 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefend: Automated Rebuttals for Peer Review with Minimal Author Guidance
Mar 28, 2026Rebuttal generation is a critical component of the peer review process for scientific papers, enabling authors to clarify misunderstandings, correct factual inaccuracies, and guide reviewers toward a more accurate evaluation. We observe that Large Language Models (LLMs) often struggle to perform targeted refutation and maintain accurate factual grounding when used directly for rebuttal generation, highlighting the need for structured reasoning and author intervention. To address this, in the paper, we introduce DEFEND an LLM based tool designed to explicitly execute the underlying reasoning process of automated rebuttal generation, while keeping the author-in-the-loop. As opposed to writing the rebuttals from scratch, the author needs to only drive the reasoning process with minimal intervention, leading an efficient approach with minimal effort and less cognitive load. We compare DEFEND against three other paradigms: (i) Direct rebuttal generation using LLM (DRG), (ii) Segment-wise rebuttal generation using LLM (SWRG), and (iii) Sequential approach (SA) of segment-wise rebuttal generation without author intervention. To enable finegrained evaluation, we extend the ReviewCritique dataset, creating review segmentation, deficiency, error type annotations, rebuttal-action labels, and mapping to gold rebuttal segments. Experimental results and a user study demonstrate that directly using LLMs perform poorly in factual correctness and targeted refutation. Segment-wise generation and the automated sequential approach with author-in-the-loop, substantially improve factual correctness and strength of refutation.
REVERE: Reflective Evolving Research Engineer for Scientific Workflows
Mar 21, 2026Existing prompt-optimization techniques rely on local signals to update behavior, often neglecting broader and recurring patterns across tasks, leading to poor generalization; they further rely on full-prompt rewrites or unstructured merges, resulting in knowledge loss. These limitations are magnified in research-coding workflows, which involve heterogeneous repositories, underspecified environments, and weak feedback, where reproducing results from public codebases is an established evaluation regime. We introduce Reflective Evolving Research Engineer (REVERE), a framework that continuously learns from Global Training Context, recognizes recurring failure modes in cross-repository execution trajectories, distills them into reusable heuristics, and performs targeted edits across three configurable fields: the system prompt, a task-prompt template, and a cumulative cheatsheet. REVERE, via this reflective optimization framework, improves performance over prior state-of-the-art expert-crafted instructions on research coding tasks by 4.50% on SUPER, 3.51% on ResearchCodeBench, and 4.89% on ScienceAgentBench across their respective metrics. These results demonstrate that agents equipped with mechanisms for continual learning and global memory consolidation can meaningfully evolve their capabilities over time.
SciMDR: Benchmarking and Advancing Scientific Multimodal Document Reasoning
Mar 12, 2026Constructing scientific multimodal document reasoning datasets for foundation model training involves an inherent trade-off among scale, faithfulness, and realism. To address this challenge, we introduce the synthesize-and-reground framework, a two-stage pipeline comprising: (1) Claim-Centric QA Synthesis, which generates faithful, isolated QA pairs and reasoning on focused segments, and (2) Document-Scale Regrounding, which programmatically re-embeds these pairs into full-document tasks to ensure realistic complexity. Using this framework, we construct SciMDR, a large-scale training dataset for cross-modal comprehension, comprising 300K QA pairs with explicit reasoning chains across 20K scientific papers. We further construct SciMDR-Eval, an expert-annotated benchmark to evaluate multimodal comprehension within full-length scientific workflows. Experiments demonstrate that models fine-tuned on SciMDR achieve significant improvements across multiple scientific QA benchmarks, particularly in those tasks requiring complex document-level reasoning.
RbtAct: Rebuttal as Supervision for Actionable Review Feedback Generation
Mar 10, 2026Large language models (LLMs) are increasingly used across the scientific workflow, including to draft peer-review reports. However, many AI-generated reviews are superficial and insufficiently actionable, leaving authors without concrete, implementable guidance and motivating the gap this work addresses. We propose RbtAct, which targets actionable review feedback generation and places existing peer review rebuttal at the center of learning. Rebuttals show which reviewer comments led to concrete revisions or specific plans, and which were only defended. Building on this insight, we leverage rebuttal as implicit supervision to directly optimize a feedback generator for actionability. To support this objective, we propose a new task called perspective-conditioned segment-level review feedback generation, in which the model is required to produce a single focused comment based on the complete paper and a specified perspective such as experiments and writing. We also build a large dataset named RMR-75K that maps review segments to the rebuttal segments that address them, with perspective labels and impact categories that order author uptake. We then train the Llama-3.1-8B-Instruct model with supervised fine-tuning on review segments followed by preference optimization using rebuttal derived pairs. Experiments with human experts and LLM-as-a-judge show consistent gains in actionability and specificity over strong baselines while maintaining grounding and relevance.
ResearchGym: Evaluating Language Model Agents on Real-World AI Research
Feb 16, 2026We introduce ResearchGym, a benchmark and execution environment for evaluating AI agents on end-to-end research. To instantiate this, we repurpose five oral and spotlight papers from ICML, ICLR, and ACL. From each paper's repository, we preserve the datasets, evaluation harness, and baseline implementations but withhold the paper's proposed method. This results in five containerized task environments comprising 39 sub-tasks in total. Within each environment, agents must propose novel hypotheses, run experiments, and attempt to surpass strong human baselines on the paper's metrics. In a controlled evaluation of an agent powered by GPT-5, we observe a sharp capability--reliability gap. The agent improves over the provided baselines from the repository in just 1 of 15 evaluations (6.7%) by 11.5%, and completes only 26.5% of sub-tasks on average. We identify recurring long-horizon failure modes, including impatience, poor time and resource management, overconfidence in weak hypotheses, difficulty coordinating parallel experiments, and hard limits from context length. Yet in a single run, the agent surpasses the solution of an ICML 2025 Spotlight task, indicating that frontier agents can occasionally reach state-of-the-art performance, but do so unreliably. We additionally evaluate proprietary agent scaffolds including Claude Code (Opus-4.5) and Codex (GPT-5.2) which display a similar gap. ResearchGym provides infrastructure for systematic evaluation and analysis of autonomous agents on closed-loop research.
Routing End User Queries to Enterprise Databases
Jan 27, 2026We address the task of routing natural language queries in multi-database enterprise environments. We construct realistic benchmarks by extending existing NL-to-SQL datasets. Our study shows that routing becomes increasingly challenging with larger, domain-overlapping DB repositories and ambiguous queries, motivating the need for more structured and robust reasoning-based solutions. By explicitly modelling schema coverage, structural connectivity, and fine-grained semantic alignment, the proposed modular, reasoning-driven reranking strategy consistently outperforms embedding-only and direct LLM-prompting baselines across all the metrics.
Quality Detection of Stored Potatoes via Transfer Learning: A CNN and Vision Transformer Approach
Jan 02, 2026Image-based deep learning provides a non-invasive, scalable solution for monitoring potato quality during storage, addressing key challenges such as sprout detection, weight loss estimation, and shelf-life prediction. In this study, images and corresponding weight data were collected over a 200-day period under controlled temperature and humidity conditions. Leveraging powerful pre-trained architectures of ResNet, VGG, DenseNet, and Vision Transformer (ViT), we designed two specialized models: (1) a high-precision binary classifier for sprout detection, and (2) an advanced multi-class predictor to estimate weight loss and forecast remaining shelf-life with remarkable accuracy. DenseNet achieved exceptional performance, with 98.03% accuracy in sprout detection. Shelf-life prediction models performed best with coarse class divisions (2-5 classes), achieving over 89.83% accuracy, while accuracy declined for finer divisions (6-8 classes) due to subtle visual differences and limited data per class. These findings demonstrate the feasibility of integrating image-based models into automated sorting and inventory systems, enabling early identification of sprouted potatoes and dynamic categorization based on storage stage. Practical implications include improved inventory management, differential pricing strategies, and reduced food waste across supply chains. While predicting exact shelf-life intervals remains challenging, focusing on broader class divisions ensures robust performance. Future research should aim to develop generalized models trained on diverse potato varieties and storage conditions to enhance adaptability and scalability. Overall, this approach offers a cost-effective, non-destructive method for quality assessment, supporting efficiency and sustainability in potato storage and distribution.
SciRAG: Adaptive, Citation-Aware, and Outline-Guided Retrieval and Synthesis for Scientific Literature
Nov 18, 2025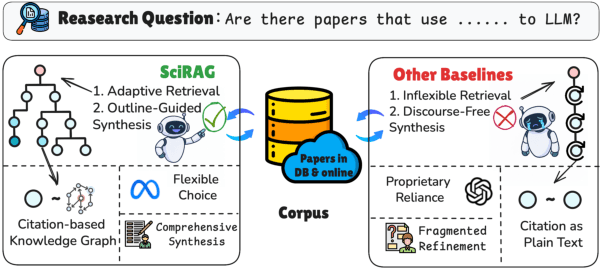
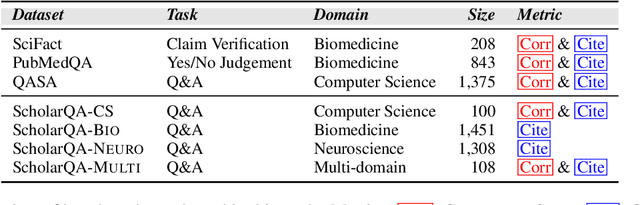
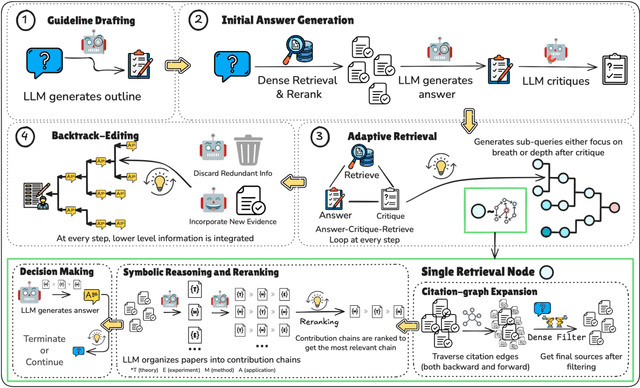
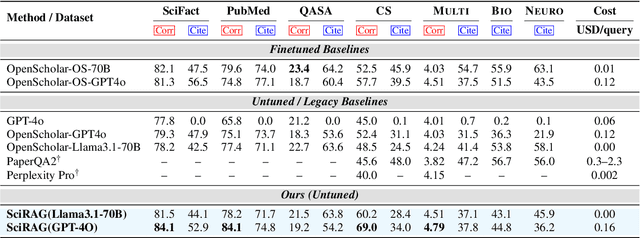
The accelerating growth of scientific publications has intensified the need for scalable, trustworthy systems to synthesize knowledge across diverse literature. While recent retrieval-augmented generation (RAG) methods have improved access to scientific information, they often overlook citation graph structure, adapt poorly to complex queries, and yield fragmented, hard-to-verify syntheses. We introduce SciRAG, an open-source framework for scientific literature exploration that addresses these gaps through three key innovations: (1) adaptive retrieval that flexibly alternates between sequential and parallel evidence gathering; (2) citation-aware symbolic reasoning that leverages citation graphs to organize and filter supporting documents; and (3) outline-guided synthesis that plans, critiques, and refines answers to ensure coherence and transparent attribution. Extensive experiments across multiple benchmarks such as QASA and ScholarQA demonstrate that SciRAG outperforms prior systems in factual accuracy and synthesis quality, establishing a new foundation for reliable, large-scale scientific knowledge aggregation.
AbGen: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research
Jul 17, 2025We introduce AbGen, the first benchmark designed to evaluate the capabilities of LLMs in designing ablation studies for scientific research. AbGen consists of 1,500 expert-annotated examples derived from 807 NLP papers. In this benchmark, LLMs are tasked with generating detailed ablation study designs for a specified module or process based on the given research context. Our evaluation of leading LLMs, such as DeepSeek-R1-0528 and o4-mini, highlights a significant performance gap between these models and human experts in terms of the importance, faithfulness, and soundness of the ablation study designs. Moreover, we demonstrate that current automated evaluation methods are not reliable for our task, as they show a significant discrepancy when compared to human assessment. To better investigate this, we develop AbGen-Eval, a meta-evaluation benchmark designed to assess the reliability of commonly used automated evaluation systems in measuring LLM performance on our task. We investigate various LLM-as-Judge systems on AbGen-Eval, providing insights for future research on developing more effective and reliable LLM-based evaluation systems for complex scientific tasks.
Can LLMs Identify Critical Limitations within Scientific Research? A Systematic Evaluation on AI Research Papers
Jul 03, 2025Peer review is fundamental to scientific research, but the growing volume of publications has intensified the challenges of this expertise-intensive process. While LLMs show promise in various scientific tasks, their potential to assist with peer review, particularly in identifying paper limitations, remains understudied. We first present a comprehensive taxonomy of limitation types in scientific research, with a focus on AI. Guided by this taxonomy, for studying limitations, we present LimitGen, the first comprehensive benchmark for evaluating LLMs' capability to support early-stage feedback and complement human peer review. Our benchmark consists of two subsets: LimitGen-Syn, a synthetic dataset carefully created through controlled perturbations of high-quality papers, and LimitGen-Human, a collection of real human-written limitations. To improve the ability of LLM systems to identify limitations, we augment them with literature retrieval, which is essential for grounding identifying limitations in prior scientific findings. Our approach enhances the capabilities of LLM systems to generate limitations in research papers, enabling them to provide more concrete and constructive feedback.