 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
Sep 10, 2025Post-training language models (LMs) with reinforcement learning (RL) can enhance their complex reasoning capabilities without supervised fine-tuning, as demonstrated by DeepSeek-R1-Zero. However, effectively utilizing RL for LMs requires significant parallelization to scale-up inference, which introduces non-trivial technical challenges (e.g. latency, memory, and reliability) alongside ever-growing financial costs. We present Swarm sAmpling Policy Optimization (SAPO), a fully decentralized and asynchronous RL post-training algorithm. SAPO is designed for decentralized networks of heterogenous compute nodes, where each node manages its own policy model(s) while "sharing" rollouts with others in the network; no explicit assumptions about latency, model homogeneity, or hardware are required and nodes can operate in silo if desired. As a result, the algorithm avoids common bottlenecks in scaling RL post-training while also allowing (and even encouraging) new possibilities. By sampling rollouts "shared" across the network, it enables "Aha moments" to propagate, thereby bootstrapping the learning process. In this paper we show SAPO achieved cumulative reward gains of up to 94% in controlled experiments. We also share insights from tests on a network with thousands of nodes contributed by Gensyn community members running the algorithm on diverse hardware and models during an open-source demo.
NoLoCo: No-all-reduce Low Communication Training Method for Large Models
Jun 12, 2025Training large language models is generally done via optimization methods on clusters containing tens of thousands of accelerators, communicating over a high-bandwidth interconnect. Scaling up these clusters is expensive and can become impractical, imposing limits on the size of models that can be trained. Several recent studies have proposed training methods that are less communication intensive, avoiding the need for a highly connected compute cluster. These state-of-the-art low communication training methods still employ a synchronization step for model parameters, which, when performed over all model replicas, can become costly on a low-bandwidth network. In this work, we propose a novel optimization method, NoLoCo, that does not explicitly synchronize all model parameters during training and, as a result, does not require any collective communication. NoLoCo implicitly synchronizes model weights via a novel variant of the Nesterov momentum optimizer by partially averaging model weights with a randomly selected other one. We provide both a theoretical convergence analysis for our proposed optimizer as well as empirical results from language model training. We benchmark NoLoCo on a wide range of accelerator counts and model sizes, between 125M to 6.8B parameters. Our method requires significantly less communication overhead than fully sharded data parallel training or even widely used low communication training method, DiLoCo. The synchronization step itself is estimated to be one magnitude faster than the all-reduce used in DiLoCo for few hundred accelerators training over the internet. We also do not have any global blocking communication that reduces accelerator idling time. Compared to DiLoCo, we also observe up to $4\%$ faster convergence rate with wide range of model sizes and accelerator counts.
HDEE: Heterogeneous Domain Expert Ensemble
Feb 26, 2025Training dense LLMs requires enormous amounts of data and centralized compute, which introduces fundamental bottlenecks and ever-growing costs for large models. Several studies aim to reduce this dependency on centralization by reducing the communication overhead of training dense models. Taking this idea of reducing communication overhead to a natural extreme, by training embarrassingly parallelizable ensembles of small independent experts, has been shown to outperform large dense models trained in traditional centralized settings. However, existing studies do not take into account underlying differences amongst data domains and treat them as monolithic, regardless of their underlying complexity, size, or distribution. In this paper, we explore the effects of introducing heterogeneity to these ensembles of domain expert models. Specifically, by allowing models within the ensemble to vary in size--as well as the number of training steps taken depending on the training data's domain--we study the effect heterogeneity has on these ensembles when evaluated against domains included in, and excluded from, the training set. We use the same compute budget to train heterogeneous ensembles and homogeneous baselines for comparison. We show that the heterogeneous ensembles achieve the lowest perplexity scores in $20$ out of the $21$ data domains used in the evaluation. Our code is available at https://github.com/gensyn-ai/hdee.
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Sep 25, 2024Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jun 13, 2024



Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Investigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024



In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
Oct 10, 2023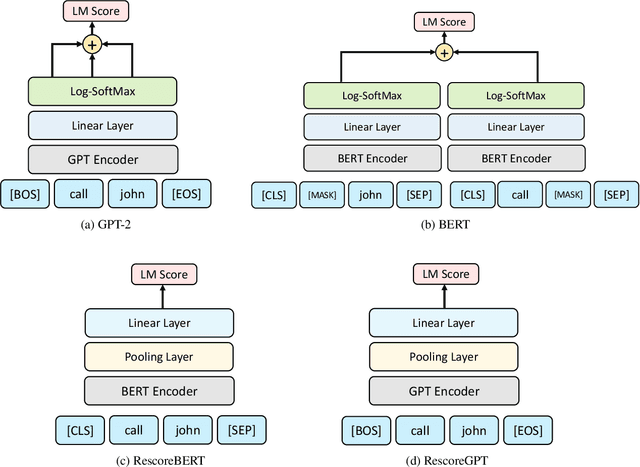
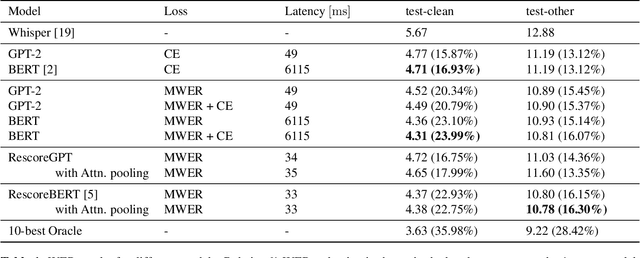
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023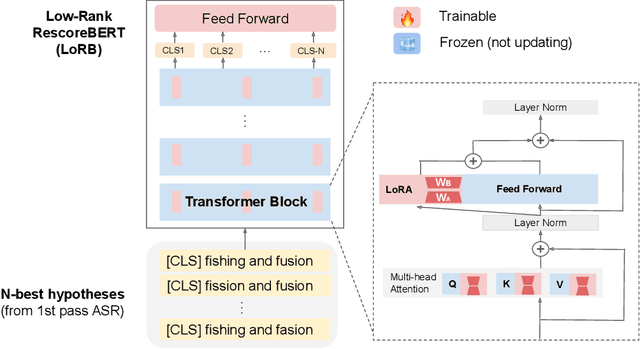
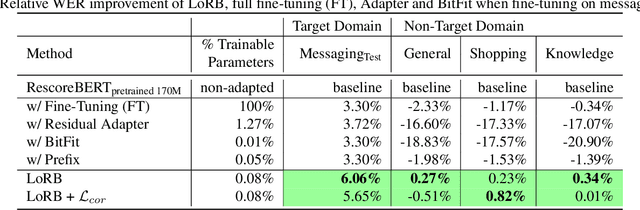
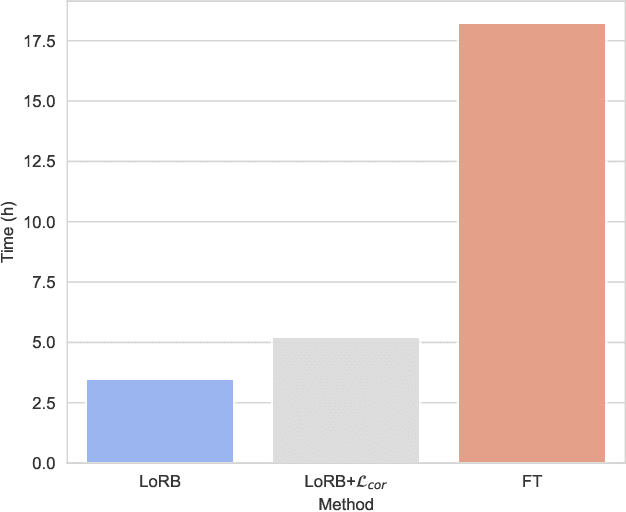
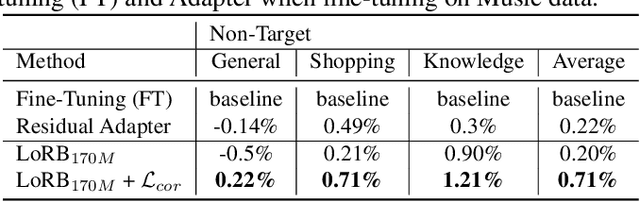
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Personalization for BERT-based Discriminative Speech Recognition Rescoring
Jul 13, 2023



Recognition of personalized content remains a challenge in end-to-end speech recognition. We explore three novel approaches that use personalized content in a neural rescoring step to improve recognition: gazetteers, prompting, and a cross-attention based encoder-decoder model. We use internal de-identified en-US data from interactions with a virtual voice assistant supplemented with personalized named entities to compare these approaches. On a test set with personalized named entities, we show that each of these approaches improves word error rate by over 10%, against a neural rescoring baseline. We also show that on this test set, natural language prompts can improve word error rate by 7% without any training and with a marginal loss in generalization. Overall, gazetteers were found to perform the best with a 10% improvement in word error rate (WER), while also improving WER on a general test set by 1%.