 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearchCodeAgent: An LLM Multi-Agent System for Automated Codification of Research Methodologies
Apr 28, 2025
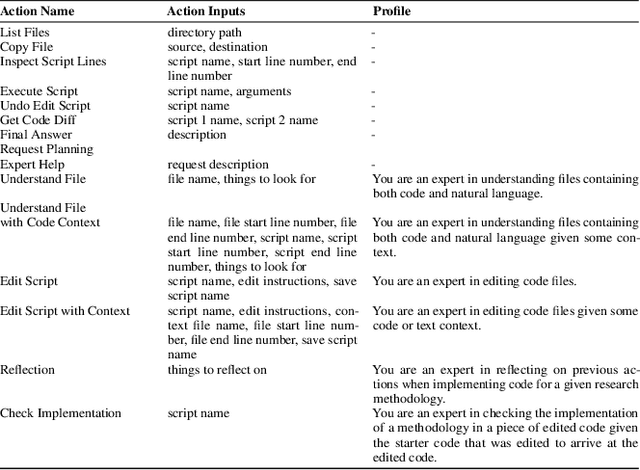
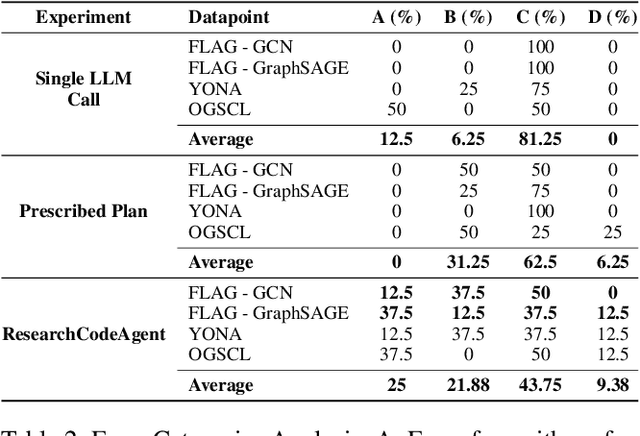
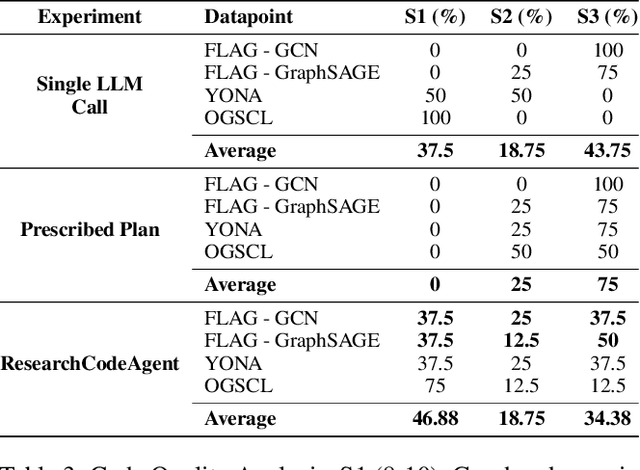
In this paper we introduce ResearchCodeAgent, a novel multi-agent system leveraging large language models (LLMs) agents to automate the codification of research methodologies described in machine learning literature. The system bridges the gap between high-level research concepts and their practical implementation, allowing researchers auto-generating code of existing research papers for benchmarking or building on top-of existing methods specified in the literature with availability of partial or complete starter code. ResearchCodeAgent employs a flexible agent architecture with a comprehensive action suite, enabling context-aware interactions with the research environment. The system incorporates a dynamic planning mechanism, utilizing both short and long-term memory to adapt its approach iteratively. We evaluate ResearchCodeAgent on three distinct machine learning tasks with distinct task complexity and representing different parts of the ML pipeline: data augmentation, optimization, and data batching. Our results demonstrate the system's effectiveness and generalizability, with 46.9% of generated code being high-quality and error-free, and 25% showing performance improvements over baseline implementations. Empirical analysis shows an average reduction of 57.9% in coding time compared to manual implementation. We observe higher gains for more complex tasks. ResearchCodeAgent represents a significant step towards automating the research implementation process, potentially accelerating the pace of machine learning research.
ConceptSearch: Towards Efficient Program Search Using LLMs for Abstraction and Reasoning Corpus (ARC)
Dec 10, 2024



The Abstraction and Reasoning Corpus (ARC) poses a significant challenge to artificial intelligence, demanding broad generalization and few-shot learning capabilities that remain elusive for current deep learning methods, including large language models (LLMs). While LLMs excel in program synthesis, their direct application to ARC yields limited success. To address this, we introduce ConceptSearch, a novel function-search algorithm that leverages LLMs for program generation and employs a concept-based scoring method to guide the search efficiently. Unlike simplistic pixel-based metrics like Hamming distance, ConceptSearch evaluates programs on their ability to capture the underlying transformation concept reflected in the input-output examples. We explore three scoring functions: Hamming distance, a CNN-based scoring function, and an LLM-based natural language scoring function. Experimental results demonstrate the effectiveness of ConceptSearch, achieving a significant performance improvement over direct prompting with GPT-4. Moreover, our novel concept-based scoring exhibits up to 30% greater efficiency compared to Hamming distance, measured in terms of the number of iterations required to reach the correct solution. These findings highlight the potential of LLM-driven program search when integrated with concept-based guidance for tackling challenging generalization problems like ARC. Code: https://github.com/kksinghal/concept-search
BudgetMLAgent: A Cost-Effective LLM Multi-Agent system for Automating Machine Learning Tasks
Nov 12, 2024

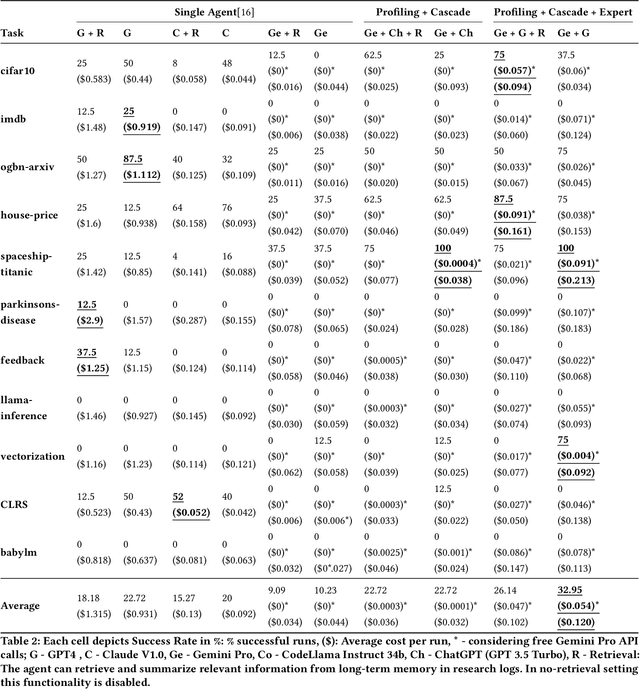
Large Language Models (LLMs) excel in diverse applications including generation of code snippets, but often struggle with generating code for complex Machine Learning (ML) tasks. Although existing LLM single-agent based systems give varying performance depending on the task complexity, they purely rely on larger and expensive models such as GPT-4. Our investigation reveals that no-cost and low-cost models such as Gemini-Pro, Mixtral and CodeLlama perform far worse than GPT-4 in a single-agent setting. With the motivation of developing a cost-efficient LLM based solution for solving ML tasks, we propose an LLM Multi-Agent based system which leverages combination of experts using profiling, efficient retrieval of past observations, LLM cascades, and ask-the-expert calls. Through empirical analysis on ML engineering tasks in the MLAgentBench benchmark, we demonstrate the effectiveness of our system, using no-cost models, namely Gemini as the base LLM, paired with GPT-4 in cascade and expert to serve occasional ask-the-expert calls for planning. With 94.2\% reduction in the cost (from \$0.931 per run cost averaged over all tasks for GPT-4 single agent system to \$0.054), our system is able to yield better average success rate of 32.95\% as compared to GPT-4 single-agent system yielding 22.72\% success rate averaged over all the tasks of MLAgentBench.
SmartFlow: Robotic Process Automation using LLMs
May 21, 2024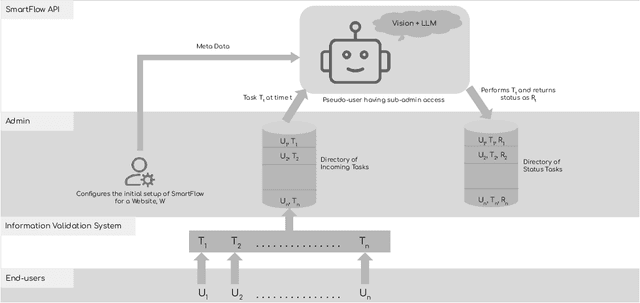
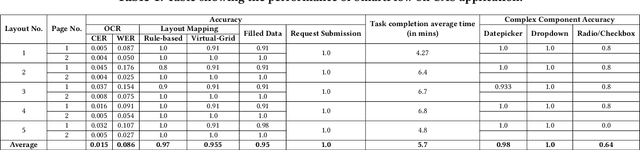
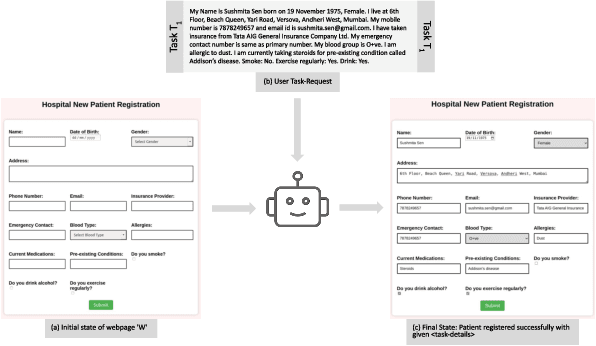

Robotic Process Automation (RPA) systems face challenges in handling complex processes and diverse screen layouts that require advanced human-like decision-making capabilities. These systems typically rely on pixel-level encoding through drag-and-drop or automation frameworks such as Selenium to create navigation workflows, rather than visual understanding of screen elements. In this context, we present SmartFlow, an AI-based RPA system that uses pre-trained large language models (LLMs) coupled with deep-learning based image understanding. Our system can adapt to new scenarios, including changes in the user interface and variations in input data, without the need for human intervention. SmartFlow uses computer vision and natural language processing to perceive visible elements on the graphical user interface (GUI) and convert them into a textual representation. This information is then utilized by LLMs to generate a sequence of actions that are executed by a scripting engine to complete an assigned task. To assess the effectiveness of SmartFlow, we have developed a dataset that includes a set of generic enterprise applications with diverse layouts, which we are releasing for research use. Our evaluations on this dataset demonstrate that SmartFlow exhibits robustness across different layouts and applications. SmartFlow can automate a wide range of business processes such as form filling, customer service, invoice processing, and back-office operations. SmartFlow can thus assist organizations in enhancing productivity by automating an even larger fraction of screen-based workflows. The demo-video and dataset are available at https://smartflow-4c5a0a.webflow.io/.
Acceleron: A Tool to Accelerate Research Ideation
Mar 07, 2024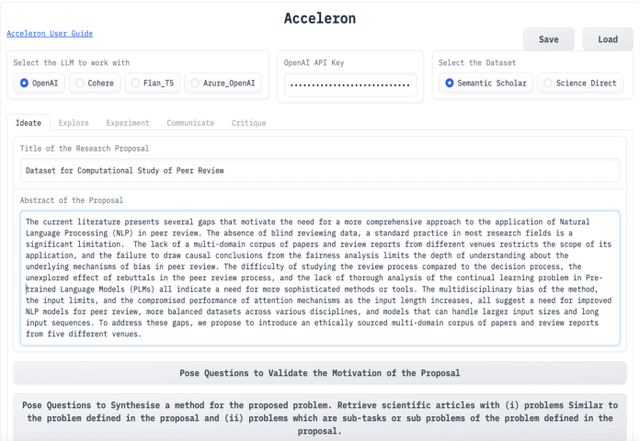
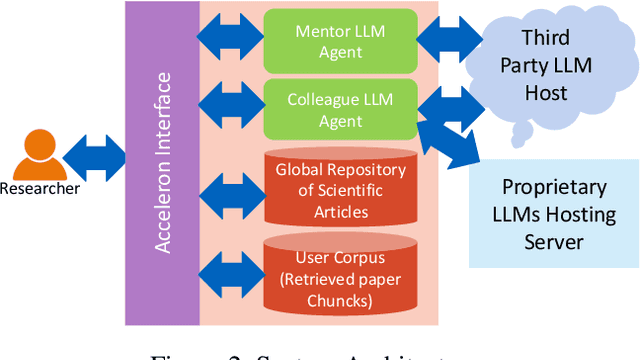
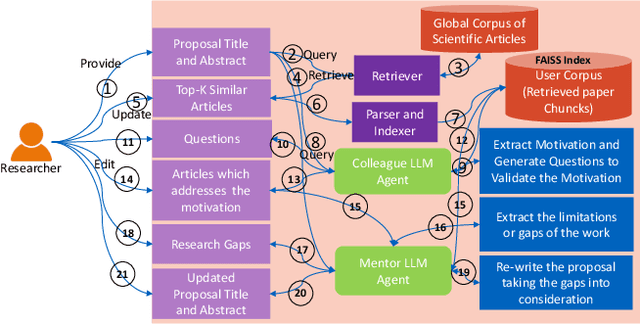
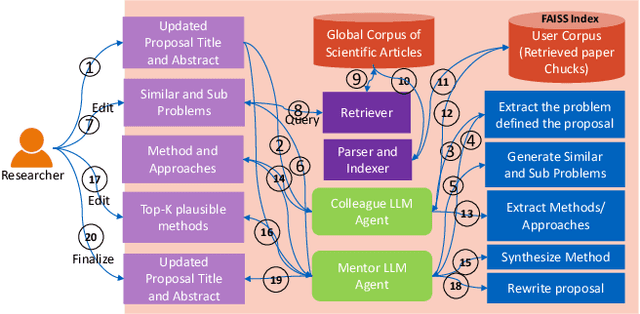
Several tools have recently been proposed for assisting researchers during various stages of the research life-cycle. However, these primarily concentrate on tasks such as retrieving and recommending relevant literature, reviewing and critiquing the draft, and writing of research manuscripts. Our investigation reveals a significant gap in availability of tools specifically designed to assist researchers during the challenging ideation phase of the research life-cycle. To aid with research ideation, we propose `Acceleron', a research accelerator for different phases of the research life cycle, and which is specially designed to aid the ideation process. Acceleron guides researchers through the formulation of a comprehensive research proposal, encompassing a novel research problem. The proposals motivation is validated for novelty by identifying gaps in the existing literature and suggesting a plausible list of techniques to solve the proposed problem. We leverage the reasoning and domain-specific skills of Large Language Models (LLMs) to create an agent-based architecture incorporating colleague and mentor personas for LLMs. The LLM agents emulate the ideation process undertaken by researchers, engaging researchers in an interactive fashion to aid in the development of the research proposal. Notably, our tool addresses challenges inherent in LLMs, such as hallucinations, implements a two-stage aspect-based retrieval to manage precision-recall trade-offs, and tackles issues of unanswerability. As evaluation, we illustrate the execution of our motivation validation and method synthesis workflows on proposals from the ML and NLP domain, given by 3 distinct researchers. Our observations and evaluations provided by the researchers illustrate the efficacy of the tool in terms of assisting researchers with appropriate inputs at distinct stages and thus leading to improved time efficiency.
Conservative Predictions on Noisy Financial Data
Oct 18, 2023



Price movements in financial markets are well known to be very noisy. As a result, even if there are, on occasion, exploitable patterns that could be picked up by machine-learning algorithms, these are obscured by feature and label noise rendering the predictions less useful, and risky in practice. Traditional rule-learning techniques developed for noisy data, such as CN2, would seek only high precision rules and refrain from making predictions where their antecedents did not apply. We apply a similar approach, where a model abstains from making a prediction on data points that it is uncertain on. During training, a cascade of such models are learned in sequence, similar to rule lists, with each model being trained only on data on which the previous model(s) were uncertain. Similar pruning of data takes place at test-time, with (higher accuracy) predictions being made albeit only on a fraction (support) of test-time data. In a financial prediction setting, such an approach allows decisions to be taken only when the ensemble model is confident, thereby reducing risk. We present results using traditional MLPs as well as differentiable decision trees, on synthetic data as well as real financial market data, to predict fixed-term returns using commonly used features. We submit that our approach is likely to result in better overall returns at a lower level of risk. In this context we introduce an utility metric to measure the average gain per trade, as well as the return adjusted for downside risk, both of which are improved significantly by our approach.
Adapt and Decompose: Efficient Generalization of Text-to-SQL via Domain Adapted Least-To-Most Prompting
Aug 09, 2023



Cross-domain and cross-compositional generalization of Text-to-SQL semantic parsing is a challenging task. Existing Large Language Model (LLM) based solutions rely on inference-time retrieval of few-shot exemplars from the training set to synthesize a run-time prompt for each Natural Language (NL) test query. In contrast, we devise an algorithm which performs offline sampling of a minimal set-of few-shots from the training data, with complete coverage of SQL clauses, operators and functions, and maximal domain coverage within the allowed token length. This allows for synthesis of a fixed Generic Prompt (GP), with a diverse set-of exemplars common across NL test queries, avoiding expensive test time exemplar retrieval. We further auto-adapt the GP to the target database domain (DA-GP), to better handle cross-domain generalization; followed by a decomposed Least-To-Most-Prompting (LTMP-DA-GP) to handle cross-compositional generalization. The synthesis of LTMP-DA-GP is an offline task, to be performed one-time per new database with minimal human intervention. Our approach demonstrates superior performance on the KaggleDBQA dataset, designed to evaluate generalizability for the Text-to-SQL task. We further showcase consistent performance improvement of LTMP-DA-GP over GP, across LLMs and databases of KaggleDBQA, highlighting the efficacy and model agnostic benefits of our prompt based adapt and decompose approach.
Calibrating Deep Neural Networks using Explicit Regularisation and Dynamic Data Pruning
Dec 20, 2022



Deep neural networks (DNN) are prone to miscalibrated predictions, often exhibiting a mismatch between the predicted output and the associated confidence scores. Contemporary model calibration techniques mitigate the problem of overconfident predictions by pushing down the confidence of the winning class while increasing the confidence of the remaining classes across all test samples. However, from a deployment perspective, an ideal model is desired to (i) generate well-calibrated predictions for high-confidence samples with predicted probability say >0.95, and (ii) generate a higher proportion of legitimate high-confidence samples. To this end, we propose a novel regularization technique that can be used with classification losses, leading to state-of-the-art calibrated predictions at test time; From a deployment standpoint in safety-critical applications, only high-confidence samples from a well-calibrated model are of interest, as the remaining samples have to undergo manual inspection. Predictive confidence reduction of these potentially ``high-confidence samples'' is a downside of existing calibration approaches. We mitigate this by proposing a dynamic train-time data pruning strategy that prunes low-confidence samples every few epochs, providing an increase in "confident yet calibrated samples". We demonstrate state-of-the-art calibration performance across image classification benchmarks, reducing training time without much compromise in accuracy. We provide insights into why our dynamic pruning strategy that prunes low-confidence training samples leads to an increase in high-confidence samples at test time.
Neural Feature-Adaptation for Symbolic Predictions Using Pre-Training and Semantic Loss
Nov 29, 2022



We are interested in neurosymbolic systems consisting of a high-level symbolic layer for explainable prediction in terms of human-intelligible concepts; and a low-level neural layer for extracting symbols required to generate the symbolic explanation. Real data is often imperfect meaning that even if the symbolic theory remains unchanged, we may still need to address the problem of mapping raw data to high-level symbols, each time there is a change in the data acquisition environment or equipment. Manual (re-)annotation of the raw data each time this happens is laborious and expensive; and automated labelling methods are often imperfect, especially for complex problems. NEUROLOG proposed the use of a semantic loss function that allows an existing feature-based symbolic model to guide the extraction of feature-values from raw data, using `abduction'. However, the experiments demonstrating the use of semantic loss through abduction appear to rely heavily on a domain-specific pre-processing step that enables a prior delineation of feature locations in the raw data. We examine the use of semantic loss in domains where such pre-processing is not possible, or is not obvious. We show that without any prior information about the features, the NEUROLOG approach can continue to predict accurately even with substantially incorrect feature predictions. We show also that prior information about the features in the form of even imperfect pre-training can help correct this situation. These findings are replicated on the original problem considered by NEUROLOG, without the use of feature-delineation. This suggests that symbolic explanations constructed for data in a domain could be re-used in a related domain, by `feature-adaptation' of pre-trained neural extractors using the semantic loss function constrained by abductive feedback.
Knowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Sep 19, 2022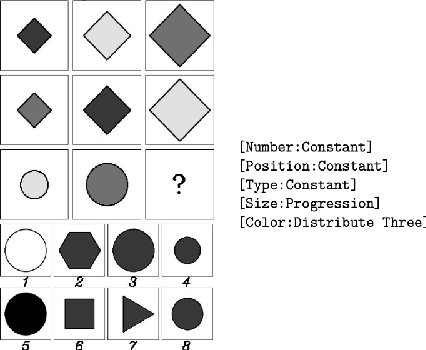
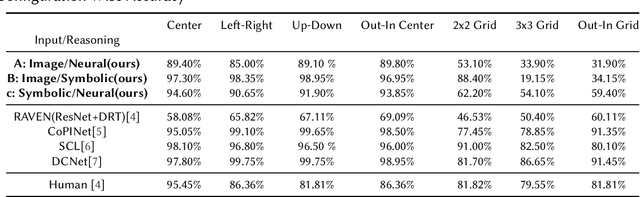
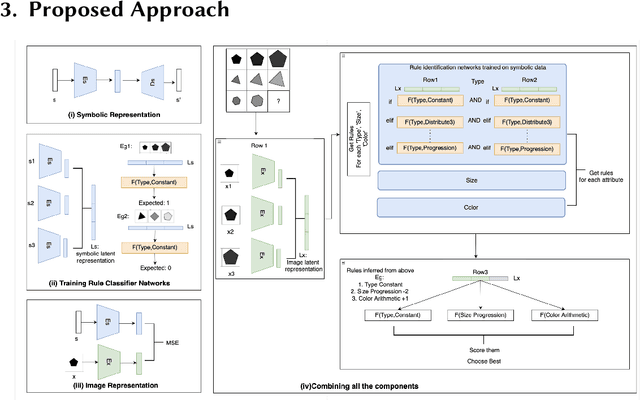
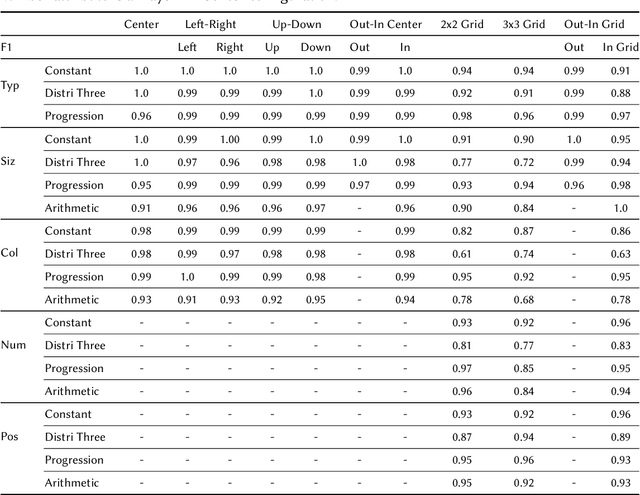
Analogical Reasoning problems challenge both connectionist and symbolic AI systems as these entail a combination of background knowledge, reasoning and pattern recognition. While symbolic systems ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to preset symbolic features. Connectionist systems on the other hand can directly ingest rich input spaces such as images, text or speech and recognize pattern even with noisy inputs. However, connectionist models struggle to include explicit domain knowledge for deductive reasoning. In this paper, we propose a framework that combines the pattern recognition abilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and use problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test this on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale yield SOTA, our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where domain knowledge is available.