 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting End User Queries to Enterprise Databases
Jan 27, 2026We address the task of routing natural language queries in multi-database enterprise environments. We construct realistic benchmarks by extending existing NL-to-SQL datasets. Our study shows that routing becomes increasingly challenging with larger, domain-overlapping DB repositories and ambiguous queries, motivating the need for more structured and robust reasoning-based solutions. By explicitly modelling schema coverage, structural connectivity, and fine-grained semantic alignment, the proposed modular, reasoning-driven reranking strategy consistently outperforms embedding-only and direct LLM-prompting baselines across all the metrics.
Refine and Align: Confidence Calibration through Multi-Agent Interaction in VQA
Nov 14, 2025In the context of Visual Question Answering (VQA) and Agentic AI, calibration refers to how closely an AI system's confidence in its answers reflects their actual correctness. This aspect becomes especially important when such systems operate autonomously and must make decisions under visual uncertainty. While modern VQA systems, powered by advanced vision-language models (VLMs), are increasingly used in high-stakes domains like medical diagnostics and autonomous navigation due to their improved accuracy, the reliability of their confidence estimates remains under-examined. Particularly, these systems often produce overconfident responses. To address this, we introduce AlignVQA, a debate-based multi-agent framework, in which diverse specialized VLM -- each following distinct prompting strategies -- generate candidate answers and then engage in two-stage interaction: generalist agents critique, refine and aggregate these proposals. This debate process yields confidence estimates that more accurately reflect the model's true predictive performance. We find that more calibrated specialized agents produce better aligned confidences. Furthermore, we introduce a novel differentiable calibration-aware loss function called aligncal designed to fine-tune the specialized agents by minimizing an upper bound on the calibration error. This objective explicitly improves the fidelity of each agent's confidence estimates. Empirical results across multiple benchmark VQA datasets substantiate the efficacy of our approach, demonstrating substantial reductions in calibration discrepancies. Furthermore, we propose a novel differentiable calibration-aware loss to fine-tune the specialized agents and improve the quality of their individual confidence estimates based on minimising upper bound calibration error.
AbGen: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research
Jul 17, 2025We introduce AbGen, the first benchmark designed to evaluate the capabilities of LLMs in designing ablation studies for scientific research. AbGen consists of 1,500 expert-annotated examples derived from 807 NLP papers. In this benchmark, LLMs are tasked with generating detailed ablation study designs for a specified module or process based on the given research context. Our evaluation of leading LLMs, such as DeepSeek-R1-0528 and o4-mini, highlights a significant performance gap between these models and human experts in terms of the importance, faithfulness, and soundness of the ablation study designs. Moreover, we demonstrate that current automated evaluation methods are not reliable for our task, as they show a significant discrepancy when compared to human assessment. To better investigate this, we develop AbGen-Eval, a meta-evaluation benchmark designed to assess the reliability of commonly used automated evaluation systems in measuring LLM performance on our task. We investigate various LLM-as-Judge systems on AbGen-Eval, providing insights for future research on developing more effective and reliable LLM-based evaluation systems for complex scientific tasks.
Can LLMs Identify Critical Limitations within Scientific Research? A Systematic Evaluation on AI Research Papers
Jul 03, 2025Peer review is fundamental to scientific research, but the growing volume of publications has intensified the challenges of this expertise-intensive process. While LLMs show promise in various scientific tasks, their potential to assist with peer review, particularly in identifying paper limitations, remains understudied. We first present a comprehensive taxonomy of limitation types in scientific research, with a focus on AI. Guided by this taxonomy, for studying limitations, we present LimitGen, the first comprehensive benchmark for evaluating LLMs' capability to support early-stage feedback and complement human peer review. Our benchmark consists of two subsets: LimitGen-Syn, a synthetic dataset carefully created through controlled perturbations of high-quality papers, and LimitGen-Human, a collection of real human-written limitations. To improve the ability of LLM systems to identify limitations, we augment them with literature retrieval, which is essential for grounding identifying limitations in prior scientific findings. Our approach enhances the capabilities of LLM systems to generate limitations in research papers, enabling them to provide more concrete and constructive feedback.
OrienText: Surface Oriented Textual Image Generation
May 27, 2025Textual content in images is crucial in e-commerce sectors, particularly in marketing campaigns, product imaging, advertising, and the entertainment industry. Current text-to-image (T2I) generation diffusion models, though proficient at producing high-quality images, often struggle to incorporate text accurately onto complex surfaces with varied perspectives, such as angled views of architectural elements like buildings, banners, or walls. In this paper, we introduce the Surface Oriented Textual Image Generation (OrienText) method, which leverages region-specific surface normals as conditional input to T2I generation diffusion model. Our approach ensures accurate rendering and correct orientation of the text within the image context. We demonstrate the effectiveness of the OrienText method on a self-curated dataset of images and compare it against the existing textual image generation methods.
ResearchCodeAgent: An LLM Multi-Agent System for Automated Codification of Research Methodologies
Apr 28, 2025
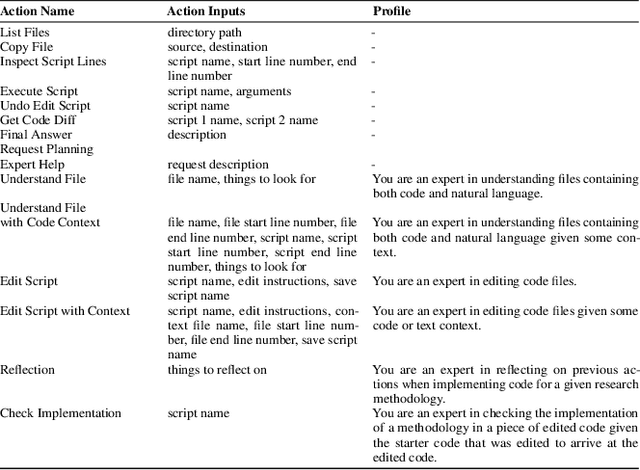
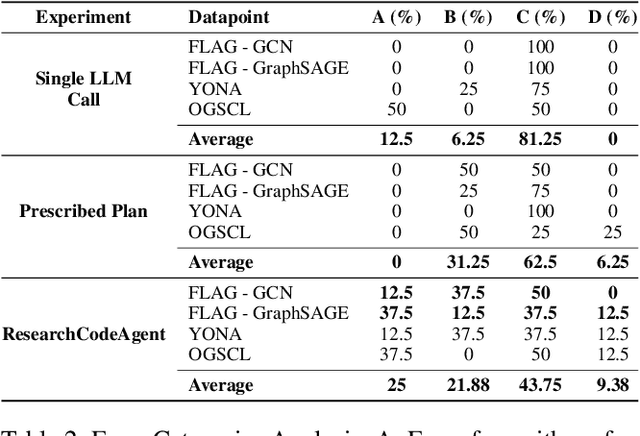
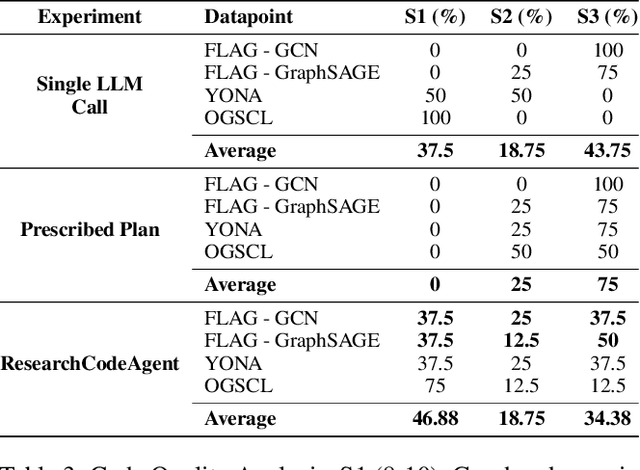
In this paper we introduce ResearchCodeAgent, a novel multi-agent system leveraging large language models (LLMs) agents to automate the codification of research methodologies described in machine learning literature. The system bridges the gap between high-level research concepts and their practical implementation, allowing researchers auto-generating code of existing research papers for benchmarking or building on top-of existing methods specified in the literature with availability of partial or complete starter code. ResearchCodeAgent employs a flexible agent architecture with a comprehensive action suite, enabling context-aware interactions with the research environment. The system incorporates a dynamic planning mechanism, utilizing both short and long-term memory to adapt its approach iteratively. We evaluate ResearchCodeAgent on three distinct machine learning tasks with distinct task complexity and representing different parts of the ML pipeline: data augmentation, optimization, and data batching. Our results demonstrate the system's effectiveness and generalizability, with 46.9% of generated code being high-quality and error-free, and 25% showing performance improvements over baseline implementations. Empirical analysis shows an average reduction of 57.9% in coding time compared to manual implementation. We observe higher gains for more complex tasks. ResearchCodeAgent represents a significant step towards automating the research implementation process, potentially accelerating the pace of machine learning research.
IRIS: Interactive Research Ideation System for Accelerating Scientific Discovery
Apr 23, 2025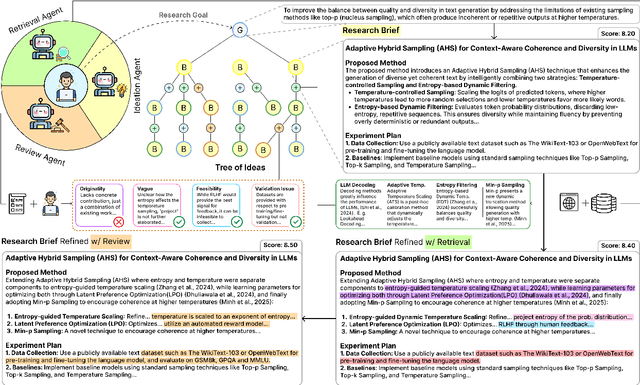
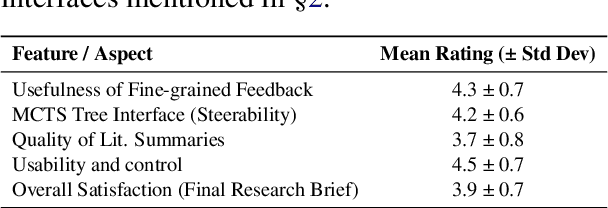
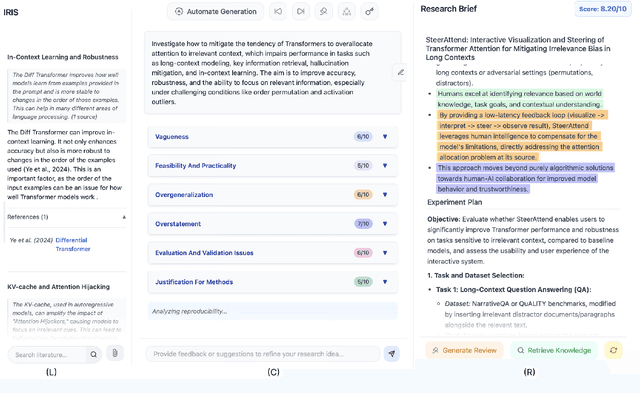
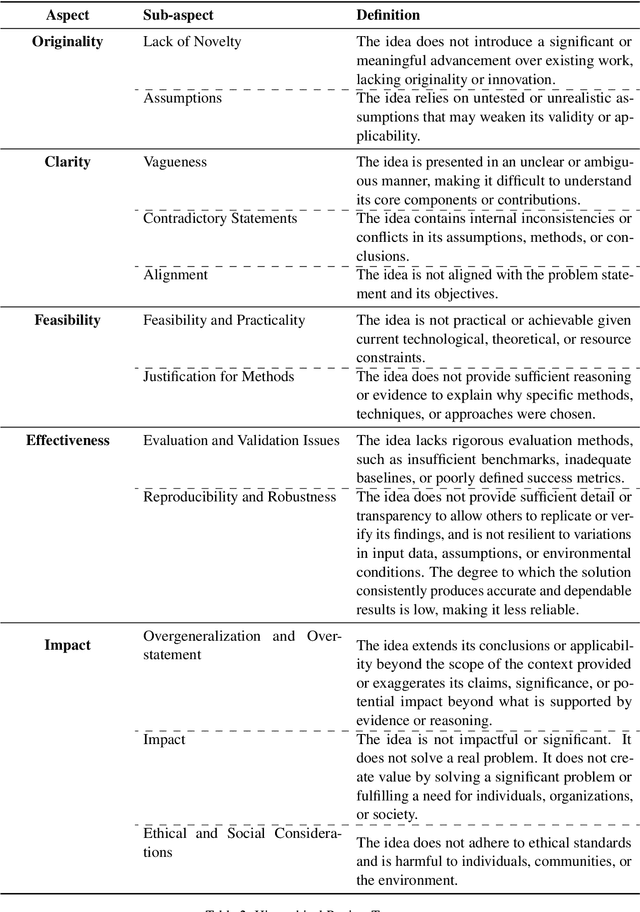
The rapid advancement in capabilities of large language models (LLMs) raises a pivotal question: How can LLMs accelerate scientific discovery? This work tackles the crucial first stage of research, generating novel hypotheses. While recent work on automated hypothesis generation focuses on multi-agent frameworks and extending test-time compute, none of the approaches effectively incorporate transparency and steerability through a synergistic Human-in-the-loop (HITL) approach. To address this gap, we introduce IRIS: Interactive Research Ideation System, an open-source platform designed for researchers to leverage LLM-assisted scientific ideation. IRIS incorporates innovative features to enhance ideation, including adaptive test-time compute expansion via Monte Carlo Tree Search (MCTS), fine-grained feedback mechanism, and query-based literature synthesis. Designed to empower researchers with greater control and insight throughout the ideation process. We additionally conduct a user study with researchers across diverse disciplines, validating the effectiveness of our system in enhancing ideation. We open-source our code at https://github.com/Anikethh/IRIS-Interactive-Research-Ideation-System
DifCluE: Generating Counterfactual Explanations with Diffusion Autoencoders and modal clustering
Feb 17, 2025Generating multiple counterfactual explanations for different modes within a class presents a significant challenge, as these modes are distinct yet converge under the same classification. Diffusion probabilistic models (DPMs) have demonstrated a strong ability to capture the underlying modes of data distributions. In this paper, we harness the power of a Diffusion Autoencoder to generate multiple distinct counterfactual explanations. By clustering in the latent space, we uncover the directions corresponding to the different modes within a class, enabling the generation of diverse and meaningful counterfactuals. We introduce a novel methodology, DifCluE, which consistently identifies these modes and produces more reliable counterfactual explanations. Our experimental results demonstrate that DifCluE outperforms the current state-of-the-art in generating multiple counterfactual explanations, offering a significant advance- ment in model interpretability.
DBRouting: Routing End User Queries to Databases for Answerability
Jan 27, 2025
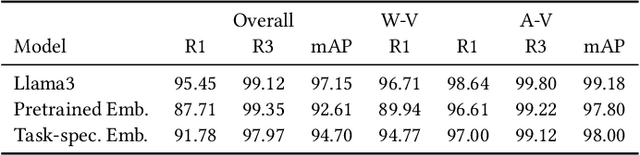
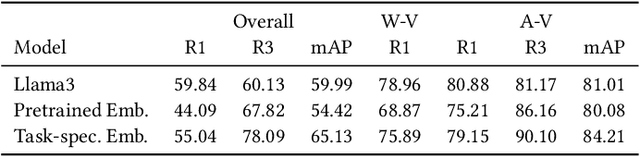
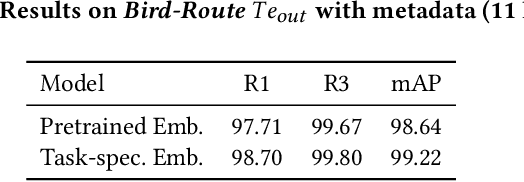
Enterprise level data is often distributed across multiple sources and identifying the correct set-of data-sources with relevant information for a knowledge request is a fundamental challenge. In this work, we define the novel task of routing an end-user query to the appropriate data-source, where the data-sources are databases. We synthesize datasets by extending existing datasets designed for NL-to-SQL semantic parsing. We create baselines on these datasets by using open-source LLMs, using both pre-trained and task specific embeddings fine-tuned using the training data. With these baselines we demonstrate that open-source LLMs perform better than embedding based approach, but suffer from token length limitations. Embedding based approaches benefit from task specific fine-tuning, more so when there is availability of data in terms of database specific questions for training. We further find that the task becomes more difficult (i) with an increase in the number of data-sources, (ii) having data-sources closer in terms of their domains,(iii) having databases without external domain knowledge required to interpret its entities and (iv) with ambiguous and complex queries requiring more fine-grained understanding of the data-sources or logical reasoning for routing to an appropriate source. This calls for the need for developing more sophisticated solutions to better address the task.
BudgetMLAgent: A Cost-Effective LLM Multi-Agent system for Automating Machine Learning Tasks
Nov 12, 2024

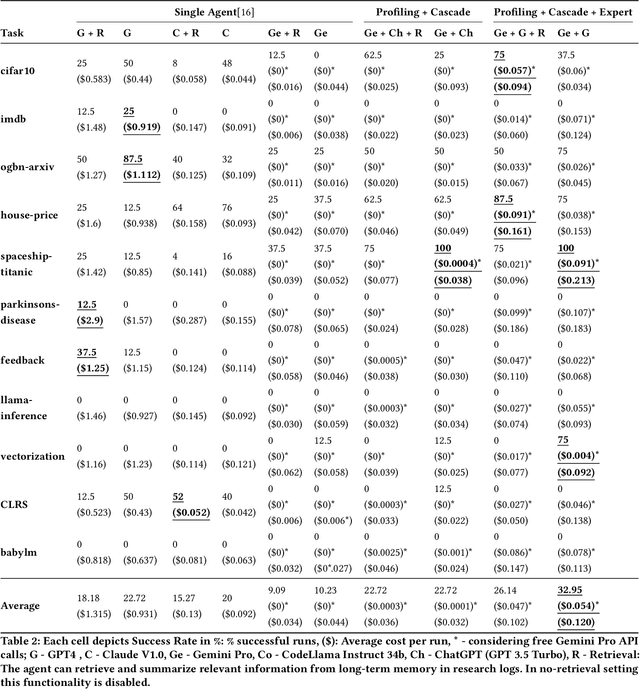
Large Language Models (LLMs) excel in diverse applications including generation of code snippets, but often struggle with generating code for complex Machine Learning (ML) tasks. Although existing LLM single-agent based systems give varying performance depending on the task complexity, they purely rely on larger and expensive models such as GPT-4. Our investigation reveals that no-cost and low-cost models such as Gemini-Pro, Mixtral and CodeLlama perform far worse than GPT-4 in a single-agent setting. With the motivation of developing a cost-efficient LLM based solution for solving ML tasks, we propose an LLM Multi-Agent based system which leverages combination of experts using profiling, efficient retrieval of past observations, LLM cascades, and ask-the-expert calls. Through empirical analysis on ML engineering tasks in the MLAgentBench benchmark, we demonstrate the effectiveness of our system, using no-cost models, namely Gemini as the base LLM, paired with GPT-4 in cascade and expert to serve occasional ask-the-expert calls for planning. With 94.2\% reduction in the cost (from \$0.931 per run cost averaged over all tasks for GPT-4 single agent system to \$0.054), our system is able to yield better average success rate of 32.95\% as compared to GPT-4 single-agent system yielding 22.72\% success rate averaged over all the tasks of MLAgentBench.