 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023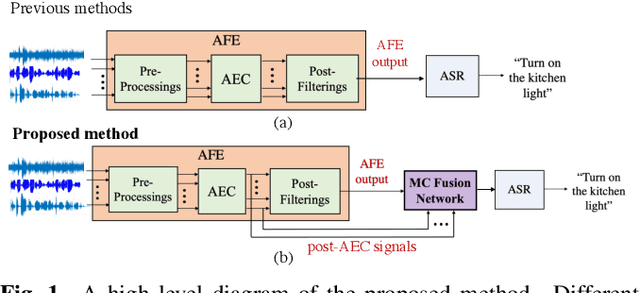

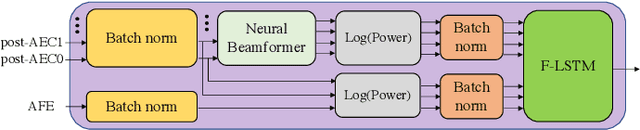
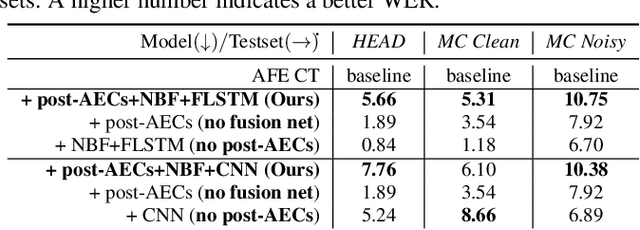
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022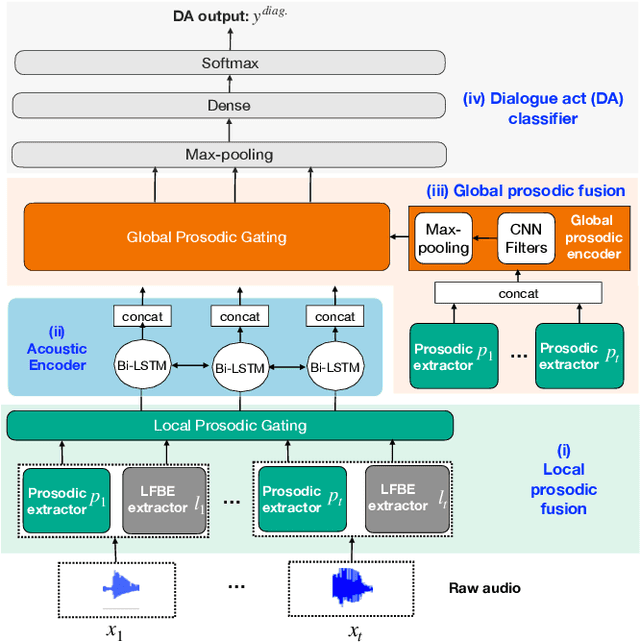
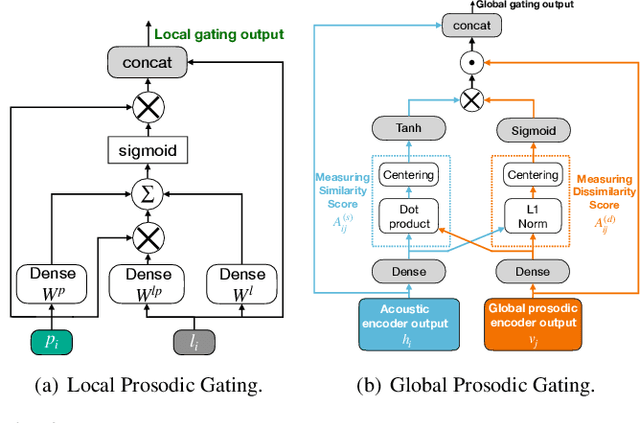

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021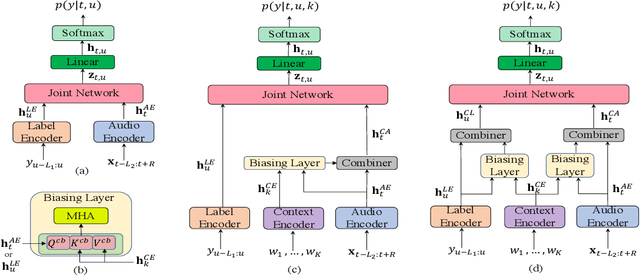

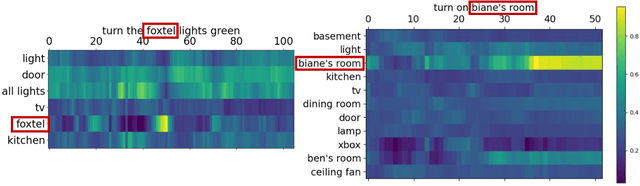
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
Multi-Channel Transformer Transducer for Speech Recognition
Aug 30, 2021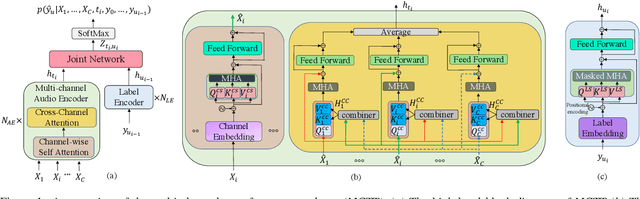
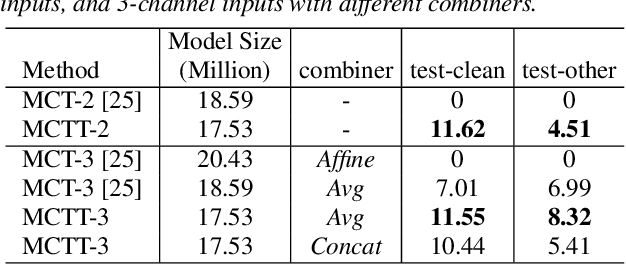
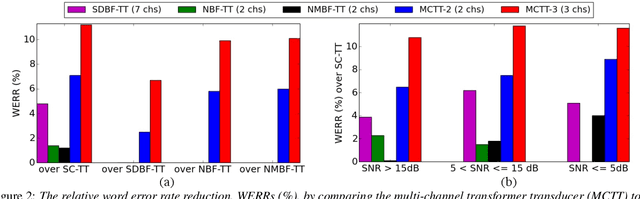
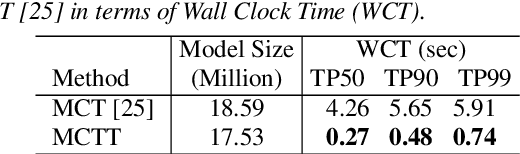
Multi-channel inputs offer several advantages over single-channel, to improve the robustness of on-device speech recognition systems. Recent work on multi-channel transformer, has proposed a way to incorporate such inputs into end-to-end ASR for improved accuracy. However, this approach is characterized by a high computational complexity, which prevents it from being deployed in on-device systems. In this paper, we present a novel speech recognition model, Multi-Channel Transformer Transducer (MCTT), which features end-to-end multi-channel training, low computation cost, and low latency so that it is suitable for streaming decoding in on-device speech recognition. In a far-field in-house dataset, our MCTT outperforms stagewise multi-channel models with transformer-transducer up to 6.01% relative WER improvement (WERR). In addition, MCTT outperforms the multi-channel transformer up to 11.62% WERR, and is 15.8 times faster in terms of inference speed. We further show that we can improve the computational cost of MCTT by constraining the future and previous context in attention computations.
DiPCo -- Dinner Party Corpus
Sep 30, 2019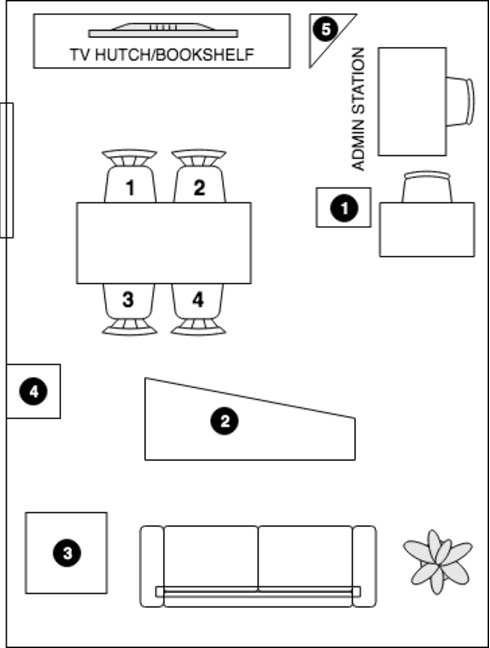
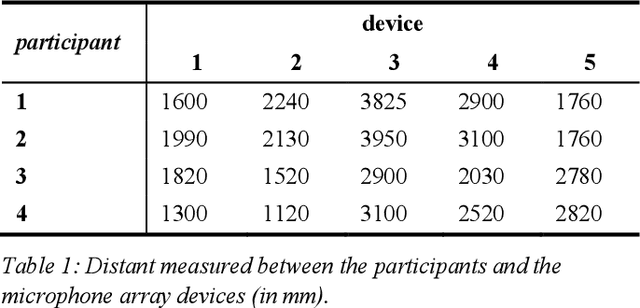
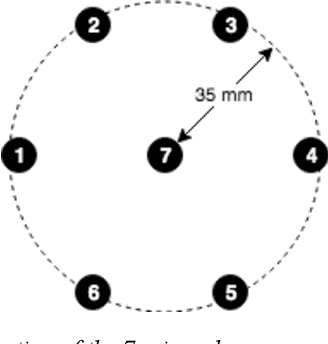

We present a speech data corpus that simulates a "dinner party" scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at different locations in the recording room. The dataset contains the audio recordings and human labeled transcripts of a total of 10 sessions with a duration between 15 and 45 minutes. The corpus was created to advance in the field of noise robust and distant speech processing and is intended to serve as a public research and benchmarking data set.
Automatic context window composition for distant speech recognition
May 26, 2018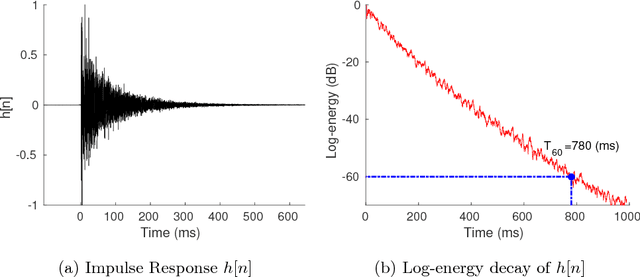
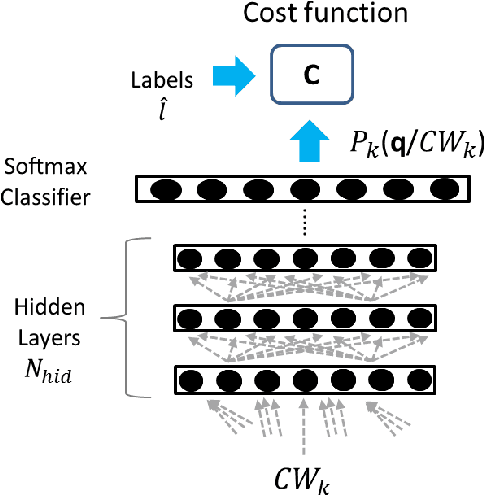
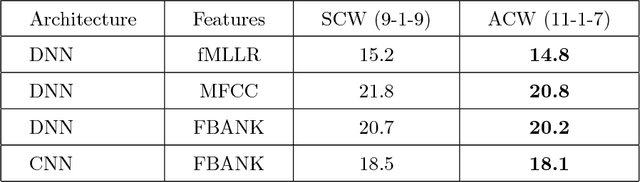
Distant speech recognition is being revolutionized by deep learning, that has contributed to significantly outperform previous HMM-GMM systems. A key aspect behind the rapid rise and success of DNNs is their ability to better manage large time contexts. With this regard, asymmetric context windows that embed more past than future frames have been recently used with feed-forward neural networks. This context configuration turns out to be useful not only to address low-latency speech recognition, but also to boost the recognition performance under reverberant conditions. This paper investigates on the mechanisms occurring inside DNNs, which lead to an effective application of asymmetric contexts.In particular, we propose a novel method for automatic context window composition based on a gradient analysis. The experiments, performed with different acoustic environments, features, DNN architectures, microphone settings, and recognition tasks show that our simple and efficient strategy leads to a less redundant frame configuration, which makes DNN training more effective in reverberant scenarios.
Light Gated Recurrent Units for Speech Recognition
Mar 26, 2018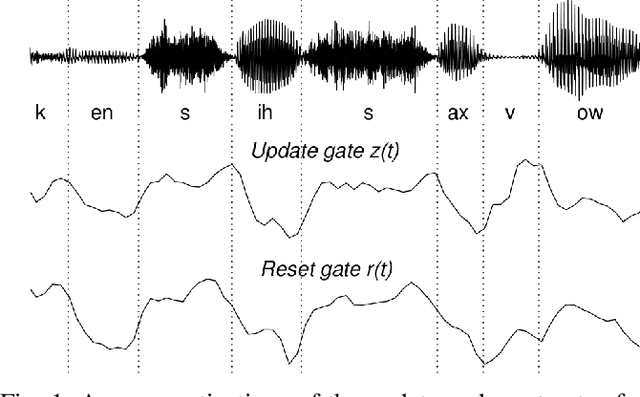
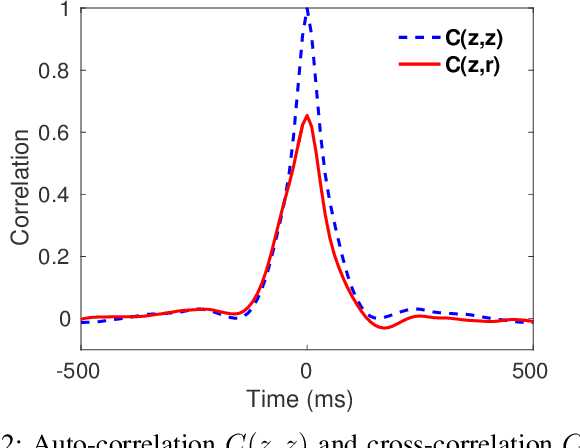
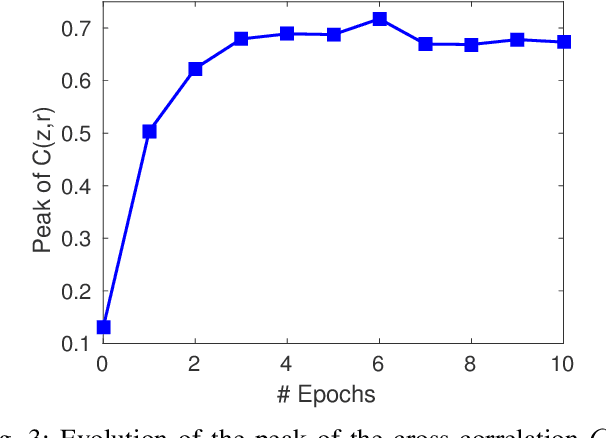
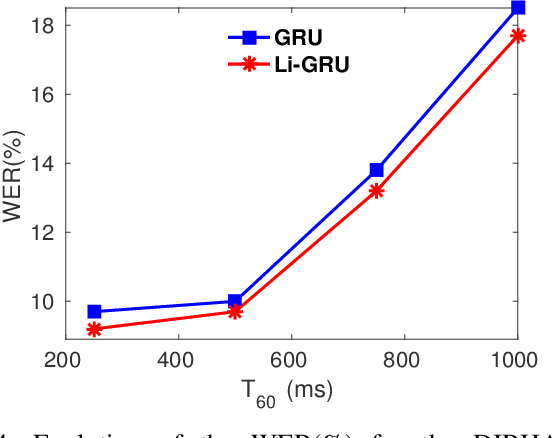
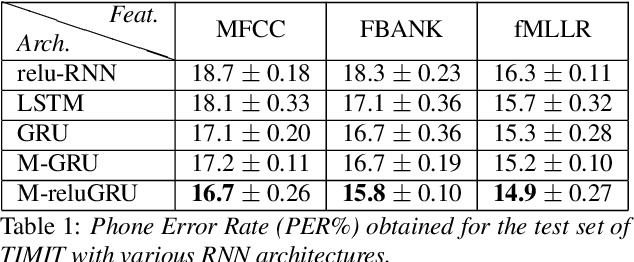
A field that has directly benefited from the recent advances in deep learning is Automatic Speech Recognition (ASR). Despite the great achievements of the past decades, however, a natural and robust human-machine speech interaction still appears to be out of reach, especially in challenging environments characterized by significant noise and reverberation. To improve robustness, modern speech recognizers often employ acoustic models based on Recurrent Neural Networks (RNNs), that are naturally able to exploit large time contexts and long-term speech modulations. It is thus of great interest to continue the study of proper techniques for improving the effectiveness of RNNs in processing speech signals. In this paper, we revise one of the most popular RNN models, namely Gated Recurrent Units (GRUs), and propose a simplified architecture that turned out to be very effective for ASR. The contribution of this work is two-fold: First, we analyze the role played by the reset gate, showing that a significant redundancy with the update gate occurs. As a result, we propose to remove the former from the GRU design, leading to a more efficient and compact single-gate model. Second, we propose to replace hyperbolic tangent with ReLU activations. This variation couples well with batch normalization and could help the model learn long-term dependencies without numerical issues. Results show that the proposed architecture, called Light GRU (Li-GRU), not only reduces the per-epoch training time by more than 30% over a standard GRU, but also consistently improves the recognition accuracy across different tasks, input features, noisy conditions, as well as across different ASR paradigms, ranging from standard DNN-HMM speech recognizers to end-to-end CTC models.
* Copyright 2018 IEEE
Contaminated speech training methods for robust DNN-HMM distant speech recognition
Oct 10, 2017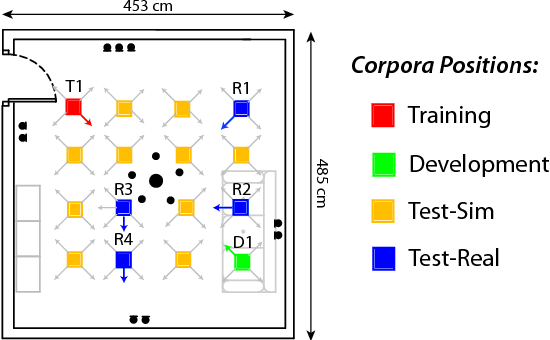

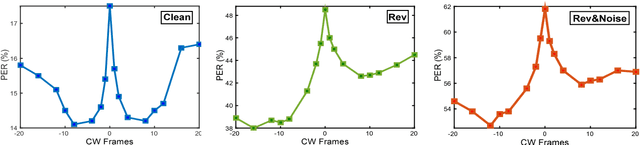

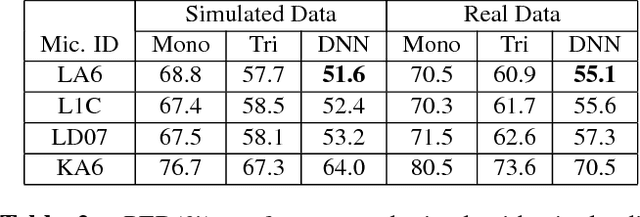
Despite the significant progress made in the last years, state-of-the-art speech recognition technologies provide a satisfactory performance only in the close-talking condition. Robustness of distant speech recognition in adverse acoustic conditions, on the other hand, remains a crucial open issue for future applications of human-machine interaction. To this end, several advances in speech enhancement, acoustic scene analysis as well as acoustic modeling, have recently contributed to improve the state-of-the-art in the field. One of the most effective approaches to derive a robust acoustic modeling is based on using contaminated speech, which proved helpful in reducing the acoustic mismatch between training and testing conditions. In this paper, we revise this classical approach in the context of modern DNN-HMM systems, and propose the adoption of three methods, namely, asymmetric context windowing, close-talk based supervision, and close-talk based pre-training. The experimental results, obtained using both real and simulated data, show a significant advantage in using these three methods, overall providing a 15% error rate reduction compared to the baseline systems. The same trend in performance is confirmed either using a high-quality training set of small size, and a large one.
The DIRHA-English corpus and related tasks for distant-speech recognition in domestic environments
Oct 06, 2017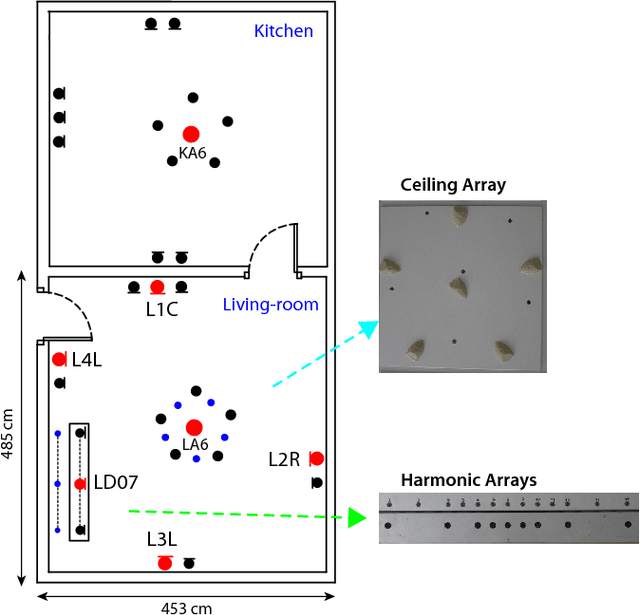
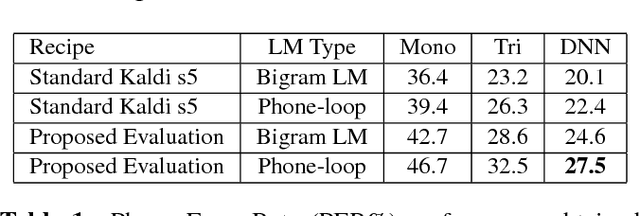
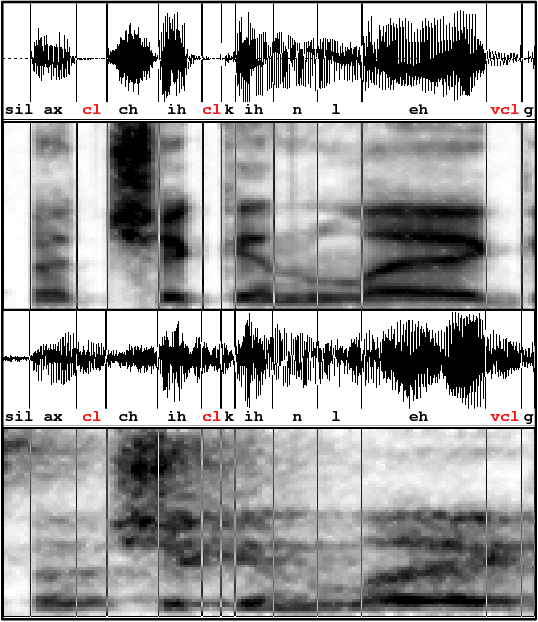
This paper introduces the contents and the possible usage of the DIRHA-ENGLISH multi-microphone corpus, recently realized under the EC DIRHA project. The reference scenario is a domestic environment equipped with a large number of microphones and microphone arrays distributed in space. The corpus is composed of both real and simulated material, and it includes 12 US and 12 UK English native speakers. Each speaker uttered different sets of phonetically-rich sentences, newspaper articles, conversational speech, keywords, and commands. From this material, a large set of 1-minute sequences was generated, which also includes typical domestic background noise as well as inter/intra-room reverberation effects. Dev and test sets were derived, which represent a very precious material for different studies on multi-microphone speech processing and distant-speech recognition. Various tasks and corresponding Kaldi recipes have already been developed. The paper reports a first set of baseline results obtained using different techniques, including Deep Neural Networks (DNN), aligned with the state-of-the-art at international level.
Improving speech recognition by revising gated recurrent units
Sep 29, 2017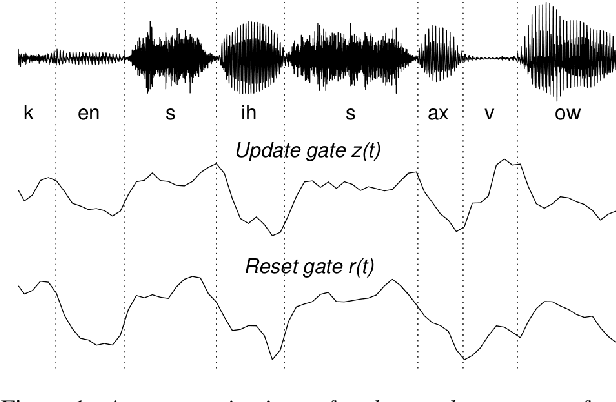
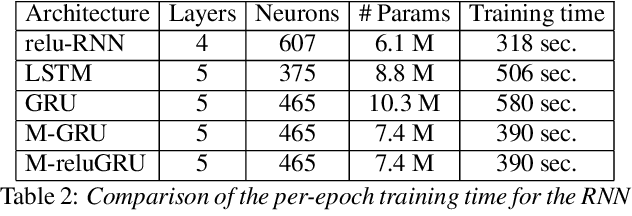
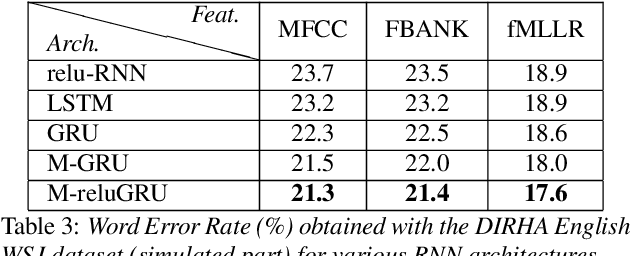
Speech recognition is largely taking advantage of deep learning, showing that substantial benefits can be obtained by modern Recurrent Neural Networks (RNNs). The most popular RNNs are Long Short-Term Memory (LSTMs), which typically reach state-of-the-art performance in many tasks thanks to their ability to learn long-term dependencies and robustness to vanishing gradients. Nevertheless, LSTMs have a rather complex design with three multiplicative gates, that might impair their efficient implementation. An attempt to simplify LSTMs has recently led to Gated Recurrent Units (GRUs), which are based on just two multiplicative gates. This paper builds on these efforts by further revising GRUs and proposing a simplified architecture potentially more suitable for speech recognition. The contribution of this work is two-fold. First, we suggest to remove the reset gate in the GRU design, resulting in a more efficient single-gate architecture. Second, we propose to replace tanh with ReLU activations in the state update equations. Results show that, in our implementation, the revised architecture reduces the per-epoch training time with more than 30% and consistently improves recognition performance across different tasks, input features, and noisy conditions when compared to a standard GRU.