 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023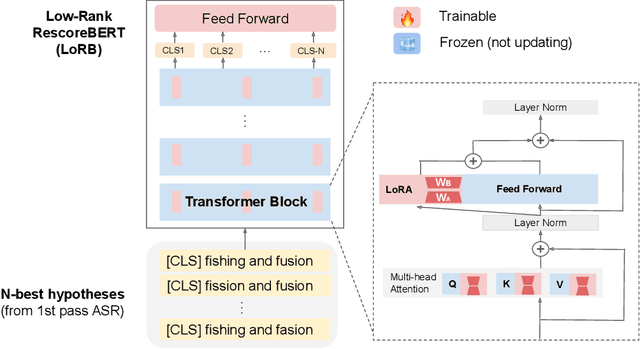
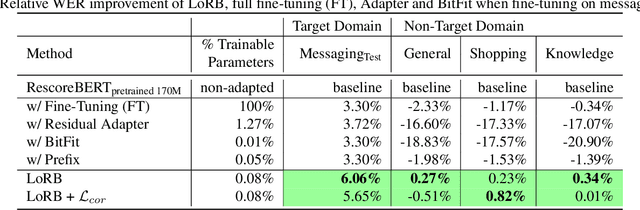
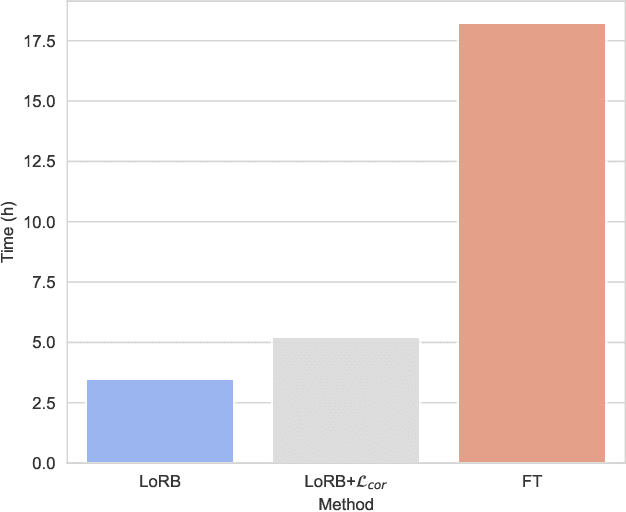
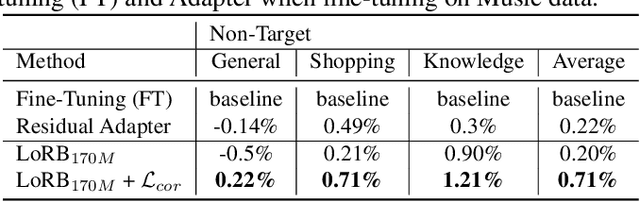
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.