 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer for Pseudo-code Generation from Low Resource Programming Language
Mar 16, 2023



Generation of pseudo-code descriptions of legacy source code for software maintenance is a manually intensive task. Recent encoder-decoder language models have shown promise for automating pseudo-code generation for high resource programming languages such as C++, but are heavily reliant on the availability of a large code-pseudocode corpus. Soliciting such pseudocode annotations for codes written in legacy programming languages (PL) is a time consuming and costly affair requiring a thorough understanding of the source PL. In this paper, we focus on transferring the knowledge acquired by the code-to-pseudocode neural model trained on a high resource PL (C++) using parallel code-pseudocode data. We aim to transfer this knowledge to a legacy PL (C) with no PL-pseudocode parallel data for training. To achieve this, we utilize an Iterative Back Translation (IBT) approach with a novel test-cases based filtration strategy, to adapt the trained C++-to-pseudocode model to C-to-pseudocode model. We observe an improvement of 23.27% in the success rate of the generated C codes through back translation, over the successive IBT iteration, illustrating the efficacy of our approach.
Ashwin: Plug-and-Play System for Machine-Human Image Annotation
Sep 09, 2016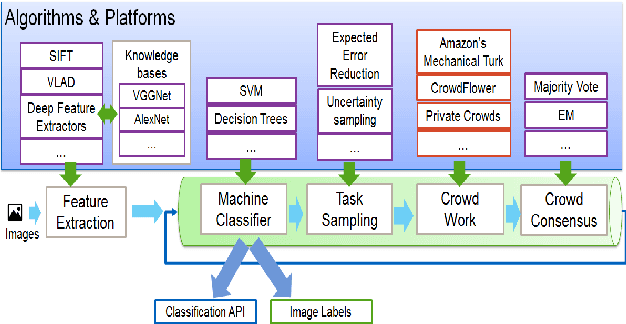
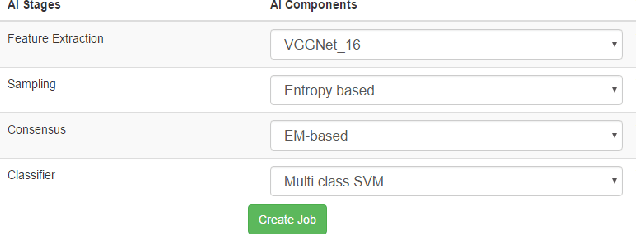
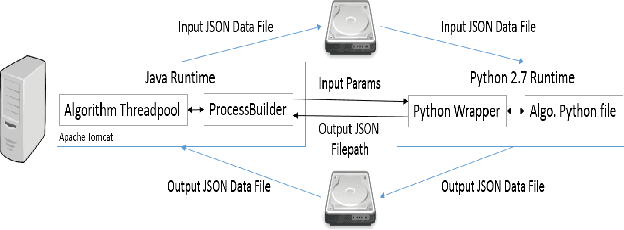
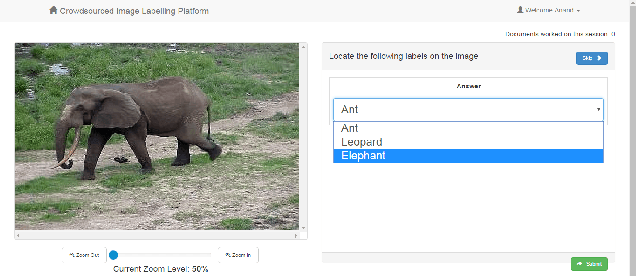
We present an end-to-end machine-human image annotation system where each component can be attached in a plug-and-play fashion. These components include Feature Extraction, Machine Classifier, Task Sampling and Crowd Consensus.