 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Slot Filling in the Age of LLMs for Dialogue Systems
Nov 28, 2024Zero-shot slot filling is a well-established subtask of Natural Language Understanding (NLU). However, most existing methods primarily focus on single-turn text data, overlooking the unique complexities of conversational dialogue. Conversational data is highly dynamic, often involving abrupt topic shifts, interruptions, and implicit references that make it difficult to directly apply zero-shot slot filling techniques, even with the remarkable capabilities of large language models (LLMs). This paper addresses these challenges by proposing strategies for automatic data annotation with slot induction and black-box knowledge distillation (KD) from a teacher LLM to a smaller model, outperforming vanilla LLMs on internal datasets by 26% absolute increase in F1 score. Additionally, we introduce an efficient system architecture for call center product settings that surpasses off-the-shelf extractive models by 34% relative F1 score, enabling near real-time inference on dialogue streams with higher accuracy, while preserving low latency.
Lightweight Safety Guardrails Using Fine-tuned BERT Embeddings
Nov 21, 2024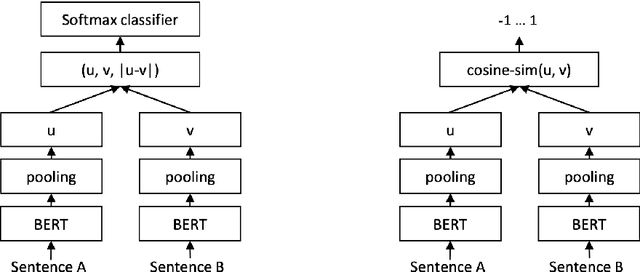

With the recent proliferation of large language models (LLMs), enterprises have been able to rapidly develop proof-of-concepts and prototypes. As a result, there is a growing need to implement robust guardrails that monitor, quantize and control an LLM's behavior, ensuring that the use is reliable, safe, accurate and also aligned with the users' expectations. Previous approaches for filtering out inappropriate user prompts or system outputs, such as LlamaGuard and OpenAI's MOD API, have achieved significant success by fine-tuning existing LLMs. However, using fine-tuned LLMs as guardrails introduces increased latency and higher maintenance costs, which may not be practical or scalable for cost-efficient deployments. We take a different approach, focusing on fine-tuning a lightweight architecture: Sentence-BERT. This method reduces the model size from LlamaGuard's 7 billion parameters to approximately 67 million, while maintaining comparable performance on the AEGIS safety benchmark.