 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Safety Guardrails Using Fine-tuned BERT Embeddings
Paper and Code
Nov 21, 2024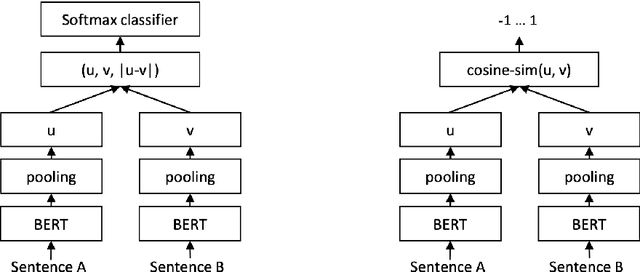

With the recent proliferation of large language models (LLMs), enterprises have been able to rapidly develop proof-of-concepts and prototypes. As a result, there is a growing need to implement robust guardrails that monitor, quantize and control an LLM's behavior, ensuring that the use is reliable, safe, accurate and also aligned with the users' expectations. Previous approaches for filtering out inappropriate user prompts or system outputs, such as LlamaGuard and OpenAI's MOD API, have achieved significant success by fine-tuning existing LLMs. However, using fine-tuned LLMs as guardrails introduces increased latency and higher maintenance costs, which may not be practical or scalable for cost-efficient deployments. We take a different approach, focusing on fine-tuning a lightweight architecture: Sentence-BERT. This method reduces the model size from LlamaGuard's 7 billion parameters to approximately 67 million, while maintaining comparable performance on the AEGIS safety benchmark.