 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Speech-Text Gap with Limited Audio for Effective Domain Adaptation in LLM-Based ASR
Apr 07, 2026Conventional end-to-end automatic speech recognition (ASR) systems rely on paired speech-text data for domain adaptation. Recent LLM-based ASR architectures connect a speech encoder to a large language model via a projection module, enabling adaptation with text-only data. However, this introduces a modality gap, as the LLM is not exposed to the noisy representations produced by the speech projector. We investigate whether small amounts of speech can mitigate this mismatch. We compare three strategies: text-only adaptation, paired speech-text adaptation, and mixed batching (MB), which combines both. Experiments in in-domain and out-of-domain settings show that even limited speech consistently improves performance. Notably, MB using only 10% of the target-domain (less than 4 hours) speech achieves word error rates comparable to, or better than, conventional ASR fine-tuning with the full dataset, indicating that small amounts of speech provide a strong modality-alignment signal.
Distilling Conversations: Abstract Compression of Conversational Audio Context for LLM-based ASR
Mar 27, 2026Standard LLM-based speech recognition systems typically process utterances in isolation, limiting their ability to leverage conversational context. In this work, we study whether multimodal context from prior turns improves LLM-based ASR and how to represent that context efficiently. We find that, after supervised multi-turn training, conversational context mainly helps with the recognition of contextual entities. However, conditioning on raw context is expensive because the prior-turn audio token sequence grows rapidly with conversation length. To address this, we propose Abstract Compression, which replaces the audio portion of prior turns with a fixed number of learned latent tokens while retaining corresponding transcripts explicitly. On both in-domain and out-of-domain test sets, the compressed model recovers part of the gains of raw-context conditioning with a smaller prior-turn audio footprint. We also provide targeted analyses of the compression setup and its trade-offs.
Text-only adaptation in LLM-based ASR through text denoising
Jan 28, 2026Adapting automatic speech recognition (ASR) systems based on large language models (LLMs) to new domains using text-only data is a significant yet underexplored challenge. Standard fine-tuning of the LLM on target-domain text often disrupts the critical alignment between speech and text modalities learned by the projector, degrading performance. We introduce a novel text-only adaptation method that emulates the audio projection task by treating it as a text denoising task. Our approach thus trains the LLM to recover clean transcripts from noisy inputs. This process effectively adapts the model to a target domain while preserving cross-modal alignment. Our solution is lightweight, requiring no architectural changes or additional parameters. Extensive evaluation on two datasets demonstrates up to 22.1% relative improvement, outperforming recent state-of-the-art text-only adaptation methods.
Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
Jan 28, 2026LLM-based automatic speech recognition (ASR), a well-established approach, connects speech foundation models to large language models (LLMs) through a speech-to-LLM projector, yielding promising results. A common design choice in these architectures is the use of a fixed, manually defined prompt during both training and inference. This setup not only enables applicability across a range of practical scenarios, but also helps maximize model performance. However, the impact of prompt design remains underexplored. This paper presents a comprehensive analysis of commonly used prompts across diverse datasets, showing that prompt choice significantly affects ASR performance and introduces instability, with no single prompt performing best across all cases. Inspired by the speech-to-LLM projector, we propose a prompt projector module, a simple, model-agnostic extension that learns to project prompt embeddings to more effective regions of the LLM input space, without modifying the underlying LLM-based ASR model. Experiments on four datasets show that the addition of a prompt projector consistently improves performance, reduces variability, and outperforms the best manually selected prompts.
Slot Filling as a Reasoning Task for SpeechLLMs
Oct 22, 2025We propose integration of reasoning into speech large language models (speechLLMs) for the end-to-end slot-filling task. Inspired by the recent development of reasoning LLMs, we use a chain-of-thought framework to decompose the slot-filling task into multiple reasoning steps, create a reasoning dataset and apply the supervised fine-tuning strategy to a speechLLM. We distinguish between regular and reasoning speechLLMs and experiment with different types and sizes of LLMs as their text foundation models. We demonstrate performance improvements by introducing reasoning (intermediate) steps. However, we show that a reasoning textual LLM developed mainly for math, logic and coding domains might be inferior as a foundation model for a reasoning speechLLM. We further show that hybrid speechLLMs, built on a hybrid text foundation LLM and fine-tuned to preserve both direct and reasoning modes of operation, have better performance than those fine-tuned employing only one mode of operation.
TokenVerse++: Towards Flexible Multitask Learning with Dynamic Task Activation
Aug 27, 2025Token-based multitasking frameworks like TokenVerse require all training utterances to have labels for all tasks, hindering their ability to leverage partially annotated datasets and scale effectively. We propose TokenVerse++, which introduces learnable vectors in the acoustic embedding space of the XLSR-Transducer ASR model for dynamic task activation. This core mechanism enables training with utterances labeled for only a subset of tasks, a key advantage over TokenVerse. We demonstrate this by successfully integrating a dataset with partial labels, specifically for ASR and an additional task, language identification, improving overall performance. TokenVerse++ achieves results on par with or exceeding TokenVerse across multiple tasks, establishing it as a more practical multitask alternative without sacrificing ASR performance.
Unifying Streaming and Non-streaming Zipformer-based ASR
Jun 17, 2025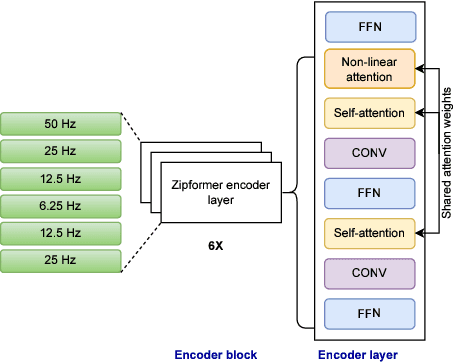
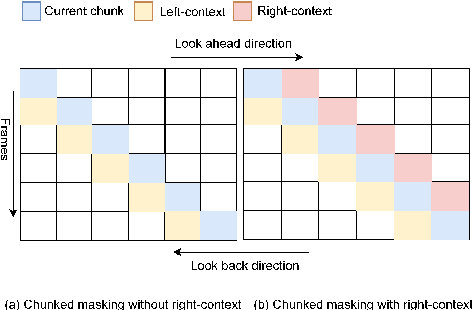
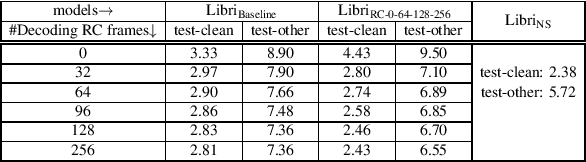
There has been increasing interest in unifying streaming and non-streaming automatic speech recognition (ASR) models to reduce development, training, and deployment costs. We present a unified framework that trains a single end-to-end ASR model for both streaming and non-streaming applications, leveraging future context information. We propose to use dynamic right-context through the chunked attention masking in the training of zipformer-based ASR models. We demonstrate that using right-context is more effective in zipformer models compared to other conformer models due to its multi-scale nature. We analyze the effect of varying the number of right-context frames on accuracy and latency of the streaming ASR models. We use Librispeech and large in-house conversational datasets to train different versions of streaming and non-streaming models and evaluate them in a production grade server-client setup across diverse testsets of different domains. The proposed strategy reduces word error by relative 7.9\% with a small degradation in user-perceived latency. By adding more right-context frames, we are able to achieve streaming performance close to that of non-streaming models. Our approach also allows flexible control of the latency-accuracy tradeoff according to customers requirements.
Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025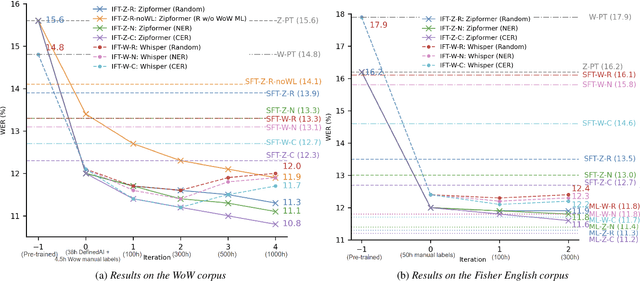
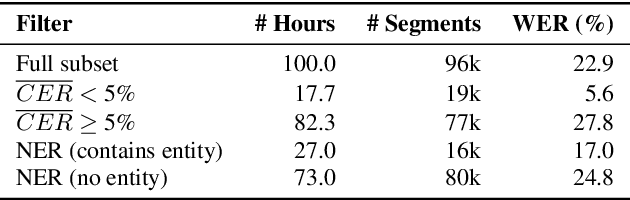

Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.
Improving speaker verification robustness with synthetic emotional utterances
Nov 30, 2024



A speaker verification (SV) system offers an authentication service designed to confirm whether a given speech sample originates from a specific speaker. This technology has paved the way for various personalized applications that cater to individual preferences. A noteworthy challenge faced by SV systems is their ability to perform consistently across a range of emotional spectra. Most existing models exhibit high error rates when dealing with emotional utterances compared to neutral ones. Consequently, this phenomenon often leads to missing out on speech of interest. This issue primarily stems from the limited availability of labeled emotional speech data, impeding the development of robust speaker representations that encompass diverse emotional states. To address this concern, we propose a novel approach employing the CycleGAN framework to serve as a data augmentation method. This technique synthesizes emotional speech segments for each specific speaker while preserving the unique vocal identity. Our experimental findings underscore the effectiveness of incorporating synthetic emotional data into the training process. The models trained using this augmented dataset consistently outperform the baseline models on the task of verifying speakers in emotional speech scenarios, reducing equal error rate by as much as 3.64% relative.
Lightweight Safety Guardrails Using Fine-tuned BERT Embeddings
Nov 21, 2024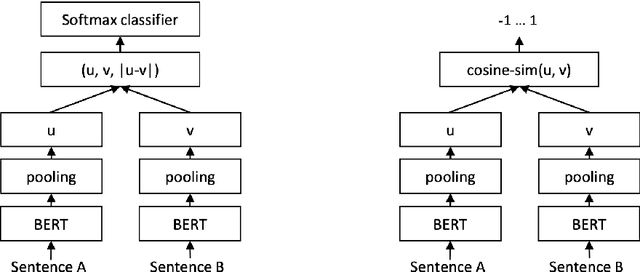

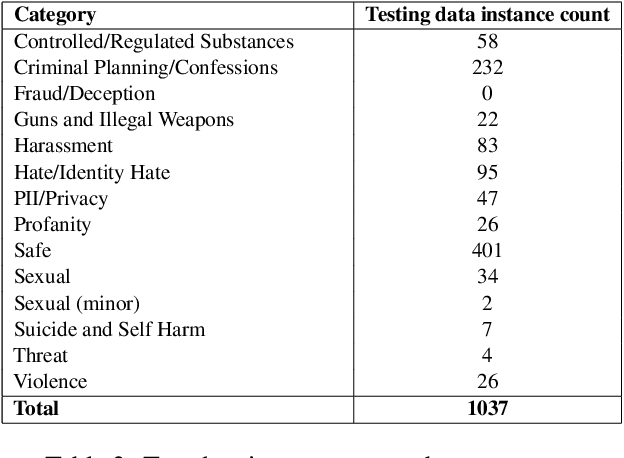
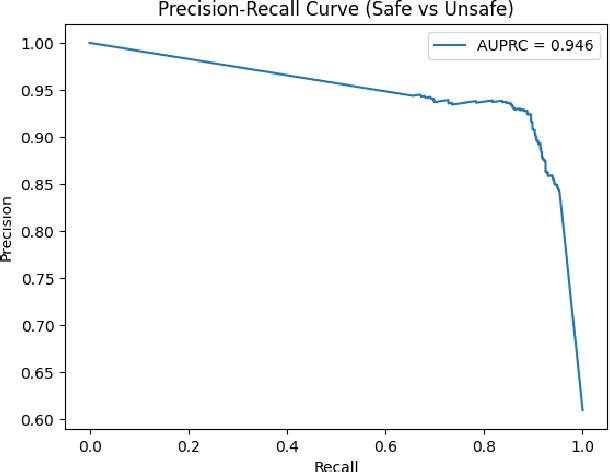
With the recent proliferation of large language models (LLMs), enterprises have been able to rapidly develop proof-of-concepts and prototypes. As a result, there is a growing need to implement robust guardrails that monitor, quantize and control an LLM's behavior, ensuring that the use is reliable, safe, accurate and also aligned with the users' expectations. Previous approaches for filtering out inappropriate user prompts or system outputs, such as LlamaGuard and OpenAI's MOD API, have achieved significant success by fine-tuning existing LLMs. However, using fine-tuned LLMs as guardrails introduces increased latency and higher maintenance costs, which may not be practical or scalable for cost-efficient deployments. We take a different approach, focusing on fine-tuning a lightweight architecture: Sentence-BERT. This method reduces the model size from LlamaGuard's 7 billion parameters to approximately 67 million, while maintaining comparable performance on the AEGIS safety benchmark.