 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead When It Matters: Adaptive Non-causal Transformers for Streaming Neural Transducers
May 09, 2023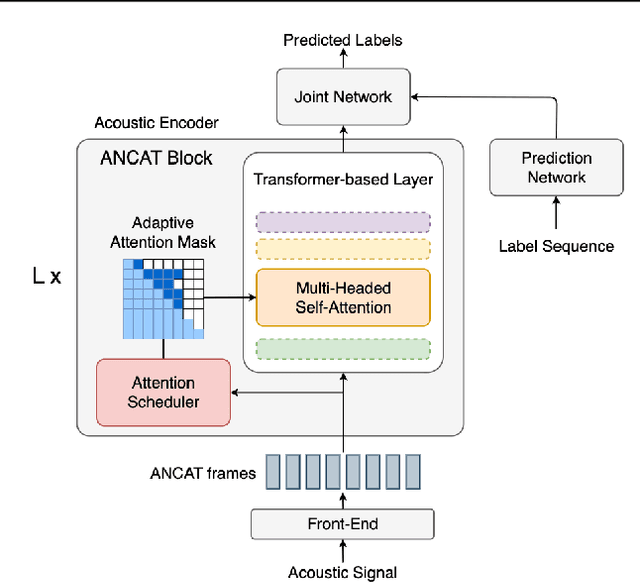
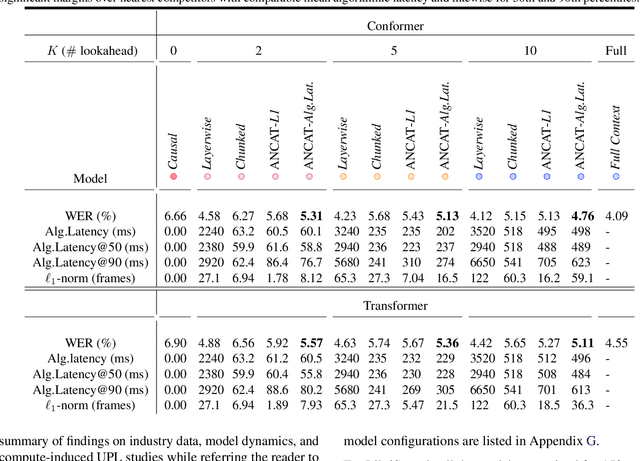
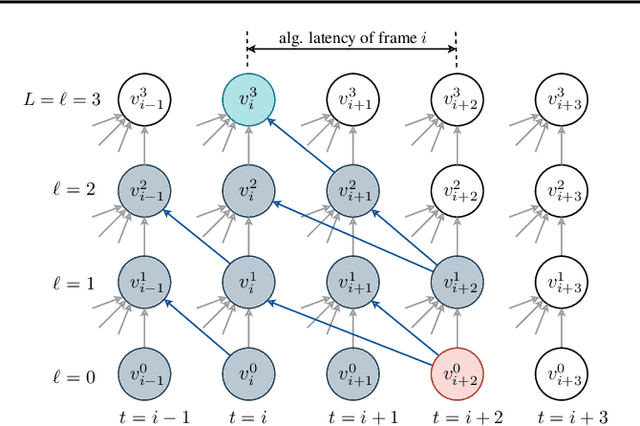
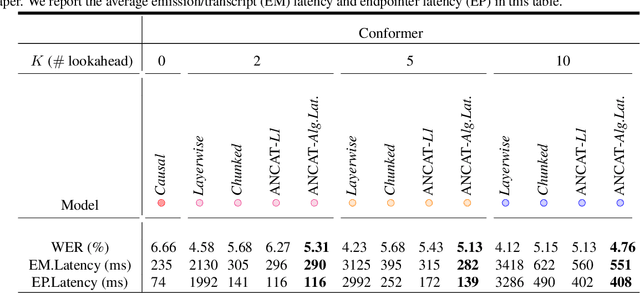
Streaming speech recognition architectures are employed for low-latency, real-time applications. Such architectures are often characterized by their causality. Causal architectures emit tokens at each frame, relying only on current and past signal, while non-causal models are exposed to a window of future frames at each step to increase predictive accuracy. This dichotomy amounts to a trade-off for real-time Automatic Speech Recognition (ASR) system design: profit from the low-latency benefit of strictly-causal architectures while accepting predictive performance limitations, or realize the modeling benefits of future-context models accompanied by their higher latency penalty. In this work, we relax the constraints of this choice and present the Adaptive Non-Causal Attention Transducer (ANCAT). Our architecture is non-causal in the traditional sense, but executes in a low-latency, streaming manner by dynamically choosing when to rely on future context and to what degree within the audio stream. The resulting mechanism, when coupled with our novel regularization algorithms, delivers comparable accuracy to non-causal configurations while improving significantly upon latency, closing the gap with their causal counterparts. We showcase our design experimentally by reporting comparative ASR task results with measures of accuracy and latency on both publicly accessible and production-scale, voice-assistant datasets.
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023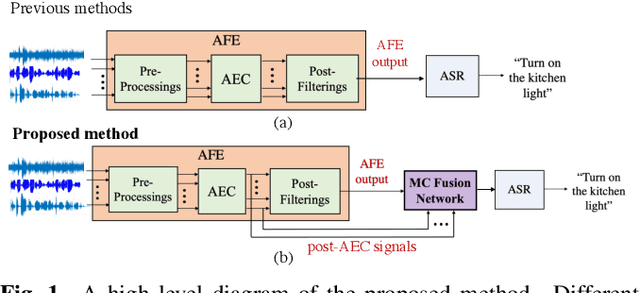

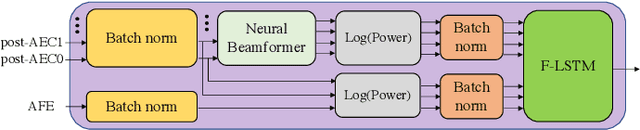
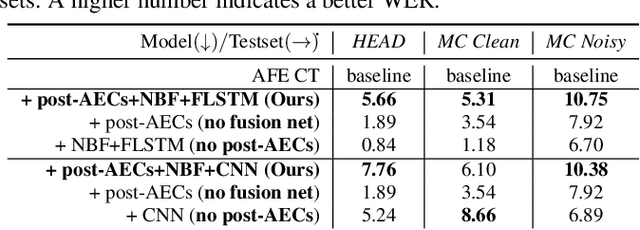
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
Toward Fairness in Speech Recognition: Discovery and mitigation of performance disparities
Jul 22, 2022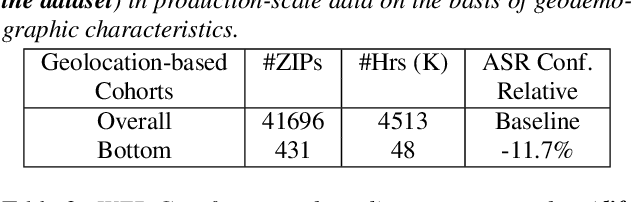
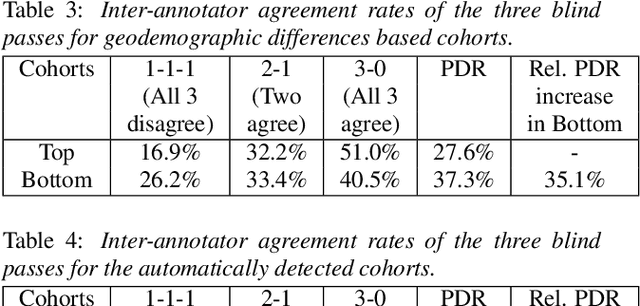

As for other forms of AI, speech recognition has recently been examined with respect to performance disparities across different user cohorts. One approach to achieve fairness in speech recognition is to (1) identify speaker cohorts that suffer from subpar performance and (2) apply fairness mitigation measures targeting the cohorts discovered. In this paper, we report on initial findings with both discovery and mitigation of performance disparities using data from a product-scale AI assistant speech recognition system. We compare cohort discovery based on geographic and demographic information to a more scalable method that groups speakers without human labels, using speaker embedding technology. For fairness mitigation, we find that oversampling of underrepresented cohorts, as well as modeling speaker cohort membership by additional input variables, reduces the gap between top- and bottom-performing cohorts, without deteriorating overall recognition accuracy.
Reducing Geographic Disparities in Automatic Speech Recognition via Elastic Weight Consolidation
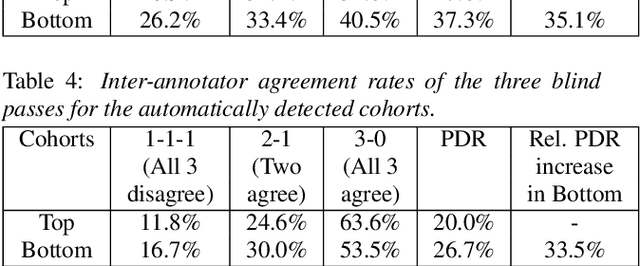
Jul 16, 2022

We present an approach to reduce the performance disparity between geographic regions without degrading performance on the overall user population for ASR. A popular approach is to fine-tune the model with data from regions where the ASR model has a higher word error rate (WER). However, when the ASR model is adapted to get better performance on these high-WER regions, its parameters wander from the previous optimal values, which can lead to worse performance in other regions. In our proposed method, we utilize the elastic weight consolidation (EWC) regularization loss to identify directions in parameters space along which the ASR weights can vary to improve for high-error regions, while still maintaining performance on the speaker population overall. Our results demonstrate that EWC can reduce the word error rate (WER) in the region with highest WER by 3.2% relative while reducing the overall WER by 1.3% relative. We also evaluate the role of language and acoustic models in ASR fairness and propose a clustering algorithm to identify WER disparities based on geographic region.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022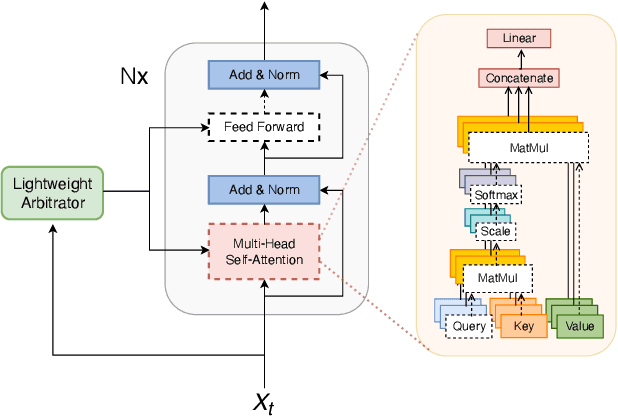
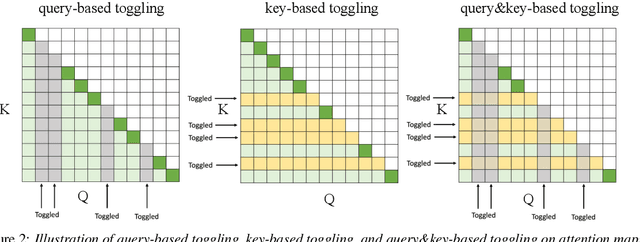
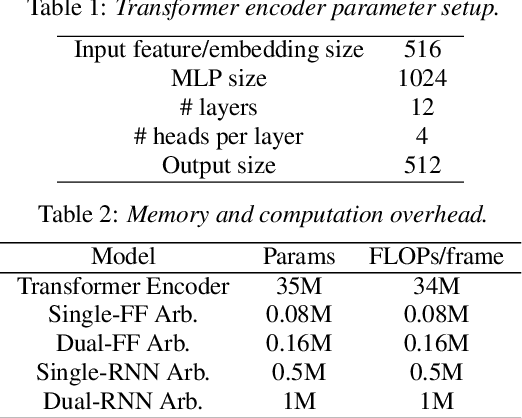
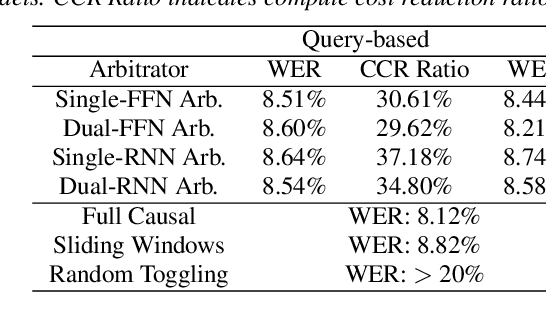
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
Investigation of Training Label Error Impact on RNN-T
Dec 01, 2021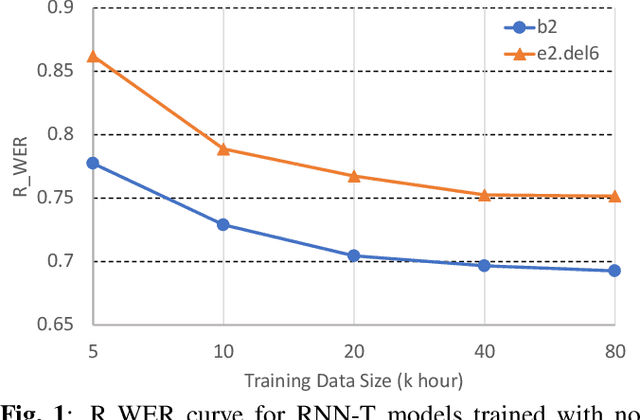
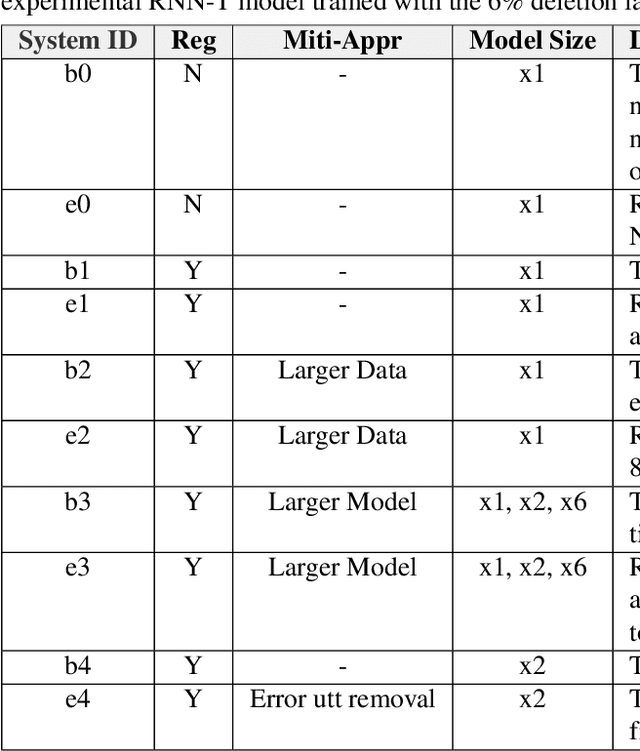
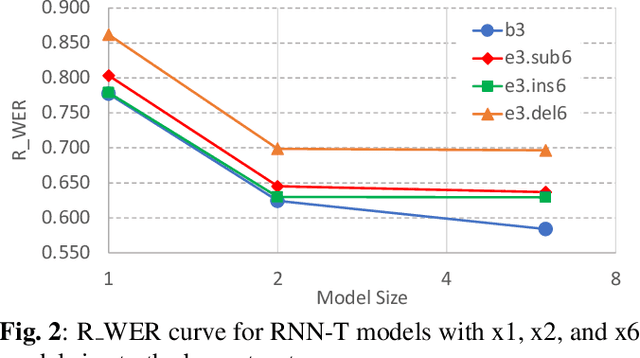
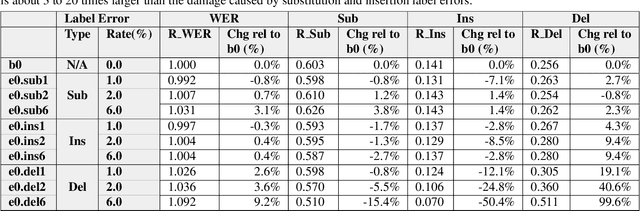
In this paper, we propose an approach to quantitatively analyze impacts of different training label errors to RNN-T based ASR models. The result shows deletion errors are more harmful than substitution and insertion label errors in RNN-T training data. We also examined label error impact mitigation approaches on RNN-T and found that, though all the methods mitigate the label-error-caused degradation to some extent, they could not remove the performance gap between the models trained with and without the presence of label errors. Based on the analysis results, we suggest to design data pipelines for RNN-T with higher priority on reducing deletion label errors. We also find that ensuring high-quality training labels remains important, despite of the existence of the label error mitigation approaches.
Warped Dynamic Linear Models for Time Series of Counts
Oct 27, 2021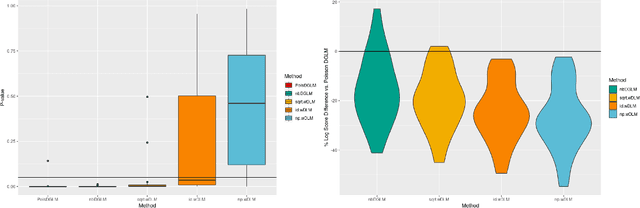
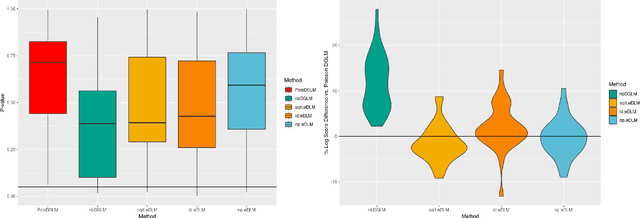
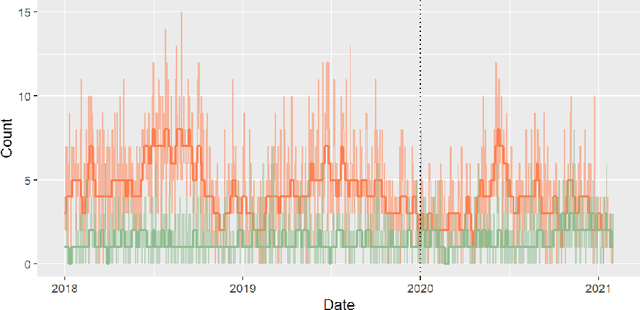
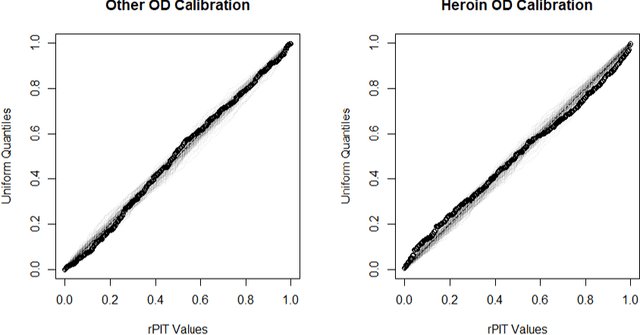
Dynamic Linear Models (DLMs) are commonly employed for time series analysis due to their versatile structure, simple recursive updating, and probabilistic forecasting. However, the options for count time series are limited: Gaussian DLMs require continuous data, while Poisson-based alternatives often lack sufficient modeling flexibility. We introduce a novel methodology for count time series by warping a Gaussian DLM. The warping function has two components: a transformation operator that provides distributional flexibility and a rounding operator that ensures the correct support for the discrete data-generating process. Importantly, we develop conjugate inference for the warped DLM, which enables analytic and recursive updates for the state space filtering and smoothing distributions. We leverage these results to produce customized and efficient computing strategies for inference and forecasting, including Monte Carlo simulation for offline analysis and an optimal particle filter for online inference. This framework unifies and extends a variety of discrete time series models and is valid for natural counts, rounded values, and multivariate observations. Simulation studies illustrate the excellent forecasting capabilities of the warped DLM. The proposed approach is applied to a multivariate time series of daily overdose counts and demonstrates both modeling and computational successes.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021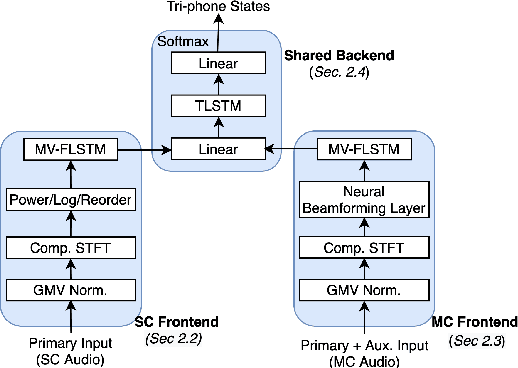
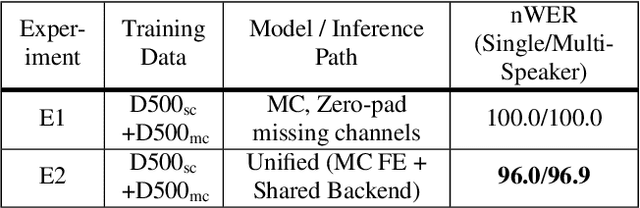
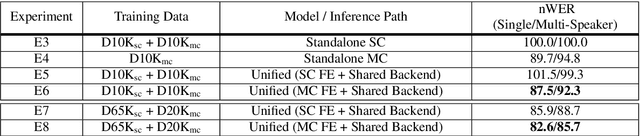
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
CoDERT: Distilling Encoder Representations with Co-learning for Transducer-based Speech Recognition
Jun 14, 2021


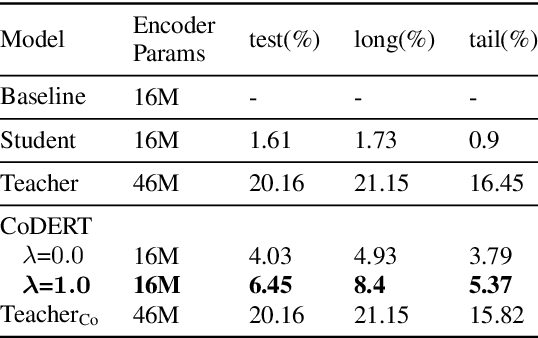
We propose a simple yet effective method to compress an RNN-Transducer (RNN-T) through the well-known knowledge distillation paradigm. We show that the transducer's encoder outputs naturally have a high entropy and contain rich information about acoustically similar word-piece confusions. This rich information is suppressed when combined with the lower entropy decoder outputs to produce the joint network logits. Consequently, we introduce an auxiliary loss to distill the encoder logits from a teacher transducer's encoder, and explore training strategies where this encoder distillation works effectively. We find that tandem training of teacher and student encoders with an inplace encoder distillation outperforms the use of a pre-trained and static teacher transducer. We also report an interesting phenomenon we refer to as implicit distillation, that occurs when the teacher and student encoders share the same decoder. Our experiments show 5.37-8.4% relative word error rate reductions (WERR) on in-house test sets, and 5.05-6.18% relative WERRs on LibriSpeech test sets.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

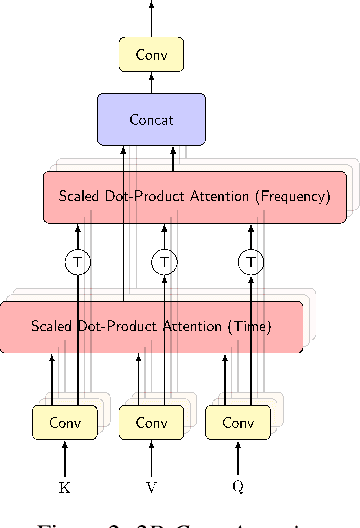

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.