 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Actions Teach You to Think: Reasoning-Action Synergy via Reinforcement Learning in Conversational Agents
Dec 12, 2025Supervised fine-tuning (SFT) has emerged as one of the most effective ways to improve the performance of large language models (LLMs) in downstream tasks. However, SFT can have difficulty generalizing when the underlying data distribution changes, even when the new data does not fall completely outside the training domain. Recent reasoning-focused models such as o1 and R1 have demonstrated consistent gains over their non-reasoning counterparts, highlighting the importance of reasoning for improved generalization and reliability. However, collecting high-quality reasoning traces for SFT remains challenging -- annotations are costly, subjective, and difficult to scale. To address this limitation, we leverage Reinforcement Learning (RL) to enable models to learn reasoning strategies directly from task outcomes. We propose a pipeline in which LLMs generate reasoning steps that guide both the invocation of tools (e.g., function calls) and the final answer generation for conversational agents. Our method employs Group Relative Policy Optimization (GRPO) with rewards designed around tool accuracy and answer correctness, allowing the model to iteratively refine its reasoning and actions. Experimental results demonstrate that our approach improves both the quality of reasoning and the precision of tool invocations, achieving a 1.5% relative improvement over the SFT model (trained without explicit thinking) and a 40% gain compared to the base of the vanilla Qwen3-1.7B model. These findings demonstrate the promise of unifying reasoning and action learning through RL to build more capable and generalizable conversational agents.
Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents
May 15, 2025The ReAct (Reasoning + Action) capability in large language models (LLMs) has become the foundation of modern agentic systems. Recent LLMs, such as DeepSeek-R1 and OpenAI o1/o3, exemplify this by emphasizing reasoning through the generation of ample intermediate tokens, which help build a strong premise before producing the final output tokens. In this paper, we introduce Pre-Act, a novel approach that enhances the agent's performance by creating a multi-step execution plan along with the detailed reasoning for the given user input. This plan incrementally incorporates previous steps and tool outputs, refining itself after each step execution until the final response is obtained. Our approach is applicable to both conversational and non-conversational agents. To measure the performance of task-oriented agents comprehensively, we propose a two-level evaluation framework: (1) turn level and (2) end-to-end. Our turn-level evaluation, averaged across five models, shows that our approach, Pre-Act, outperforms ReAct by 70% in Action Recall on the Almita dataset. While this approach is effective for larger models, smaller models crucial for practical applications, where latency and cost are key constraints, often struggle with complex reasoning tasks required for agentic systems. To address this limitation, we fine-tune relatively small models such as Llama 3.1 (8B & 70B) using the proposed Pre-Act approach. Our experiments show that the fine-tuned 70B model outperforms GPT-4, achieving a 69.5% improvement in action accuracy (turn-level) and a 28% improvement in goal completion rate (end-to-end) on the Almita (out-of-domain) dataset.
Controllable Discovery of Intents: Incremental Deep Clustering Using Semi-Supervised Contrastive Learning
Oct 18, 2024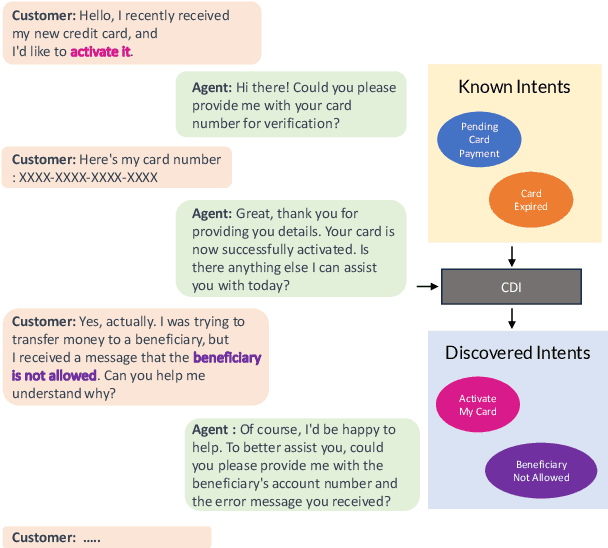
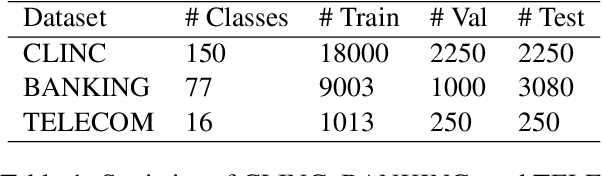
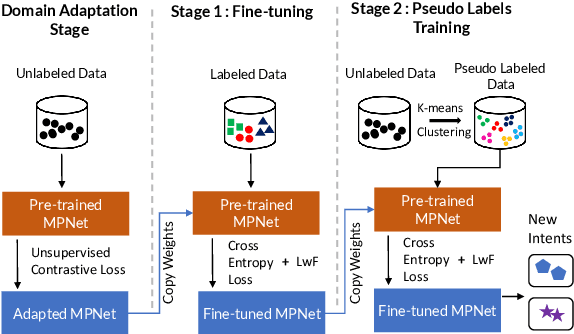

Deriving value from a conversational AI system depends on the capacity of a user to translate the prior knowledge into a configuration. In most cases, discovering the set of relevant turn-level speaker intents is often one of the key steps. Purely unsupervised algorithms provide a natural way to tackle discovery problems but make it difficult to incorporate constraints and only offer very limited control over the outcomes. Previous work has shown that semi-supervised (deep) clustering techniques can allow the system to incorporate prior knowledge and constraints in the intent discovery process. However they did not address how to allow for control through human feedback. In our Controllable Discovery of Intents (CDI) framework domain and prior knowledge are incorporated using a sequence of unsupervised contrastive learning on unlabeled data followed by fine-tuning on partially labeled data, and finally iterative refinement of clustering and representations through repeated clustering and pseudo-label fine-tuning. In addition, we draw from continual learning literature and use learning-without-forgetting to prevent catastrophic forgetting across those training stages. Finally, we show how this deep-clustering process can become part of an incremental discovery strategy with human-in-the-loop. We report results on both CLINC and BANKING datasets. CDI outperforms previous works by a significant margin: 10.26% and 11.72% respectively.
REFINE on Scarce Data: Retrieval Enhancement through Fine-Tuning via Model Fusion of Embedding Models
Oct 16, 2024



Retrieval augmented generation (RAG) pipelines are commonly used in tasks such as question-answering (QA), relying on retrieving relevant documents from a vector store computed using a pretrained embedding model. However, if the retrieved context is inaccurate, the answers generated using the large language model (LLM) may contain errors or hallucinations. Although pretrained embedding models have advanced, adapting them to new domains remains challenging. Fine-tuning is a potential solution, but industry settings often lack the necessary fine-tuning data. To address these challenges, we propose REFINE, a novel technique that generates synthetic data from available documents and then uses a model fusion approach to fine-tune embeddings for improved retrieval performance in new domains, while preserving out-of-domain capability. We conducted experiments on the two public datasets: SQUAD and RAG-12000 and a proprietary TOURISM dataset. Results demonstrate that even the standard fine-tuning with the proposed data augmentation technique outperforms the vanilla pretrained model. Furthermore, when combined with model fusion, the proposed approach achieves superior performance, with a 5.76% improvement in recall on the TOURISM dataset, and 6.58 % and 0.32% enhancement on SQUAD and RAG-12000 respectively.
Real-time Caller Intent Detection In Human-Human Customer Support Spoken Conversations
Aug 14, 2022
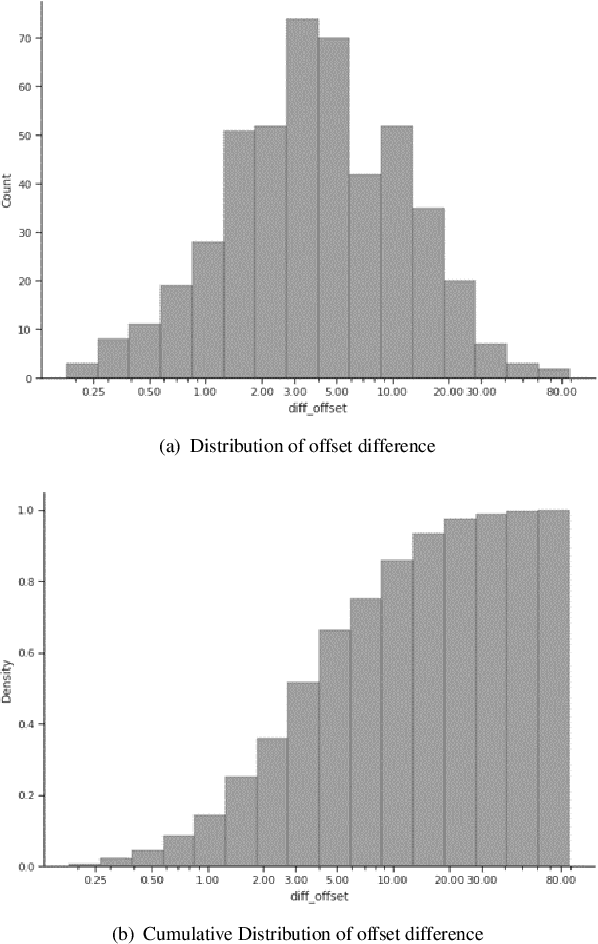


Agent assistance during human-human customer support spoken interactions requires triggering workflows based on the caller's intent (reason for call). Timeliness of prediction is essential for a good user experience. The goal is for a system to detect the caller's intent at the time the agent would have been able to detect it (Intent Boundary). Some approaches focus on predicting the output offline, i.e. once the full spoken input (e.g. the whole conversational turn) has been processed by the ASR system. This introduces an undesirable latency in the prediction each time the intent could have been detected earlier in the turn. Recent work on voice assistants has used incremental real-time predictions at a word-by-word level to detect intent before the end of a command. Human-directed and machine-directed speech however have very different characteristics. In this work, we propose to apply a method developed in the context of voice-assistant to the problem of online real time caller's intent detection in human-human spoken interactions. We use a dual architecture in which two LSTMs are jointly trained: one predicting the Intent Boundary (IB) and then other predicting the intent class at the IB. We conduct our experiments on our private dataset comprising transcripts of human-human telephone conversations from the telecom customer support domain. We report results analyzing both the accuracy of our system as well as the impact of different architectures on the trade off between overall accuracy and prediction latency.
Automated Evidence Collection for Fake News Detection
Dec 13, 2021



Fake news, misinformation, and unverifiable facts on social media platforms propagate disharmony and affect society, especially when dealing with an epidemic like COVID-19. The task of Fake News Detection aims to tackle the effects of such misinformation by classifying news items as fake or real. In this paper, we propose a novel approach that improves over the current automatic fake news detection approaches by automatically gathering evidence for each claim. Our approach extracts supporting evidence from the web articles and then selects appropriate text to be treated as evidence sets. We use a pre-trained summarizer on these evidence sets and then use the extracted summary as supporting evidence to aid the classification task. Our experiments, using both machine learning and deep learning-based methods, help perform an extensive evaluation of our approach. The results show that our approach outperforms the state-of-the-art methods in fake news detection to achieve an F1-score of 99.25 over the dataset provided for the CONSTRAINT-2021 Shared Task. We also release the augmented dataset, our code and models for any further research.
PnPOOD : Out-Of-Distribution Detection for Text Classification via Plug andPlay Data Augmentation
Oct 31, 2021



While Out-of-distribution (OOD) detection has been well explored in computer vision, there have been relatively few prior attempts in OOD detection for NLP classification. In this paper we argue that these prior attempts do not fully address the OOD problem and may suffer from data leakage and poor calibration of the resulting models. We present PnPOOD, a data augmentation technique to perform OOD detection via out-of-domain sample generation using the recently proposed Plug and Play Language Model (Dathathri et al., 2020). Our method generates high quality discriminative samples close to the class boundaries, resulting in accurate OOD detection at test time. We demonstrate that our model outperforms prior models on OOD sample detection, and exhibits lower calibration error on the 20 newsgroup text and Stanford Sentiment Treebank dataset (Lang, 1995; Socheret al., 2013). We further highlight an important data leakage issue with datasets used in prior attempts at OOD detection, and share results on a new dataset for OOD detection that does not suffer from the same problem.