 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 05, 2023



We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023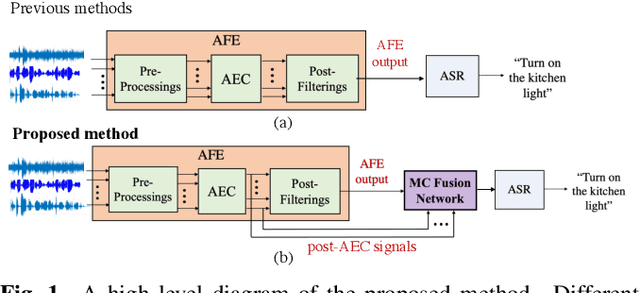

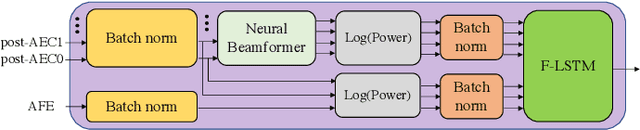
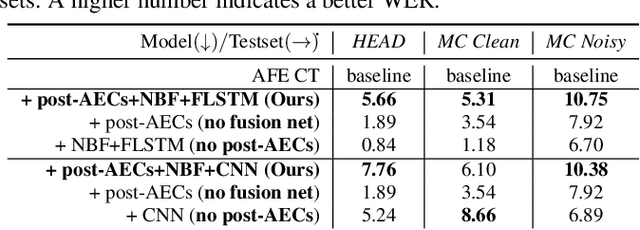
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.