 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Robustness in Large Language Models under Tabular Distortions
Jan 08, 2026We investigate how large language models (LLMs) fail when tabular data in an otherwise canonical representation is subjected to semantic and structural distortions. Our findings reveal that LLMs lack an inherent ability to detect and correct subtle distortions in table representations. Only when provided with an explicit prior, via a system prompt, do models partially adjust their reasoning strategies and correct some distortions, though not consistently or completely. To study this phenomenon, we introduce a small, expert-curated dataset that explicitly evaluates LLMs on table question answering (TQA) tasks requiring an additional error-correction step prior to analysis. Our results reveal systematic differences in how LLMs ingest and interpret tabular information under distortion, with even SoTA models such as GPT-5.2 model exhibiting a drop of minimum 22% accuracy under distortion. These findings raise important questions for future research, particularly regarding when and how models should autonomously decide to realign tabular inputs, analogous to human behavior, without relying on explicit prompts or tabular data pre-processing.
Acceleron: A Tool to Accelerate Research Ideation
Mar 07, 2024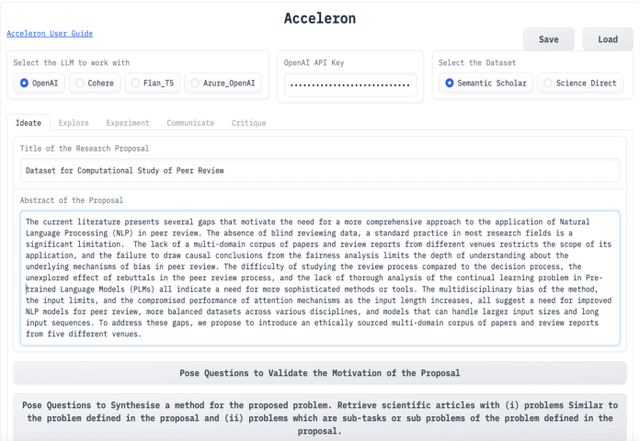
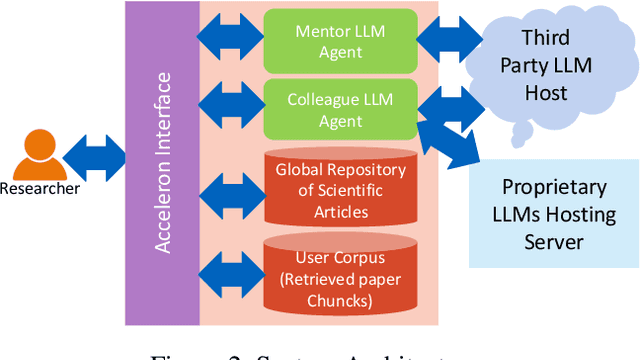
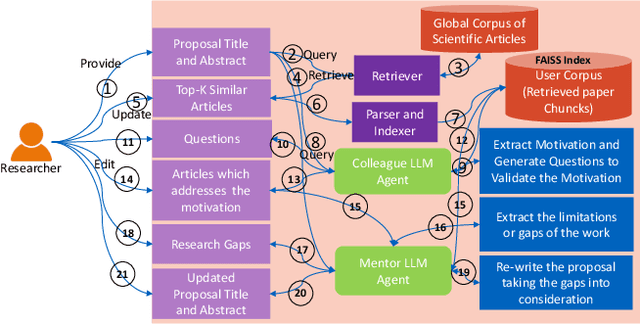
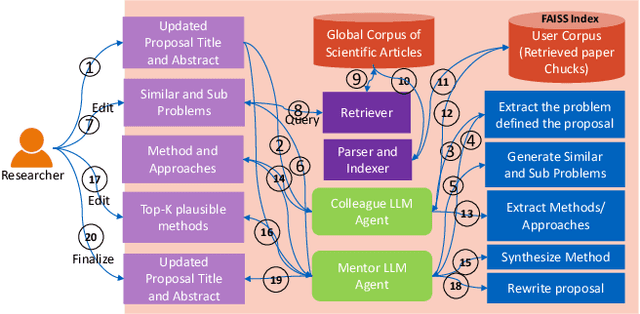
Several tools have recently been proposed for assisting researchers during various stages of the research life-cycle. However, these primarily concentrate on tasks such as retrieving and recommending relevant literature, reviewing and critiquing the draft, and writing of research manuscripts. Our investigation reveals a significant gap in availability of tools specifically designed to assist researchers during the challenging ideation phase of the research life-cycle. To aid with research ideation, we propose `Acceleron', a research accelerator for different phases of the research life cycle, and which is specially designed to aid the ideation process. Acceleron guides researchers through the formulation of a comprehensive research proposal, encompassing a novel research problem. The proposals motivation is validated for novelty by identifying gaps in the existing literature and suggesting a plausible list of techniques to solve the proposed problem. We leverage the reasoning and domain-specific skills of Large Language Models (LLMs) to create an agent-based architecture incorporating colleague and mentor personas for LLMs. The LLM agents emulate the ideation process undertaken by researchers, engaging researchers in an interactive fashion to aid in the development of the research proposal. Notably, our tool addresses challenges inherent in LLMs, such as hallucinations, implements a two-stage aspect-based retrieval to manage precision-recall trade-offs, and tackles issues of unanswerability. As evaluation, we illustrate the execution of our motivation validation and method synthesis workflows on proposals from the ML and NLP domain, given by 3 distinct researchers. Our observations and evaluations provided by the researchers illustrate the efficacy of the tool in terms of assisting researchers with appropriate inputs at distinct stages and thus leading to improved time efficiency.
Adapt and Decompose: Efficient Generalization of Text-to-SQL via Domain Adapted Least-To-Most Prompting
Aug 09, 2023



Cross-domain and cross-compositional generalization of Text-to-SQL semantic parsing is a challenging task. Existing Large Language Model (LLM) based solutions rely on inference-time retrieval of few-shot exemplars from the training set to synthesize a run-time prompt for each Natural Language (NL) test query. In contrast, we devise an algorithm which performs offline sampling of a minimal set-of few-shots from the training data, with complete coverage of SQL clauses, operators and functions, and maximal domain coverage within the allowed token length. This allows for synthesis of a fixed Generic Prompt (GP), with a diverse set-of exemplars common across NL test queries, avoiding expensive test time exemplar retrieval. We further auto-adapt the GP to the target database domain (DA-GP), to better handle cross-domain generalization; followed by a decomposed Least-To-Most-Prompting (LTMP-DA-GP) to handle cross-compositional generalization. The synthesis of LTMP-DA-GP is an offline task, to be performed one-time per new database with minimal human intervention. Our approach demonstrates superior performance on the KaggleDBQA dataset, designed to evaluate generalizability for the Text-to-SQL task. We further showcase consistent performance improvement of LTMP-DA-GP over GP, across LLMs and databases of KaggleDBQA, highlighting the efficacy and model agnostic benefits of our prompt based adapt and decompose approach.