 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback
Nov 04, 2024



While textless Spoken Language Models (SLMs) have shown potential in end-to-end speech-to-speech modeling, they still lag behind text-based Large Language Models (LLMs) in terms of semantic coherence and relevance. This work introduces the Align-SLM framework, which leverages preference optimization inspired by Reinforcement Learning with AI Feedback (RLAIF) to enhance the semantic understanding of SLMs. Our approach generates multiple speech continuations from a given prompt and uses semantic metrics to create preference data for Direct Preference Optimization (DPO). We evaluate the framework using ZeroSpeech 2021 benchmarks for lexical and syntactic modeling, the spoken version of the StoryCloze dataset for semantic coherence, and other speech generation metrics, including the GPT4-o score and human evaluation. Experimental results show that our method achieves state-of-the-art performance for SLMs on most benchmarks, highlighting the importance of preference optimization to improve the semantics of SLMs.
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Sep 25, 2024Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jun 13, 2024



Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Paralinguistics-Enhanced Large Language Modeling of Spoken Dialogue
Jan 17, 2024Large Language Models (LLMs) have demonstrated superior abilities in tasks such as chatting, reasoning, and question-answering. However, standard LLMs may ignore crucial paralinguistic information, such as sentiment, emotion, and speaking style, which are essential for achieving natural, human-like spoken conversation, especially when such information is conveyed by acoustic cues. We therefore propose Paralinguistics-enhanced Generative Pretrained Transformer (ParalinGPT), an LLM that utilizes text and speech modalities to better model the linguistic content and paralinguistic attributes of spoken dialogue. The model takes the conversational context of text, speech embeddings, and paralinguistic attributes as input prompts within a serialized multitasking multimodal framework. Specifically, our framework serializes tasks in the order of current paralinguistic attribute prediction, response paralinguistic attribute prediction, and response text generation with autoregressive conditioning. We utilize the Switchboard-1 corpus, including its sentiment labels as the paralinguistic attribute, as our spoken dialogue dataset. Experimental results indicate the proposed serialized multitasking method outperforms typical sequence classification techniques on current and response sentiment classification. Furthermore, leveraging conversational context and speech embeddings significantly improves both response text generation and sentiment prediction. Our proposed framework achieves relative improvements of 6.7%, 12.0%, and 3.5% in current sentiment accuracy, response sentiment accuracy, and response text BLEU score, respectively.
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024



In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
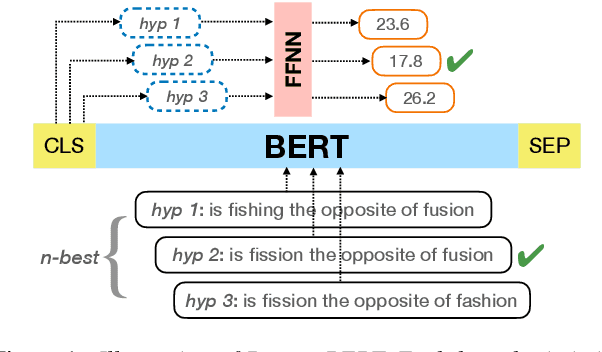
Oct 10, 2023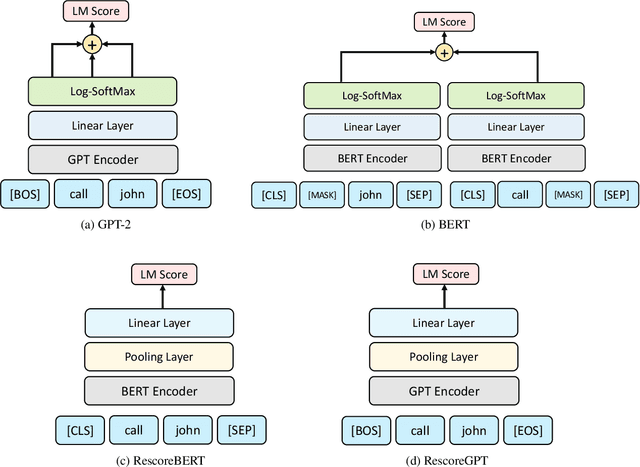
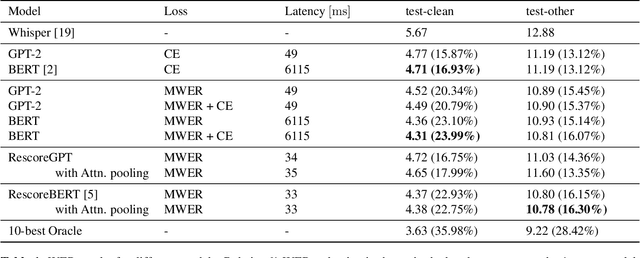
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
Personalization for BERT-based Discriminative Speech Recognition Rescoring
Jul 13, 2023



Recognition of personalized content remains a challenge in end-to-end speech recognition. We explore three novel approaches that use personalized content in a neural rescoring step to improve recognition: gazetteers, prompting, and a cross-attention based encoder-decoder model. We use internal de-identified en-US data from interactions with a virtual voice assistant supplemented with personalized named entities to compare these approaches. On a test set with personalized named entities, we show that each of these approaches improves word error rate by over 10%, against a neural rescoring baseline. We also show that on this test set, natural language prompts can improve word error rate by 7% without any training and with a marginal loss in generalization. Overall, gazetteers were found to perform the best with a 10% improvement in word error rate (WER), while also improving WER on a general test set by 1%.
Scaling Laws for Discriminative Speech Recognition Rescoring Models
Jun 27, 2023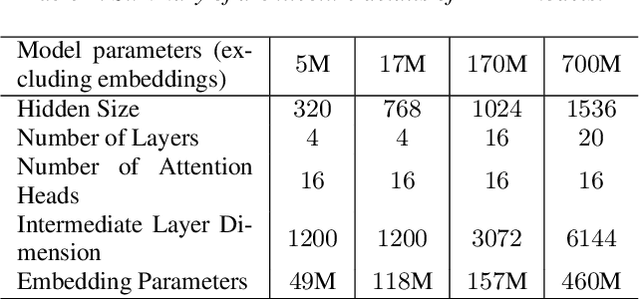
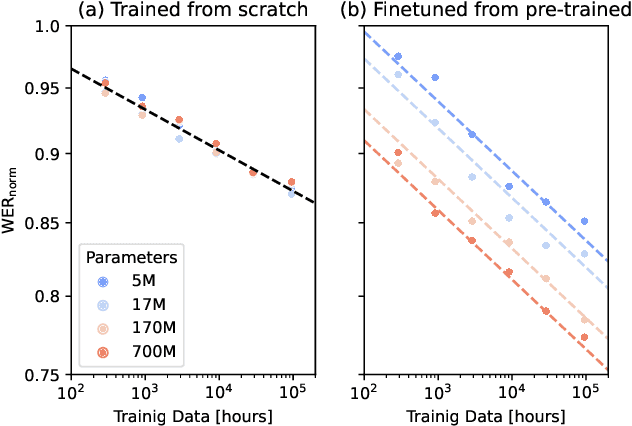
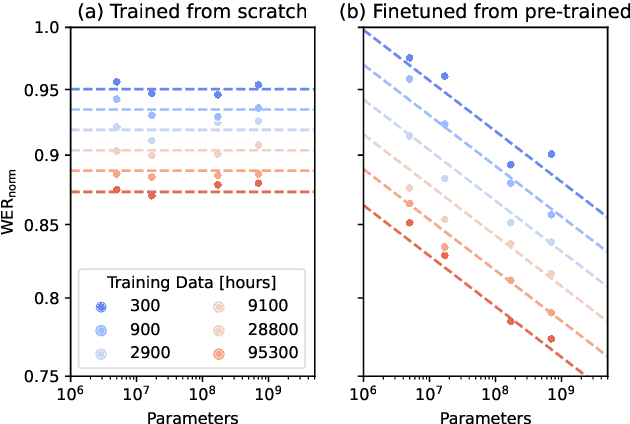
Recent studies have found that model performance has a smooth power-law relationship, or scaling laws, with training data and model size, for a wide range of problems. These scaling laws allow one to choose nearly optimal data and model sizes. We study whether this scaling property is also applicable to second-pass rescoring, which is an important component of speech recognition systems. We focus on RescoreBERT as the rescoring model, which uses a pre-trained Transformer-based architecture fined tuned with an ASR discriminative loss. Using such a rescoring model, we show that the word error rate (WER) follows a scaling law for over two orders of magnitude as training data and model size increase. In addition, it is found that a pre-trained model would require less data than a randomly initialized model of the same size, representing effective data transferred from pre-training step. This effective data transferred is found to also follow a scaling law with the data and model size.
Distillation Strategies for Discriminative Speech Recognition Rescoring
Jun 15, 2023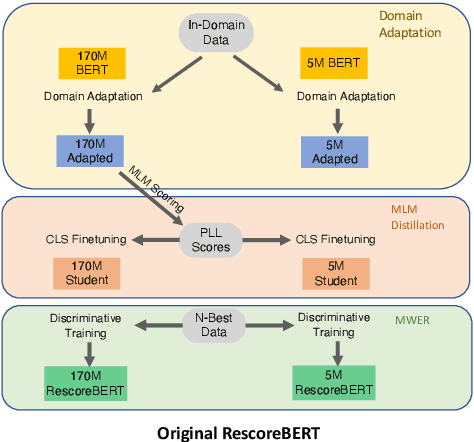
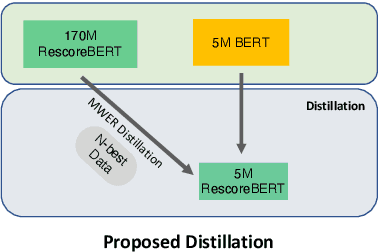
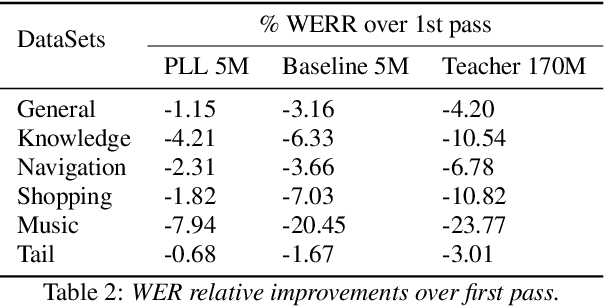
Second-pass rescoring is employed in most state-of-the-art speech recognition systems. Recently, BERT based models have gained popularity for re-ranking the n-best hypothesis by exploiting the knowledge from masked language model pre-training. Further, fine-tuning with discriminative loss such as minimum word error rate (MWER) has shown to perform better than likelihood-based loss. Streaming applications with low latency requirements impose significant constraints on the size of the models, thereby limiting the word error rate (WER) performance gains. In this paper, we propose effective strategies for distilling from large models discriminatively trained with the MWER objective. We experiment on Librispeech and production scale internal dataset for voice-assistant. Our results demonstrate relative improvements of upto 7% WER over student models trained with MWER. We also show that the proposed distillation can reduce the WER gap between the student and the teacher by 62% upto 100%.
Phone Duration Modeling for Speaker Age Estimation in Children
Sep 03, 2021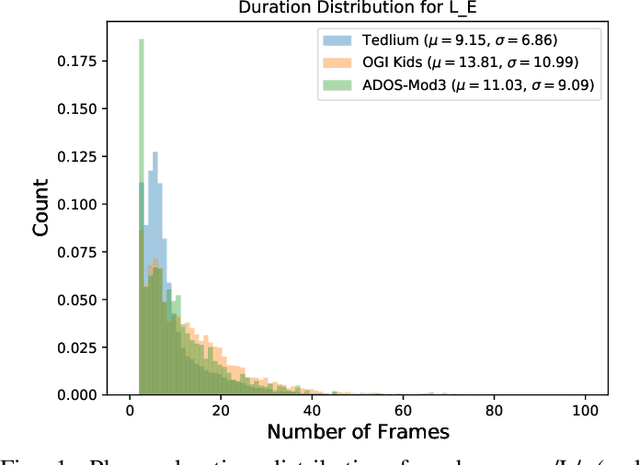
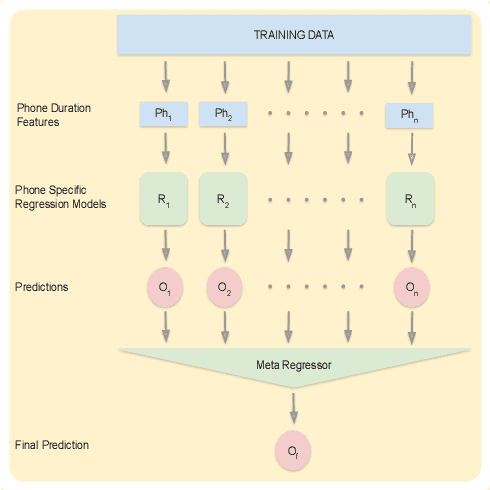
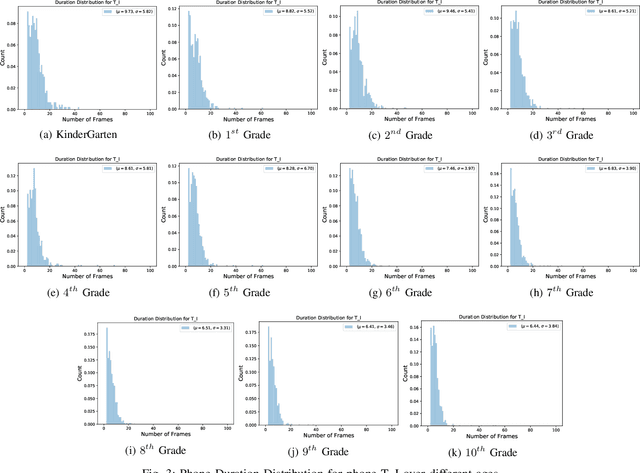
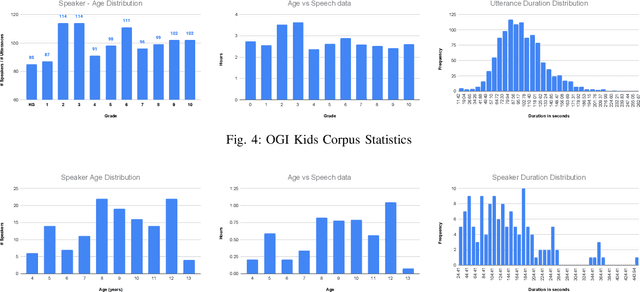
Automatic inference of important paralinguistic information such as age from speech is an important area of research with numerous spoken language technology based applications. Speaker age estimation has applications in enabling personalization and age-appropriate curation of information and content. However, research in speaker age estimation in children is especially challenging due to paucity of relevant speech data representing the developmental spectrum, and the high signal variability especially intra age variability that complicates modeling. Most approaches in children speaker age estimation adopt methods directly from research on adult speech processing. In this paper, we propose features specific to children and focus on speaker's phone duration as an important biomarker of children's age. We propose phone duration modeling for predicting age from child's speech. To enable that, children speech is first forced aligned with the corresponding transcription to derive phone duration distributions. Statistical functionals are computed from phone duration distributions for each phoneme which are in turn used to train regression models to predict speaker age. Two children speech datasets are employed to demonstrate the robustness of phone duration features. We perform age regression experiments on age categories ranging from children studying in kindergarten to grade 10. Experimental results suggest phone durations contain important development-related information of children. Phonemes contributing most to estimation of children speaker age are analyzed and presented.