 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Identity Consistency and Prompt Diversity in Diffusion Models via Latent Concatenation and Masked Conditional Flow Matching
Nov 11, 2025
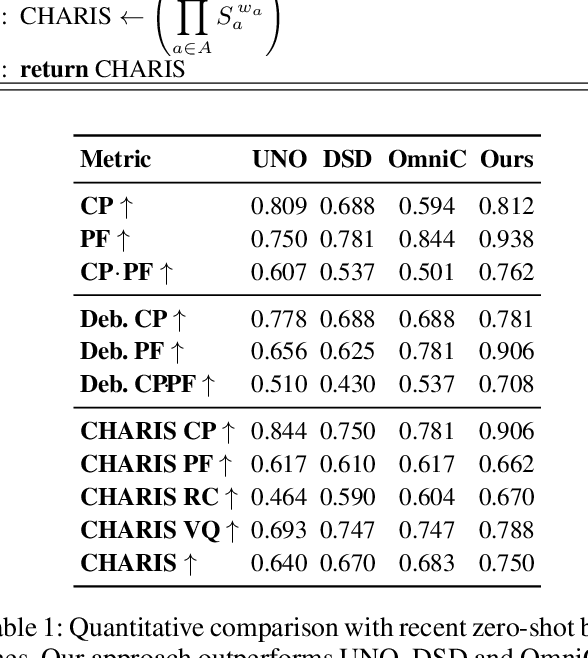


Subject-driven image generation aims to synthesize novel depictions of a specific subject across diverse contexts while preserving its core identity features. Achieving both strong identity consistency and high prompt diversity presents a fundamental trade-off. We propose a LoRA fine-tuned diffusion model employing a latent concatenation strategy, which jointly processes reference and target images, combined with a masked Conditional Flow Matching (CFM) objective. This approach enables robust identity preservation without architectural modifications. To facilitate large-scale training, we introduce a two-stage Distilled Data Curation Framework: the first stage leverages data restoration and VLM-based filtering to create a compact, high-quality seed dataset from diverse sources; the second stage utilizes these curated examples for parameter-efficient fine-tuning, thus scaling the generation capability across various subjects and contexts. Finally, for filtering and quality assessment, we present CHARIS, a fine-grained evaluation framework that performs attribute-level comparisons along five key axes: identity consistency, prompt adherence, region-wise color fidelity, visual quality, and transformation diversity.
Beyond the Pixels: VLM-based Evaluation of Identity Preservation in Reference-Guided Synthesis
Nov 11, 2025Evaluating identity preservation in generative models remains a critical yet unresolved challenge. Existing metrics rely on global embeddings or coarse VLM prompting, failing to capture fine-grained identity changes and providing limited diagnostic insight. We introduce Beyond the Pixels, a hierarchical evaluation framework that decomposes identity assessment into feature-level transformations. Our approach guides VLMs through structured reasoning by (1) hierarchically decomposing subjects into (type, style) -> attribute -> feature decision tree, and (2) prompting for concrete transformations rather than abstract similarity scores. This decomposition grounds VLM analysis in verifiable visual evidence, reducing hallucinations and improving consistency. We validate our framework across four state-of-the-art generative models, demonstrating strong alignment with human judgments in measuring identity consistency. Additionally, we introduce a new benchmark specifically designed to stress-test generative models. It comprises 1,078 image-prompt pairs spanning diverse subject types, including underrepresented categories such as anthropomorphic and animated characters, and captures an average of six to seven transformation axes per prompt.
OrienText: Surface Oriented Textual Image Generation
May 27, 2025Textual content in images is crucial in e-commerce sectors, particularly in marketing campaigns, product imaging, advertising, and the entertainment industry. Current text-to-image (T2I) generation diffusion models, though proficient at producing high-quality images, often struggle to incorporate text accurately onto complex surfaces with varied perspectives, such as angled views of architectural elements like buildings, banners, or walls. In this paper, we introduce the Surface Oriented Textual Image Generation (OrienText) method, which leverages region-specific surface normals as conditional input to T2I generation diffusion model. Our approach ensures accurate rendering and correct orientation of the text within the image context. We demonstrate the effectiveness of the OrienText method on a self-curated dataset of images and compare it against the existing textual image generation methods.
Multi-Subject Personalization
May 21, 2024Creative story illustration requires a consistent interplay of multiple characters or objects. However, conventional text-to-image models face significant challenges while producing images featuring multiple personalized subjects. For example, they distort the subject rendering, or the text descriptions fail to render coherent subject interactions. We present Multi-Subject Personalization (MSP) to alleviate some of these challenges. We implement MSP using Stable Diffusion and assess our approach against other text-to-image models, showcasing its consistent generation of good-quality images representing intended subjects and interactions.
SmartFlow: Robotic Process Automation using LLMs
May 21, 2024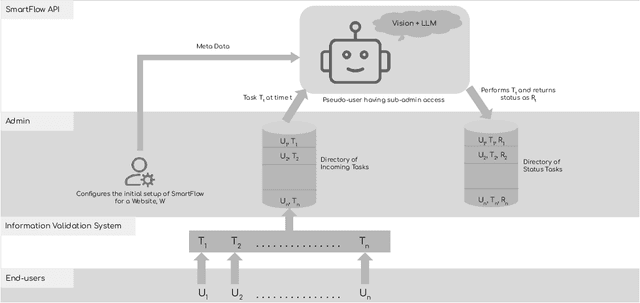
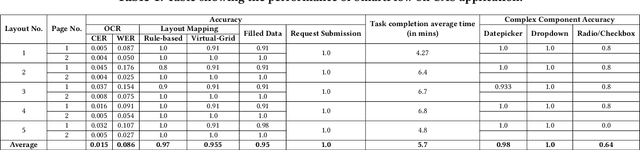
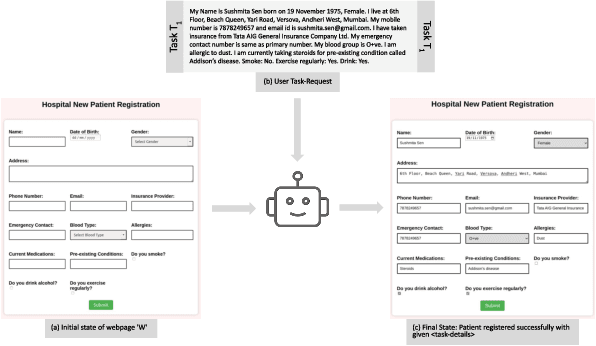

Robotic Process Automation (RPA) systems face challenges in handling complex processes and diverse screen layouts that require advanced human-like decision-making capabilities. These systems typically rely on pixel-level encoding through drag-and-drop or automation frameworks such as Selenium to create navigation workflows, rather than visual understanding of screen elements. In this context, we present SmartFlow, an AI-based RPA system that uses pre-trained large language models (LLMs) coupled with deep-learning based image understanding. Our system can adapt to new scenarios, including changes in the user interface and variations in input data, without the need for human intervention. SmartFlow uses computer vision and natural language processing to perceive visible elements on the graphical user interface (GUI) and convert them into a textual representation. This information is then utilized by LLMs to generate a sequence of actions that are executed by a scripting engine to complete an assigned task. To assess the effectiveness of SmartFlow, we have developed a dataset that includes a set of generic enterprise applications with diverse layouts, which we are releasing for research use. Our evaluations on this dataset demonstrate that SmartFlow exhibits robustness across different layouts and applications. SmartFlow can automate a wide range of business processes such as form filling, customer service, invoice processing, and back-office operations. SmartFlow can thus assist organizations in enhancing productivity by automating an even larger fraction of screen-based workflows. The demo-video and dataset are available at https://smartflow-4c5a0a.webflow.io/.
CustomText: Customized Textual Image Generation using Diffusion Models
May 21, 2024Textual image generation spans diverse fields like advertising, education, product packaging, social media, information visualization, and branding. Despite recent strides in language-guided image synthesis using diffusion models, current models excel in image generation but struggle with accurate text rendering and offer limited control over font attributes. In this paper, we aim to enhance the synthesis of high-quality images with precise text customization, thereby contributing to the advancement of image generation models. We call our proposed method CustomText. Our implementation leverages a pre-trained TextDiffuser model to enable control over font color, background, and types. Additionally, to address the challenge of accurately rendering small-sized fonts, we train the ControlNet model for a consistency decoder, significantly enhancing text-generation performance. We assess the performance of CustomText in comparison to previous methods of textual image generation on the publicly available CTW-1500 dataset and a self-curated dataset for small-text generation, showcasing superior results.
Adaptive Exploration for Data-Efficient General Value Function Evaluations
May 13, 2024General Value Functions (GVFs) (Sutton et al, 2011) are an established way to represent predictive knowledge in reinforcement learning. Each GVF computes the expected return for a given policy, based on a unique pseudo-reward. Multiple GVFs can be estimated in parallel using off-policy learning from a single stream of data, often sourced from a fixed behavior policy or pre-collected dataset. This leaves an open question: how can behavior policy be chosen for data-efficient GVF learning? To address this gap, we propose GVFExplorer, which aims at learning a behavior policy that efficiently gathers data for evaluating multiple GVFs in parallel. This behavior policy selects actions in proportion to the total variance in the return across all GVFs, reducing the number of environmental interactions. To enable accurate variance estimation, we use a recently proposed temporal-difference-style variance estimator. We prove that each behavior policy update reduces the mean squared error in the summed predictions over all GVFs. We empirically demonstrate our method's performance in both tabular representations and nonlinear function approximation.
Towards Painless Policy Optimization for Constrained MDPs
Apr 11, 2022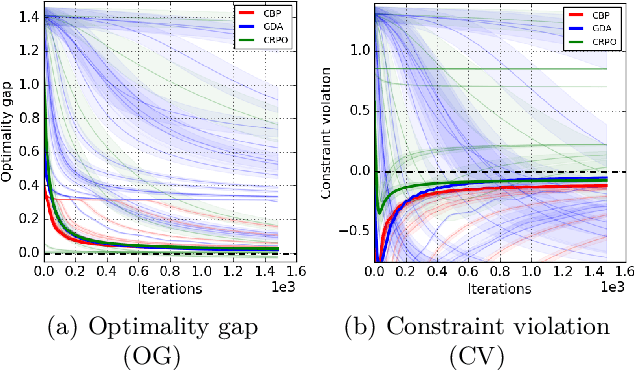

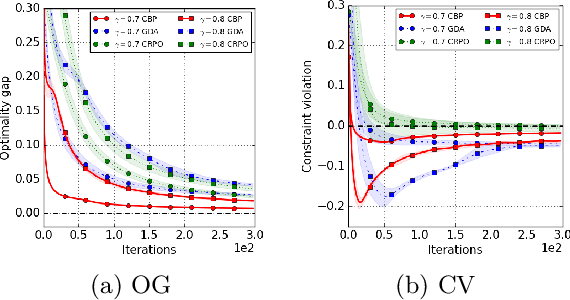
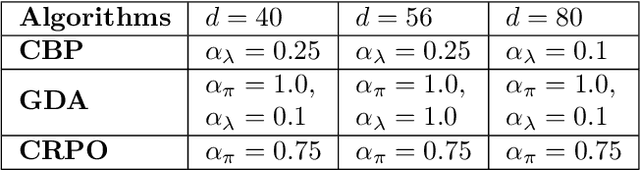
We study policy optimization in an infinite horizon, $\gamma$-discounted constrained Markov decision process (CMDP). Our objective is to return a policy that achieves large expected reward with a small constraint violation. We consider the online setting with linear function approximation and assume global access to the corresponding features. We propose a generic primal-dual framework that allows us to bound the reward sub-optimality and constraint violation for arbitrary algorithms in terms of their primal and dual regret on online linear optimization problems. We instantiate this framework to use coin-betting algorithms and propose the Coin Betting Politex (CBP) algorithm. Assuming that the action-value functions are $\varepsilon_b$-close to the span of the $d$-dimensional state-action features and no sampling errors, we prove that $T$ iterations of CBP result in an $O\left(\frac{1}{(1 - \gamma)^3 \sqrt{T}} + \frac{\varepsilon_b\sqrt{d}}{(1 - \gamma)^2} \right)$ reward sub-optimality and an $O\left(\frac{1}{(1 - \gamma)^2 \sqrt{T}} + \frac{\varepsilon_b \sqrt{d}}{1 - \gamma} \right)$ constraint violation. Importantly, unlike gradient descent-ascent and other recent methods, CBP does not require extensive hyperparameter tuning. Via experiments on synthetic and Cartpole environments, we demonstrate the effectiveness and robustness of CBP.
TSR-DSAW: Table Structure Recognition via Deep Spatial Association of Words
Mar 14, 2022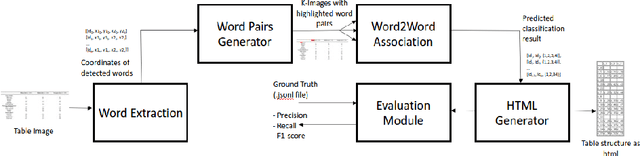

Existing methods for Table Structure Recognition (TSR) from camera-captured or scanned documents perform poorly on complex tables consisting of nested rows / columns, multi-line texts and missing cell data. This is because current data-driven methods work by simply training deep models on large volumes of data and fail to generalize when an unseen table structure is encountered. In this paper, we propose to train a deep network to capture the spatial associations between different word pairs present in the table image for unravelling the table structure. We present an end-to-end pipeline, named TSR-DSAW: TSR via Deep Spatial Association of Words, which outputs a digital representation of a table image in a structured format such as HTML. Given a table image as input, the proposed method begins with the detection of all the words present in the image using a text-detection network like CRAFT which is followed by the generation of word-pairs using dynamic programming. These word-pairs are highlighted in individual images and subsequently, fed into a DenseNet-121 classifier trained to capture spatial associations such as same-row, same-column, same-cell or none. Finally, we perform post-processing on the classifier output to generate the table structure in HTML format. We evaluate our TSR-DSAW pipeline on two public table-image datasets -- PubTabNet and ICDAR 2013, and demonstrate improvement over previous methods such as TableNet and DeepDeSRT.
* 6 pages, 1 figure, 1 table, ESANN 2021 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Online event, 6-8 October 2021, i6doc.com publ., ISBN 978287587082-7
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021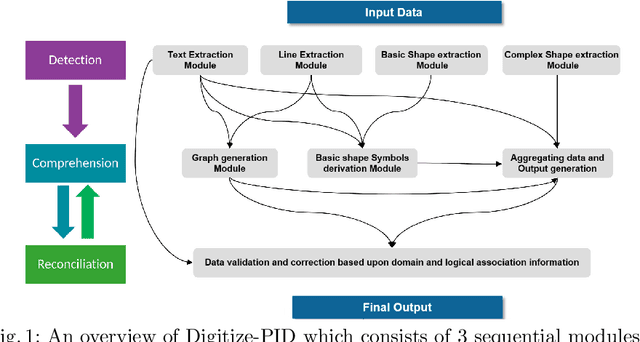
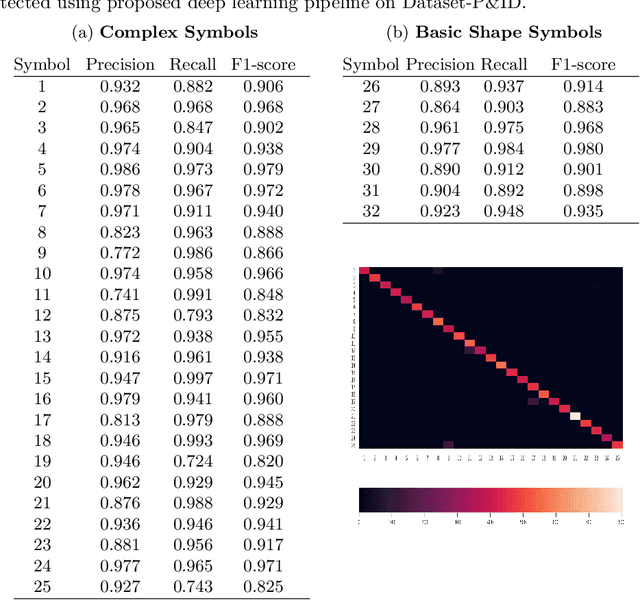
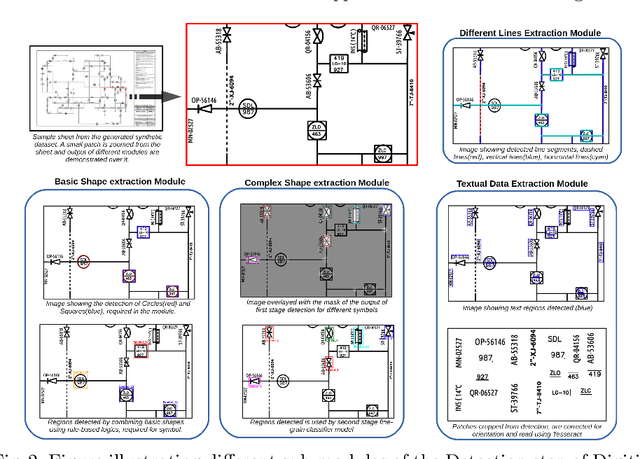
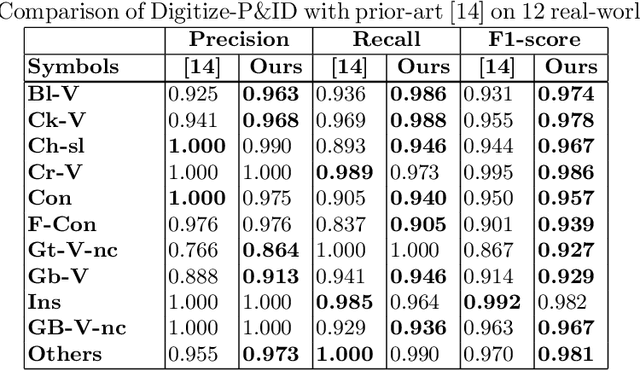
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages