 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvenance: A Light-weight Fact-checker for Retrieval Augmented LLM Generation Output
Nov 01, 2024We present a light-weight approach for detecting nonfactual outputs from retrieval-augmented generation (RAG). Given a context and putative output, we compute a factuality score that can be thresholded to yield a binary decision to check the results of LLM-based question-answering, summarization, or other systems. Unlike factuality checkers that themselves rely on LLMs, we use compact, open-source natural language inference (NLI) models that yield a freely accessible solution with low latency and low cost at run-time, and no need for LLM fine-tuning. The approach also enables downstream mitigation and correction of hallucinations, by tracing them back to specific context chunks. Our experiments show high area under the ROC curve (AUC) across a wide range of relevant open source datasets, indicating the effectiveness of our method for fact-checking RAG output.
Controllable Discovery of Intents: Incremental Deep Clustering Using Semi-Supervised Contrastive Learning
Oct 18, 2024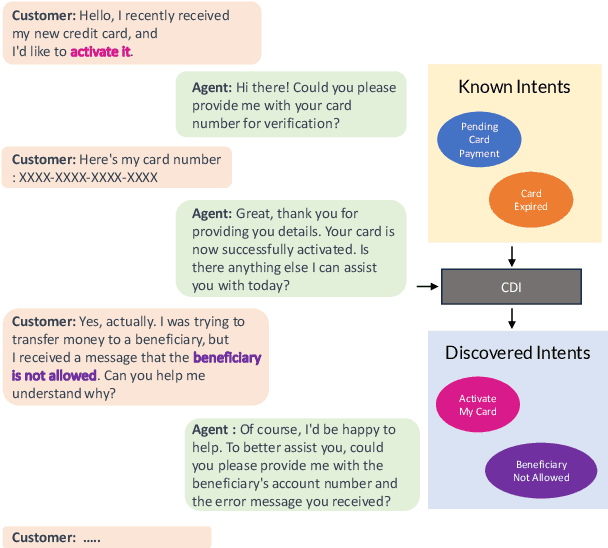
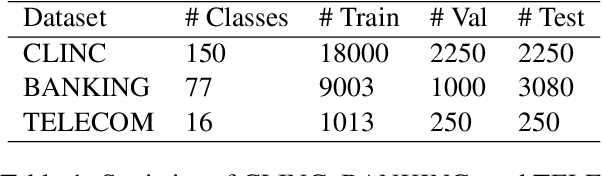
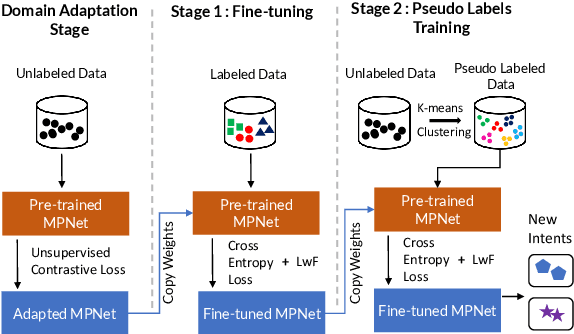

Deriving value from a conversational AI system depends on the capacity of a user to translate the prior knowledge into a configuration. In most cases, discovering the set of relevant turn-level speaker intents is often one of the key steps. Purely unsupervised algorithms provide a natural way to tackle discovery problems but make it difficult to incorporate constraints and only offer very limited control over the outcomes. Previous work has shown that semi-supervised (deep) clustering techniques can allow the system to incorporate prior knowledge and constraints in the intent discovery process. However they did not address how to allow for control through human feedback. In our Controllable Discovery of Intents (CDI) framework domain and prior knowledge are incorporated using a sequence of unsupervised contrastive learning on unlabeled data followed by fine-tuning on partially labeled data, and finally iterative refinement of clustering and representations through repeated clustering and pseudo-label fine-tuning. In addition, we draw from continual learning literature and use learning-without-forgetting to prevent catastrophic forgetting across those training stages. Finally, we show how this deep-clustering process can become part of an incremental discovery strategy with human-in-the-loop. We report results on both CLINC and BANKING datasets. CDI outperforms previous works by a significant margin: 10.26% and 11.72% respectively.