 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.
Cross-utterance ASR Rescoring with Graph-based Label Propagation
Mar 27, 2023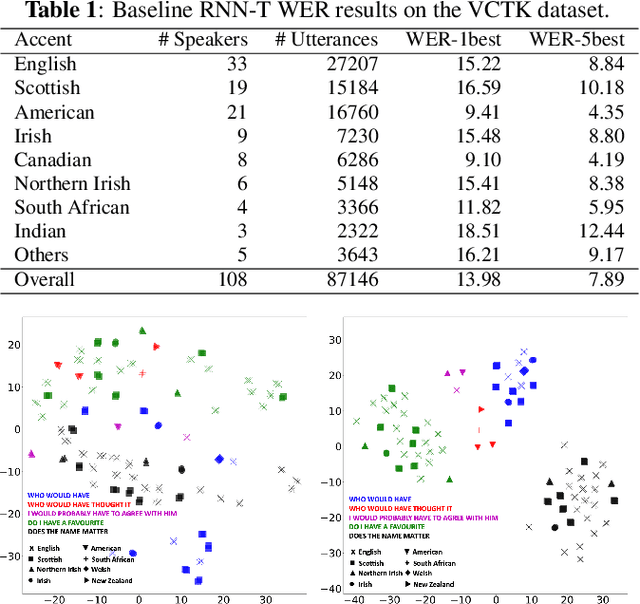
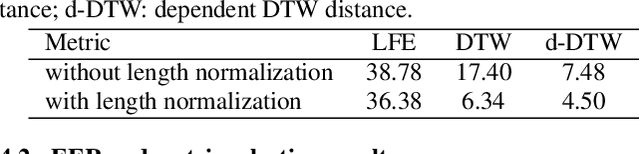
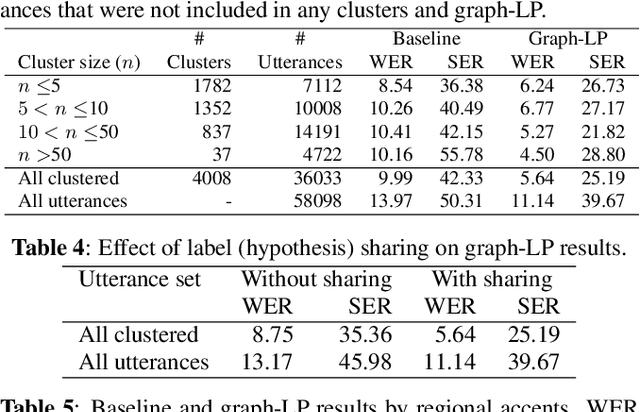
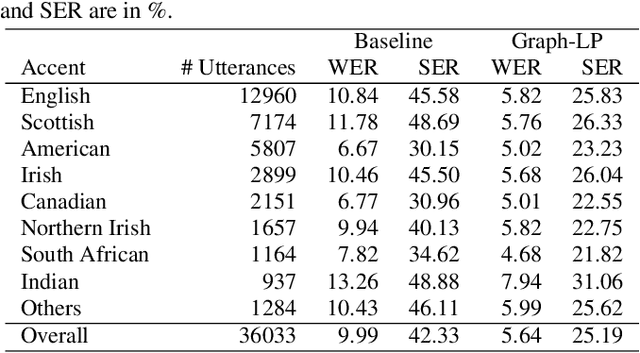
We propose a novel approach for ASR N-best hypothesis rescoring with graph-based label propagation by leveraging cross-utterance acoustic similarity. In contrast to conventional neural language model (LM) based ASR rescoring/reranking models, our approach focuses on acoustic information and conducts the rescoring collaboratively among utterances, instead of individually. Experiments on the VCTK dataset demonstrate that our approach consistently improves ASR performance, as well as fairness across speaker groups with different accents. Our approach provides a low-cost solution for mitigating the majoritarian bias of ASR systems, without the need to train new domain- or accent-specific models.
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023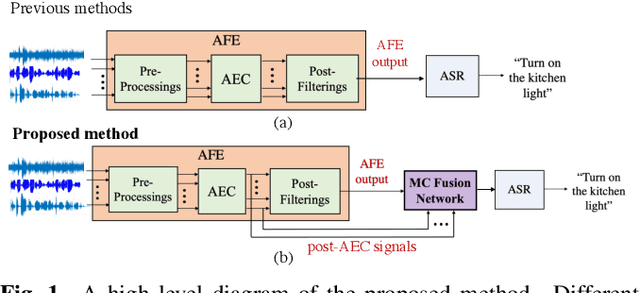

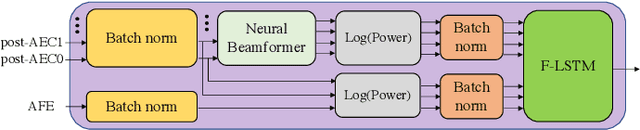
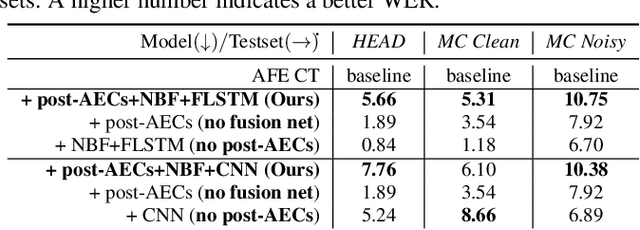
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
Reducing Geographic Disparities in Automatic Speech Recognition via Elastic Weight Consolidation
Jul 16, 2022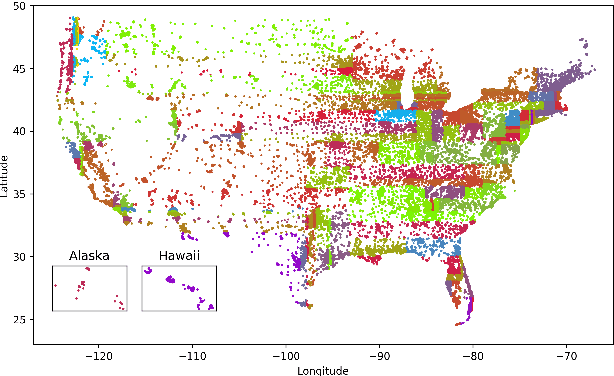

We present an approach to reduce the performance disparity between geographic regions without degrading performance on the overall user population for ASR. A popular approach is to fine-tune the model with data from regions where the ASR model has a higher word error rate (WER). However, when the ASR model is adapted to get better performance on these high-WER regions, its parameters wander from the previous optimal values, which can lead to worse performance in other regions. In our proposed method, we utilize the elastic weight consolidation (EWC) regularization loss to identify directions in parameters space along which the ASR weights can vary to improve for high-error regions, while still maintaining performance on the speaker population overall. Our results demonstrate that EWC can reduce the word error rate (WER) in the region with highest WER by 3.2% relative while reducing the overall WER by 1.3% relative. We also evaluate the role of language and acoustic models in ASR fairness and propose a clustering algorithm to identify WER disparities based on geographic region.
VADOI:Voice-Activity-Detection Overlapping Inference For End-to-end Long-form Speech Recognition
Feb 22, 2022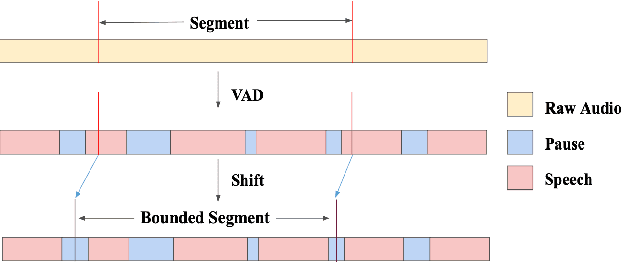

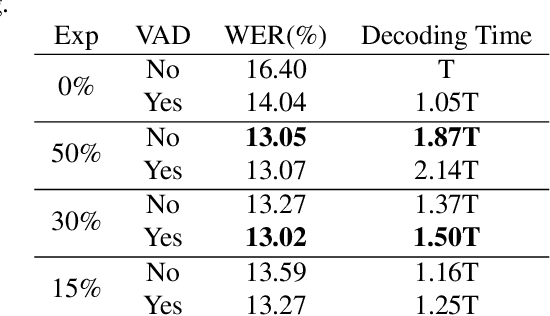
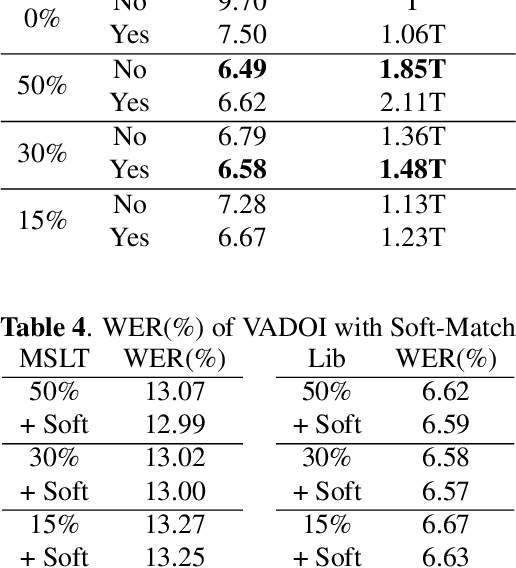
While end-to-end models have shown great success on the Automatic Speech Recognition task, performance degrades severely when target sentences are long-form. The previous proposed methods, (partial) overlapping inference are shown to be effective on long-form decoding. For both methods, word error rate (WER) decreases monotonically when overlapping percentage decreases. Setting aside computational cost, the setup with 50% overlapping during inference can achieve the best performance. However, a lower overlapping percentage has an advantage of fast inference speed. In this paper, we first conduct comprehensive experiments comparing overlapping inference and partial overlapping inference with various configurations. We then propose Voice-Activity-Detection Overlapping Inference to provide a trade-off between WER and computation cost. Results show that the proposed method can achieve a 20% relative computation cost reduction on Librispeech and Microsoft Speech Language Translation long-form corpus while maintaining the WER performance when comparing to the best performing overlapping inference algorithm. We also propose Soft-Match to compensate for similar words mis-aligned problem.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021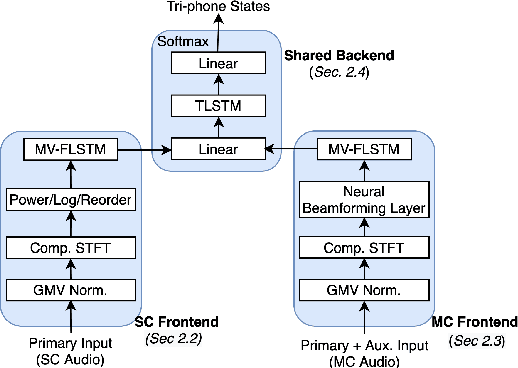
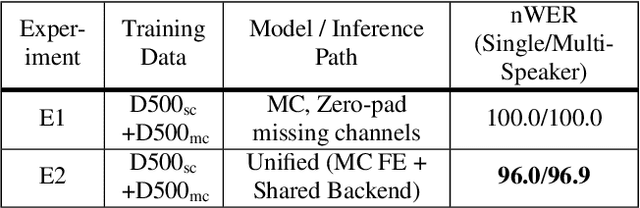
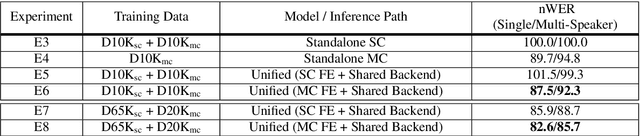
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
SynthASR: Unlocking Synthetic Data for Speech Recognition
Jun 14, 2021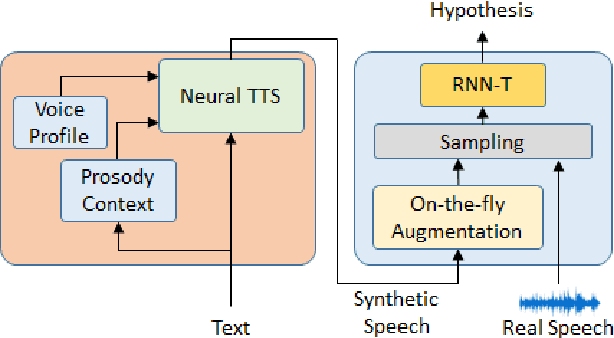
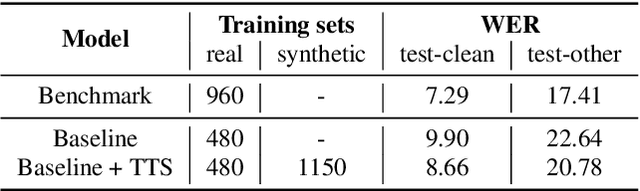
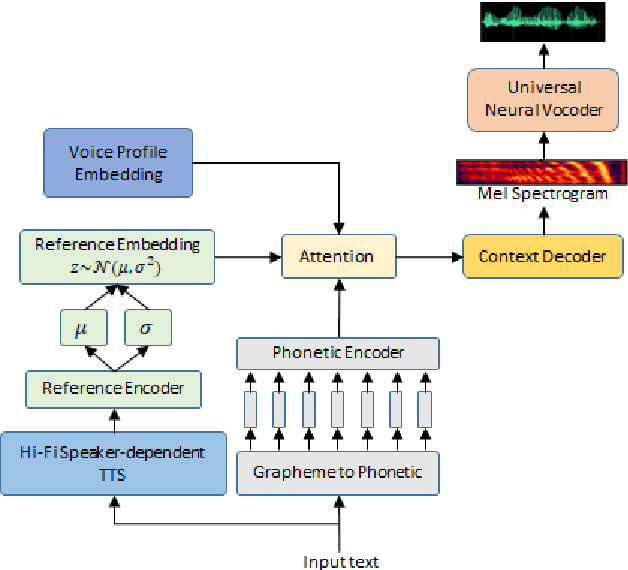
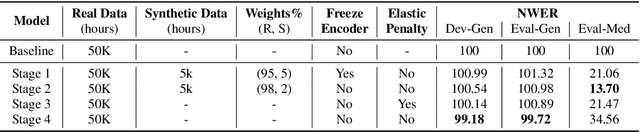
End-to-end (E2E) automatic speech recognition (ASR) models have recently demonstrated superior performance over the traditional hybrid ASR models. Training an E2E ASR model requires a large amount of data which is not only expensive but may also raise dependency on production data. At the same time, synthetic speech generated by the state-of-the-art text-to-speech (TTS) engines has advanced to near-human naturalness. In this work, we propose to utilize synthetic speech for ASR training (SynthASR) in applications where data is sparse or hard to get for ASR model training. In addition, we apply continual learning with a novel multi-stage training strategy to address catastrophic forgetting, achieved by a mix of weighted multi-style training, data augmentation, encoder freezing, and parameter regularization. In our experiments conducted on in-house datasets for a new application of recognizing medication names, training ASR RNN-T models with synthetic audio via the proposed multi-stage training improved the recognition performance on new application by more than 65% relative, without degradation on existing general applications. Our observations show that SynthASR holds great promise in training the state-of-the-art large-scale E2E ASR models for new applications while reducing the costs and dependency on production data.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

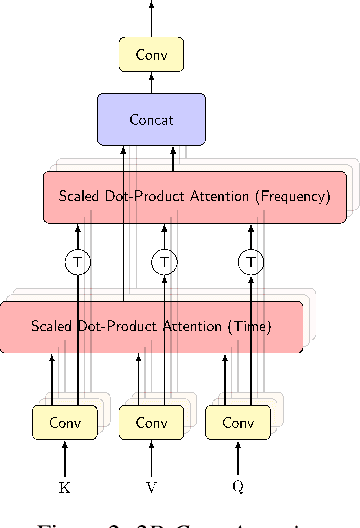

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021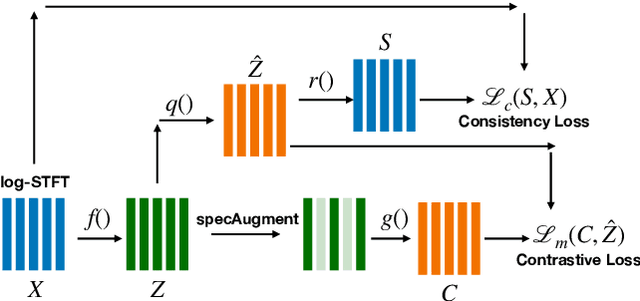

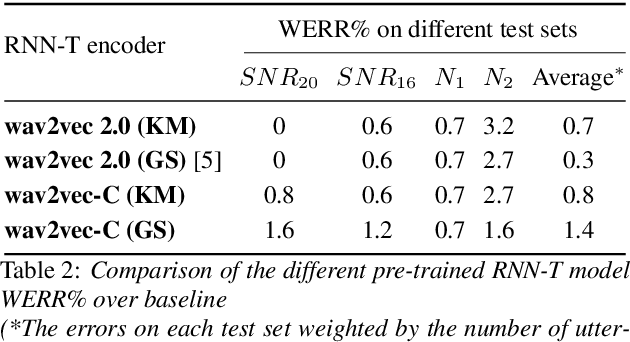
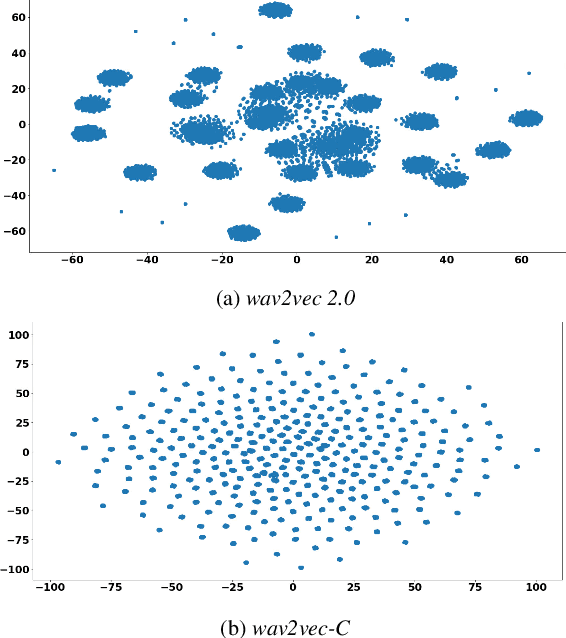
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
REDAT: Accent-Invariant Representation for End-to-End ASR by Domain Adversarial Training with Relabeling
Dec 14, 2020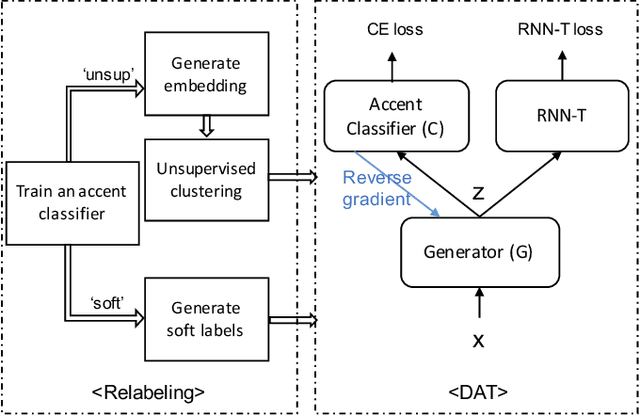
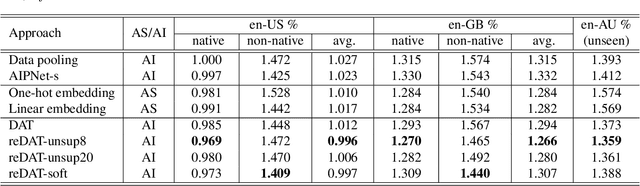
Accents mismatching is a critical problem for end-to-end ASR. This paper aims to address this problem by building an accent-robust RNN-T system with domain adversarial training (DAT). We unveil the magic behind DAT and provide, for the first time, a theoretical guarantee that DAT learns accent-invariant representations. We also prove that performing the gradient reversal in DAT is equivalent to minimizing the Jensen-Shannon divergence between domain output distributions. Motivated by the proof of equivalence, we introduce reDAT, a novel technique based on DAT, which relabels data using either unsupervised clustering or soft labels. Experiments on 23K hours of multi-accent data show that DAT achieves competitive results over accent-specific baselines on both native and non-native English accents but up to 13% relative WER reduction on unseen accents; our reDAT yields further improvements over DAT by 3% and 8% relatively on non-native accents of American and British English.