 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Paper and Code
Mar 01, 2023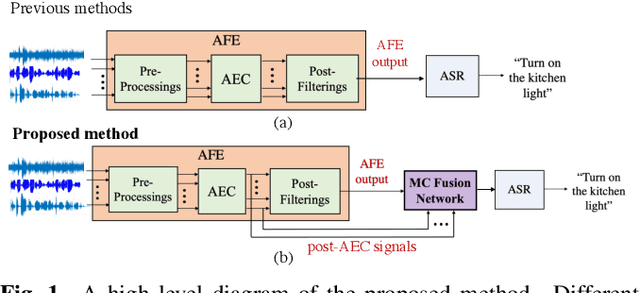

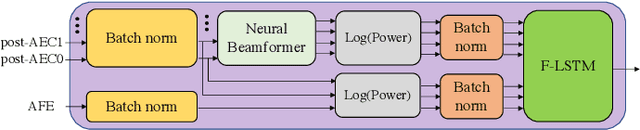
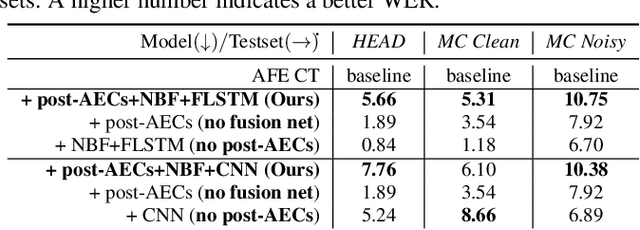
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.