 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Subject Personalization
May 21, 2024Creative story illustration requires a consistent interplay of multiple characters or objects. However, conventional text-to-image models face significant challenges while producing images featuring multiple personalized subjects. For example, they distort the subject rendering, or the text descriptions fail to render coherent subject interactions. We present Multi-Subject Personalization (MSP) to alleviate some of these challenges. We implement MSP using Stable Diffusion and assess our approach against other text-to-image models, showcasing its consistent generation of good-quality images representing intended subjects and interactions.
SmartFlow: Robotic Process Automation using LLMs
May 21, 2024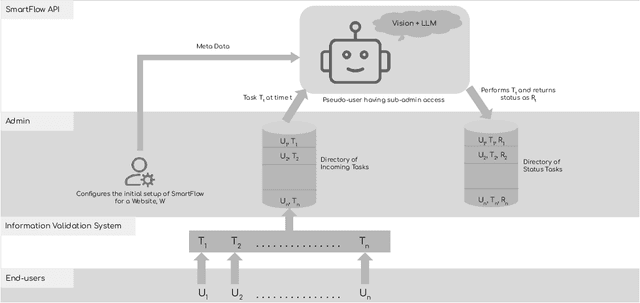
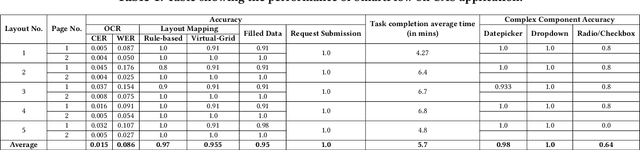
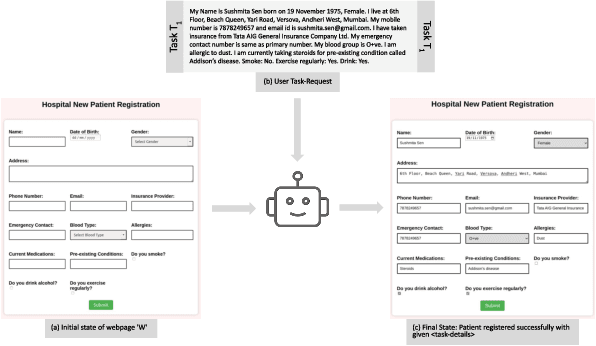

Robotic Process Automation (RPA) systems face challenges in handling complex processes and diverse screen layouts that require advanced human-like decision-making capabilities. These systems typically rely on pixel-level encoding through drag-and-drop or automation frameworks such as Selenium to create navigation workflows, rather than visual understanding of screen elements. In this context, we present SmartFlow, an AI-based RPA system that uses pre-trained large language models (LLMs) coupled with deep-learning based image understanding. Our system can adapt to new scenarios, including changes in the user interface and variations in input data, without the need for human intervention. SmartFlow uses computer vision and natural language processing to perceive visible elements on the graphical user interface (GUI) and convert them into a textual representation. This information is then utilized by LLMs to generate a sequence of actions that are executed by a scripting engine to complete an assigned task. To assess the effectiveness of SmartFlow, we have developed a dataset that includes a set of generic enterprise applications with diverse layouts, which we are releasing for research use. Our evaluations on this dataset demonstrate that SmartFlow exhibits robustness across different layouts and applications. SmartFlow can automate a wide range of business processes such as form filling, customer service, invoice processing, and back-office operations. SmartFlow can thus assist organizations in enhancing productivity by automating an even larger fraction of screen-based workflows. The demo-video and dataset are available at https://smartflow-4c5a0a.webflow.io/.
CustomText: Customized Textual Image Generation using Diffusion Models
May 21, 2024Textual image generation spans diverse fields like advertising, education, product packaging, social media, information visualization, and branding. Despite recent strides in language-guided image synthesis using diffusion models, current models excel in image generation but struggle with accurate text rendering and offer limited control over font attributes. In this paper, we aim to enhance the synthesis of high-quality images with precise text customization, thereby contributing to the advancement of image generation models. We call our proposed method CustomText. Our implementation leverages a pre-trained TextDiffuser model to enable control over font color, background, and types. Additionally, to address the challenge of accurately rendering small-sized fonts, we train the ControlNet model for a consistency decoder, significantly enhancing text-generation performance. We assess the performance of CustomText in comparison to previous methods of textual image generation on the publicly available CTW-1500 dataset and a self-curated dataset for small-text generation, showcasing superior results.
TSR-DSAW: Table Structure Recognition via Deep Spatial Association of Words
Mar 14, 2022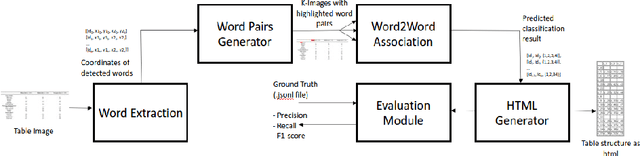

Existing methods for Table Structure Recognition (TSR) from camera-captured or scanned documents perform poorly on complex tables consisting of nested rows / columns, multi-line texts and missing cell data. This is because current data-driven methods work by simply training deep models on large volumes of data and fail to generalize when an unseen table structure is encountered. In this paper, we propose to train a deep network to capture the spatial associations between different word pairs present in the table image for unravelling the table structure. We present an end-to-end pipeline, named TSR-DSAW: TSR via Deep Spatial Association of Words, which outputs a digital representation of a table image in a structured format such as HTML. Given a table image as input, the proposed method begins with the detection of all the words present in the image using a text-detection network like CRAFT which is followed by the generation of word-pairs using dynamic programming. These word-pairs are highlighted in individual images and subsequently, fed into a DenseNet-121 classifier trained to capture spatial associations such as same-row, same-column, same-cell or none. Finally, we perform post-processing on the classifier output to generate the table structure in HTML format. We evaluate our TSR-DSAW pipeline on two public table-image datasets -- PubTabNet and ICDAR 2013, and demonstrate improvement over previous methods such as TableNet and DeepDeSRT.
* 6 pages, 1 figure, 1 table, ESANN 2021 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Online event, 6-8 October 2021, i6doc.com publ., ISBN 978287587082-7
OSSR-PID: One-Shot Symbol Recognition in P&ID Sheets using Path Sampling and GCN
Sep 08, 2021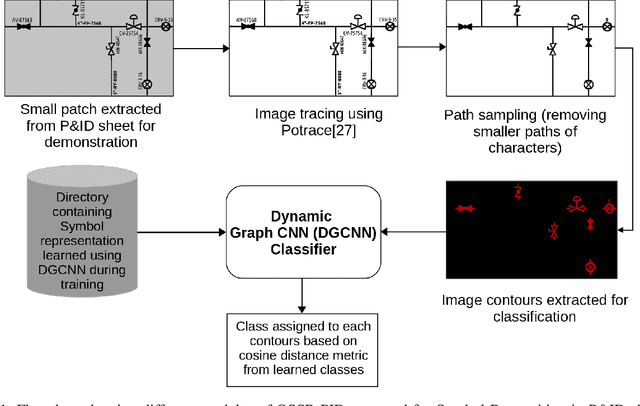



Piping and Instrumentation Diagrams (P&ID) are ubiquitous in several manufacturing, oil and gas enterprises for representing engineering schematics and equipment layout. There is an urgent need to extract and digitize information from P&IDs without the cost of annotating a varying set of symbols for each new use case. A robust one-shot learning approach for symbol recognition i.e., localization followed by classification, would therefore go a long way towards this goal. Our method works by sampling pixels sequentially along the different contour boundaries in the image. These sampled points form paths which are used in the prototypical line diagram to construct a graph that captures the structure of the contours. Subsequently, the prototypical graphs are fed into a Dynamic Graph Convolutional Neural Network (DGCNN) which is trained to classify graphs into one of the given symbol classes. Further, we append embeddings from a Resnet-34 network which is trained on symbol images containing sampled points to make the classification network more robust. Since, many symbols in P&ID are structurally very similar to each other, we utilize Arcface loss during DGCNN training which helps in maximizing symbol class separability by producing highly discriminative embeddings. The images consist of components attached on the pipeline (straight line). The sampled points segregated around the symbol regions are used for the classification task. The proposed pipeline, named OSSR-PID, is fast and gives outstanding performance for recognition of symbols on a synthetic dataset of 100 P&ID diagrams. We also compare our method against prior-work on a real-world private dataset of 12 P&ID sheets and obtain comparable/superior results. Remarkably, it is able to achieve such excellent performance using only one prototypical example per symbol.
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021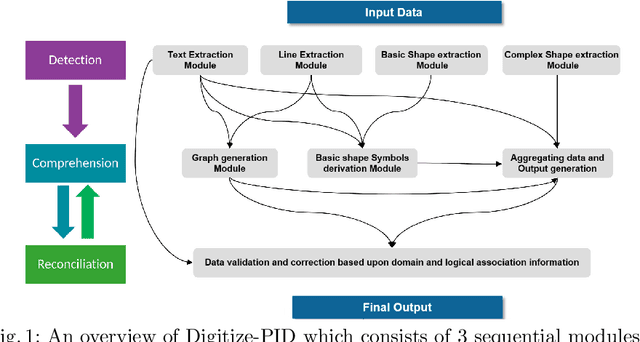
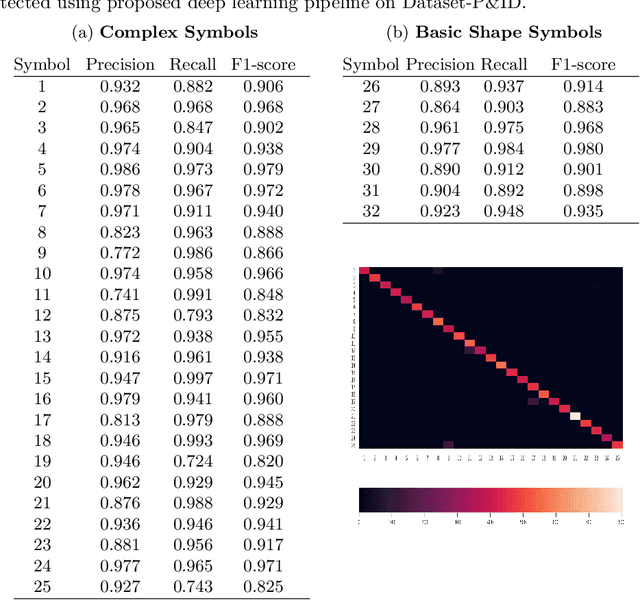
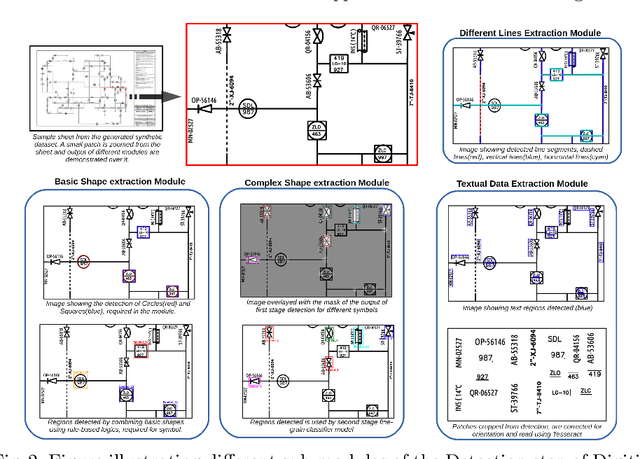
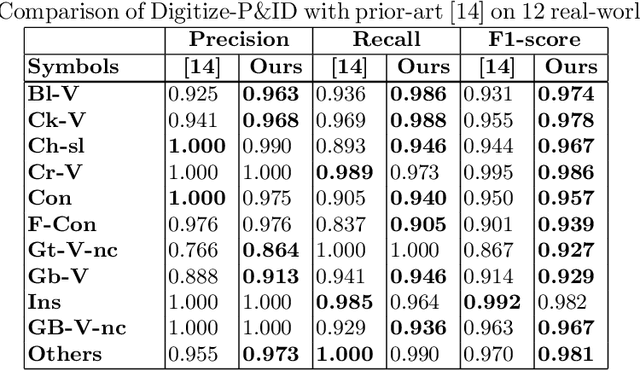
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages
TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Jan 06, 2020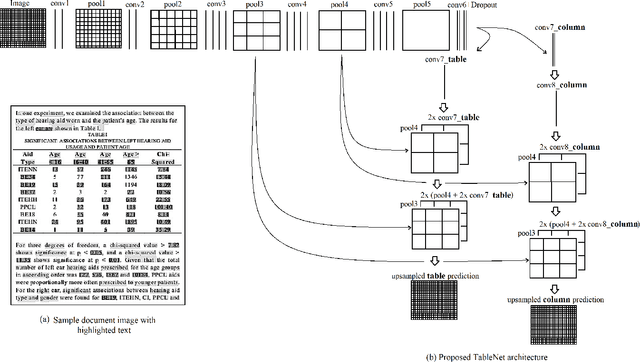

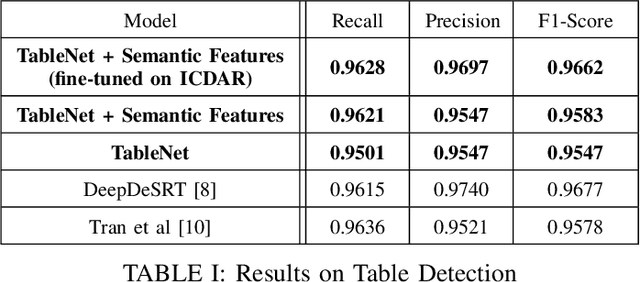
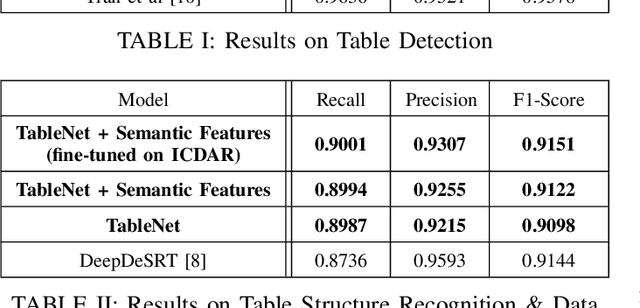
With the widespread use of mobile phones and scanners to photograph and upload documents, the need for extracting the information trapped in unstructured document images such as retail receipts, insurance claim forms and financial invoices is becoming more acute. A major hurdle to this objective is that these images often contain information in the form of tables and extracting data from tabular sub-images presents a unique set of challenges. This includes accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table. While some progress has been made in table detection, extracting the table contents is still a challenge since this involves more fine grained table structure(rows & columns) recognition. Prior approaches have attempted to solve the table detection and structure recognition problems independently using two separate models. In this paper, we propose TableNet: a novel end-to-end deep learning model for both table detection and structure recognition. The model exploits the interdependence between the twin tasks of table detection and table structure recognition to segment out the table and column regions. This is followed by semantic rule-based row extraction from the identified tabular sub-regions. The proposed model and extraction approach was evaluated on the publicly available ICDAR 2013 and Marmot Table datasets obtaining state of the art results. Additionally, we demonstrate that feeding additional semantic features further improves model performance and that the model exhibits transfer learning across datasets. Another contribution of this paper is to provide additional table structure annotations for the Marmot data, which currently only has annotations for table detection.
Automatic Information Extraction from Piping and Instrumentation Diagrams
Jan 28, 2019

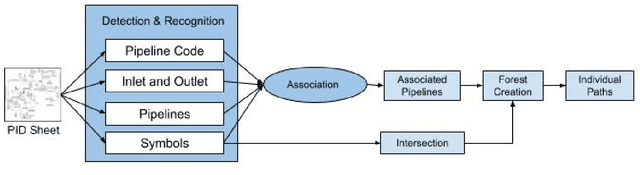
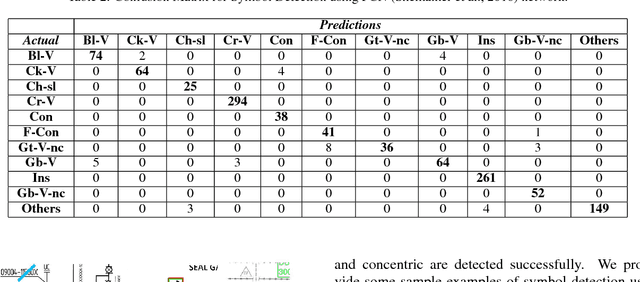
One of the most common modes of representing engineering schematics are Piping and Instrumentation diagrams (P&IDs) that describe the layout of an engineering process flow along with the interconnected process equipment. Over the years, P&ID diagrams have been manually generated, scanned and stored as image files. These files need to be digitized for purposes of inventory management and updation, and easy reference to different components of the schematics. There are several challenging vision problems associated with digitizing real world P&ID diagrams. Real world P&IDs come in several different resolutions, and often contain noisy textual information. Extraction of instrumentation information from these diagrams involves accurate detection of symbols that frequently have minute visual differences between them. Identification of pipelines that may converge and diverge at different points in the image is a further cause for concern. Due to these reasons, to the best of our knowledge, no system has been proposed for end-to-end data extraction from P&ID diagrams. However, with the advent of deep learning and the spectacular successes it has achieved in vision, we hypothesized that it is now possible to re-examine this problem armed with the latest deep learning models. To that end, we present a novel pipeline for information extraction from P&ID sheets via a combination of traditional vision techniques and state-of-the-art deep learning models to identify and isolate pipeline codes, pipelines, inlets and outlets, and for detecting symbols. This is followed by association of the detected components with the appropriate pipeline. The extracted pipeline information is used to populate a tree-like data-structure for capturing the structure of the piping schematics. We evaluated proposed method on a real world dataset of P&ID sheets obtained from an oil firm and have obtained promising results.