positive pairs) and simultaneously contrasting other different images (negative pairs). However, this type of methods, such as SimCLR and MoCo, relies heavily on a large number of negative pairs and thus requires either large batches or memory banks. In contrast, some recent non-contrastive SSL methods, such as BYOL and SimSiam, attempt to discard negative pairs by introducing asymmetry and show remarkable performance. Unfortunately, to avoid collapsed solutions caused by not using negative pairs, these methods require sophisticated asymmetry designs. In this paper, we argue that negative pairs are still necessary but one is sufficient, i.e., triplet is all you need. A simple triplet-based loss can achieve surprisingly good performance without requiring large batches or asymmetry. Moreover, we observe that unsupervised visual representation learning can gain significantly from randomness. Based on this observation, we propose a simple plug-in RandOm MApping (ROMA) strategy by randomly mapping samples into other spaces and enforcing these randomly projected samples to satisfy the same correlation requirement. The proposed ROMA strategy not only achieves the state-of-the-art performance in conjunction with the triplet-based loss, but also can further effectively boost other SSL methods.