 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023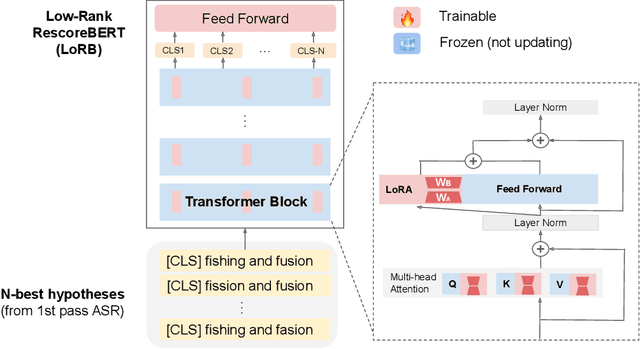
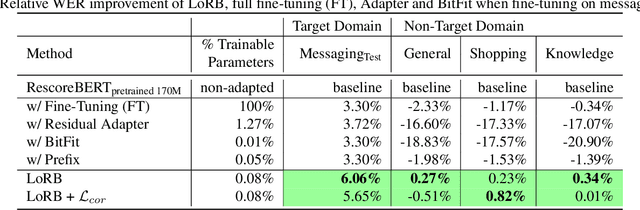
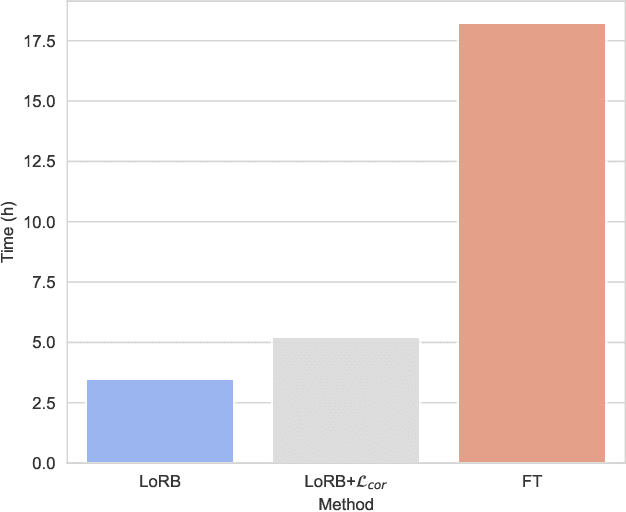
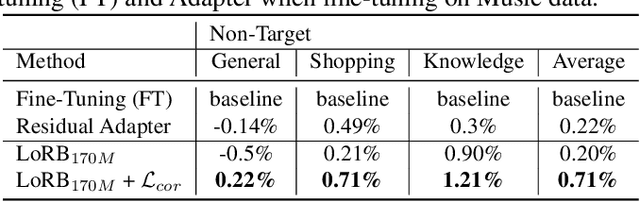
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
An Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 13, 2022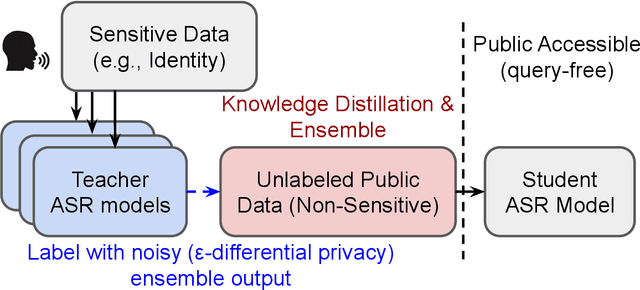
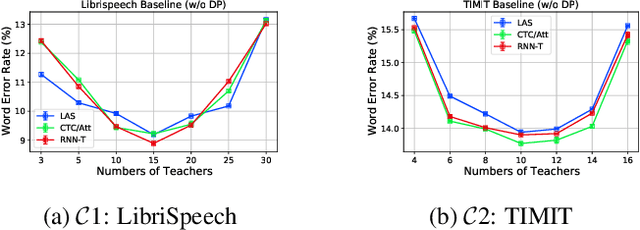
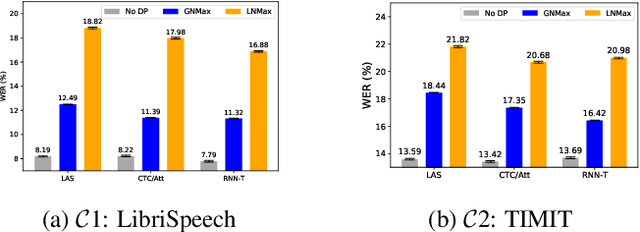
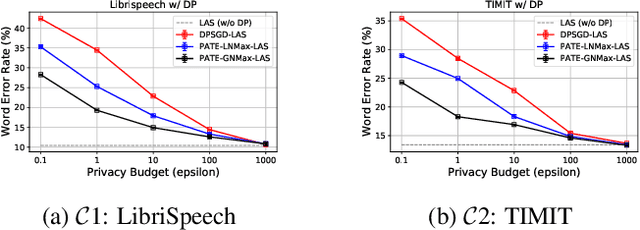
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. We extend PATE learning to work with dynamic patterns, namely speech utterances, and perform a first experimental demonstration that it prevents acoustic data leakage in ASR training. We evaluate three end-to-end deep models, including LAS, hybrid CTC/attention, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for an RNN transducer model evaluated with LibriSpeech. We also introduce a DP-preserving ASR solution for pretraining on public speech corpora.
Toward Fairness in Speech Recognition: Discovery and mitigation of performance disparities
Jul 22, 2022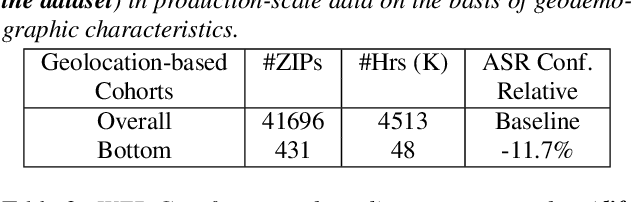
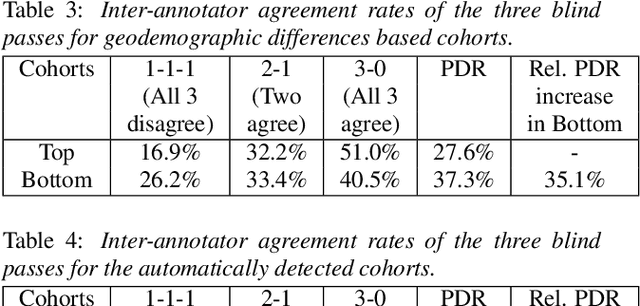
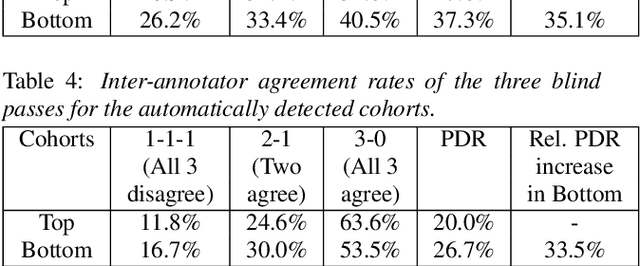

As for other forms of AI, speech recognition has recently been examined with respect to performance disparities across different user cohorts. One approach to achieve fairness in speech recognition is to (1) identify speaker cohorts that suffer from subpar performance and (2) apply fairness mitigation measures targeting the cohorts discovered. In this paper, we report on initial findings with both discovery and mitigation of performance disparities using data from a product-scale AI assistant speech recognition system. We compare cohort discovery based on geographic and demographic information to a more scalable method that groups speakers without human labels, using speaker embedding technology. For fairness mitigation, we find that oversampling of underrepresented cohorts, as well as modeling speaker cohort membership by additional input variables, reduces the gap between top- and bottom-performing cohorts, without deteriorating overall recognition accuracy.
Investigation of Training Label Error Impact on RNN-T
Dec 01, 2021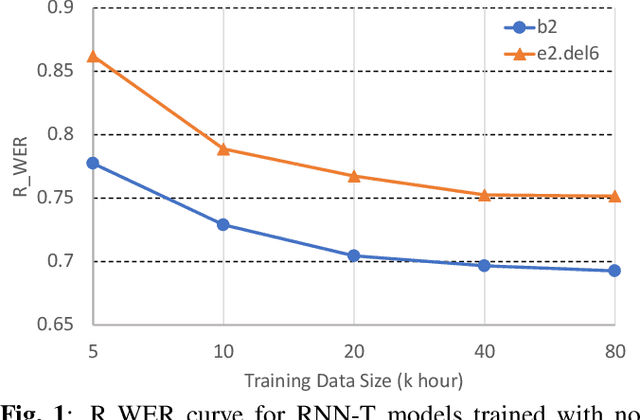
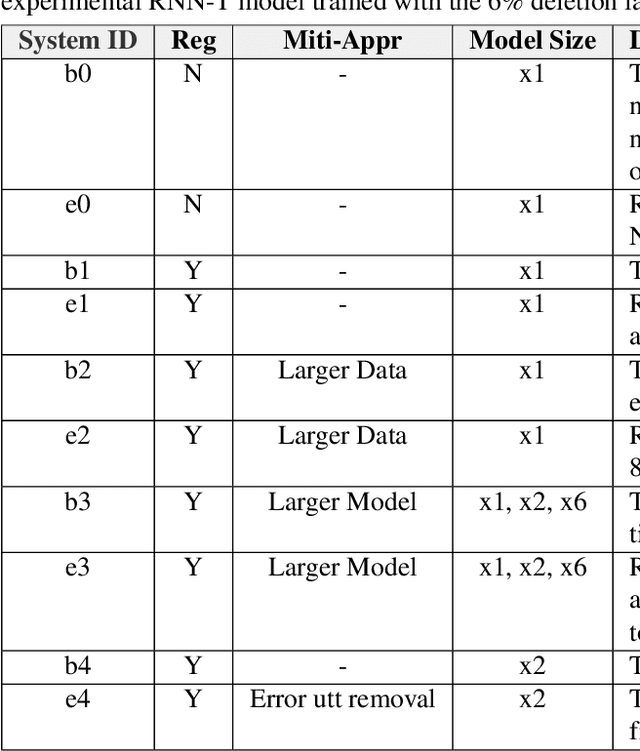
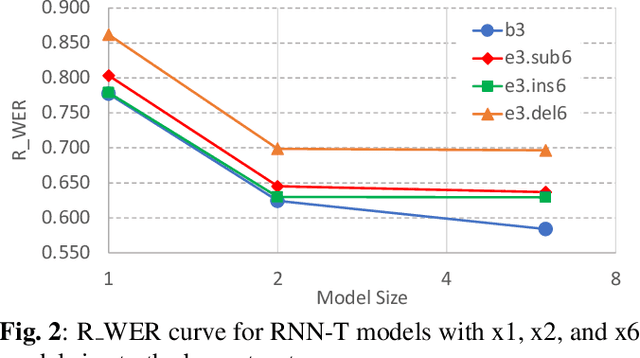
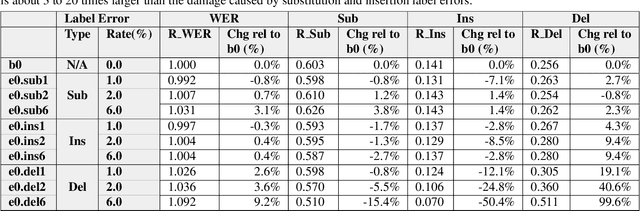
In this paper, we propose an approach to quantitatively analyze impacts of different training label errors to RNN-T based ASR models. The result shows deletion errors are more harmful than substitution and insertion label errors in RNN-T training data. We also examined label error impact mitigation approaches on RNN-T and found that, though all the methods mitigate the label-error-caused degradation to some extent, they could not remove the performance gap between the models trained with and without the presence of label errors. Based on the analysis results, we suggest to design data pipelines for RNN-T with higher priority on reducing deletion label errors. We also find that ensuring high-quality training labels remains important, despite of the existence of the label error mitigation approaches.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.
Data Techniques For Online End-to-end Speech Recognition
Jan 24, 2020



Practitioners often need to build ASR systems for new use cases in a short amount of time, given limited in-domain data. While recently developed end-to-end methods largely simplify the modeling pipelines, they still suffer from the data sparsity issue. In this work, we explore a few simple-to-implement techniques for building online ASR systems in an end-to-end fashion, with a small amount of transcribed data in the target domain. These techniques include data augmentation in the target domain, domain adaptation using models previously trained on a large source domain, and knowledge distillation on non-transcribed target domain data; they are applicable in real scenarios with different types of resources. Our experiments demonstrate that each technique is independently useful in the low-resource setting, and combining them yields significant improvement of the online ASR performance in the target domain.
End-to-end Anchored Speech Recognition
Feb 06, 2019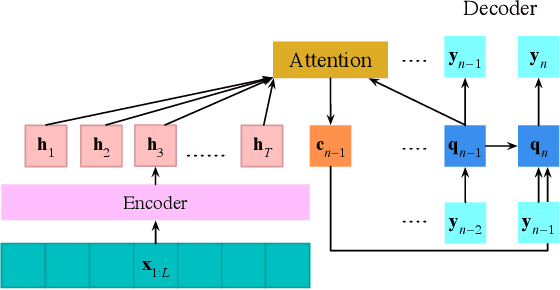
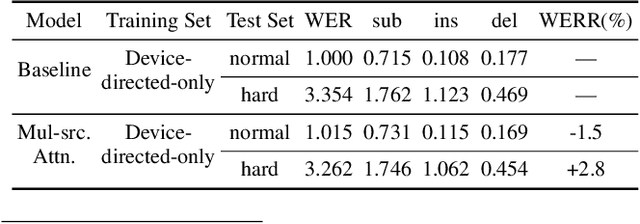

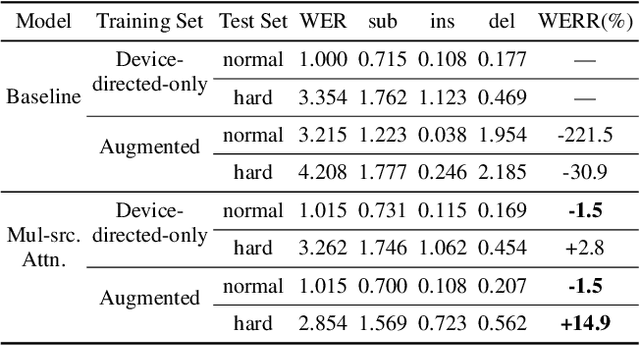
Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device-directed speech in the presence of interfering background speech, i.e., background noise and interfering speech from another person or media device in proximity need to be ignored. We propose two end-to-end models to tackle this problem with information extracted from the "anchored segment". The anchored segment refers to the wake-up word part of an audio stream, which contains valuable speaker information that can be used to suppress interfering speech and background noise. The first method is called "Multi-source Attention" where the attention mechanism takes both the speaker information and decoder state into consideration. The second method directly learns a frame-level mask on top of the encoder output. We also explore a multi-task learning setup where we use the ground truth of the mask to guide the learner. Given that audio data with interfering speech is rare in our training data set, we also propose a way to synthesize "noisy" speech from "clean" speech to mitigate the mismatch between training and test data. Our proposed methods show up to 15% relative reduction in WER for Amazon Alexa live data with interfering background speech without significantly degrading on clean speech.
Maximum a Posteriori Adaptation of Network Parameters in Deep Models
Aug 12, 2015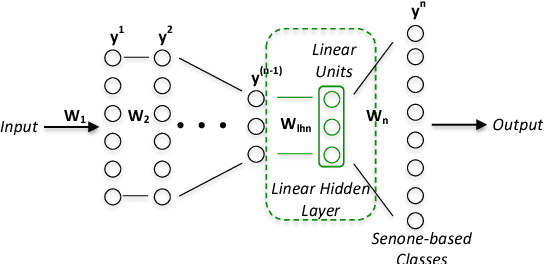
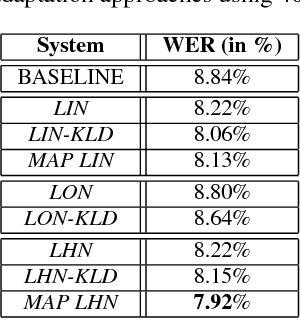
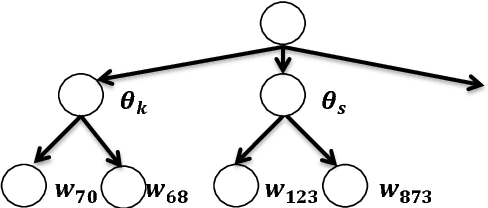
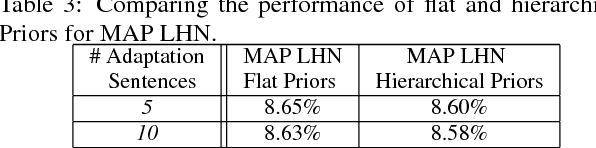
We present a Bayesian approach to adapting parameters of a well-trained context-dependent, deep-neural-network, hidden Markov model (CD-DNN-HMM) to improve automatic speech recognition performance. Given an abundance of DNN parameters but with only a limited amount of data, the effectiveness of the adapted DNN model can often be compromised. We formulate maximum a posteriori (MAP) adaptation of parameters of a specially designed CD-DNN-HMM with an augmented linear hidden networks connected to the output tied states, or senones, and compare it to feature space MAP linear regression previously proposed. Experimental evidences on the 20,000-word open vocabulary Wall Street Journal task demonstrate the feasibility of the proposed framework. In supervised adaptation, the proposed MAP adaptation approach provides more than 10% relative error reduction and consistently outperforms the conventional transformation based methods. Furthermore, we present an initial attempt to generate hierarchical priors to improve adaptation efficiency and effectiveness with limited adaptation data by exploiting similarities among senones.