 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Optimizing RAG for Domain Chatbots
Jan 10, 2024



With the advent of Large Language Models (LLM), conversational assistants have become prevalent for domain use cases. LLMs acquire the ability to contextual question answering through training, and Retrieval Augmented Generation (RAG) further enables the bot to answer domain-specific questions. This paper describes a RAG-based approach for building a chatbot that answers user's queries using Frequently Asked Questions (FAQ) data. We train an in-house retrieval embedding model using infoNCE loss, and experimental results demonstrate that the in-house model works significantly better than the well-known general-purpose public embedding model, both in terms of retrieval accuracy and Out-of-Domain (OOD) query detection. As an LLM, we use an open API-based paid ChatGPT model. We noticed that a previously retrieved-context could be used to generate an answer for specific patterns/sequences of queries (e.g., follow-up queries). Hence, there is a scope to optimize the number of LLM tokens and cost. Assuming a fixed retrieval model and an LLM, we optimize the number of LLM tokens using Reinforcement Learning (RL). Specifically, we propose a policy-based model external to the RAG, which interacts with the RAG pipeline through policy actions and updates the policy to optimize the cost. The policy model can perform two actions: to fetch FAQ context or skip retrieval. We use the open API-based GPT-4 as the reward model. We then train a policy model using policy gradient on multiple training chat sessions. As a policy model, we experimented with a public gpt-2 model and an in-house BERT model. With the proposed RL-based optimization combined with similarity threshold, we are able to achieve significant cost savings while getting a slightly improved accuracy. Though we demonstrate results for the FAQ chatbot, the proposed RL approach is generic and can be experimented with any existing RAG pipeline.
Study of Encoder-Decoder Architectures for Code-Mix Search Query Translation
Aug 07, 2022


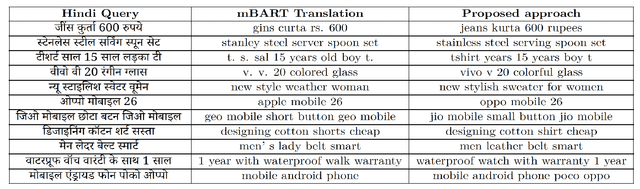
With the broad reach of the internet and smartphones, e-commerce platforms have an increasingly diversified user base. Since native language users are not conversant in English, their preferred browsing mode is their regional language or a combination of their regional language and English. From our recent study on the query data, we noticed that many of the queries we receive are code-mix, specifically Hinglish i.e. queries with one or more Hindi words written in English (Latin) script. We propose a transformer-based approach for code-mix query translation to enable users to search with these queries. We demonstrate the effectiveness of pre-trained encoder-decoder models trained on a large corpus of the unlabeled English text for this task. Using generic domain translation models, we created a pseudo-labelled dataset for training the model on the search queries and verified the effectiveness of various data augmentation techniques. Further, to reduce the latency of the model, we use knowledge distillation and weight quantization. Effectiveness of the proposed method has been validated through experimental evaluations and A/B testing. The model is currently live on Flipkart app and website, serving millions of queries.
Vernacular Search Query Translation with Unsupervised Domain Adaptation
Aug 07, 2022


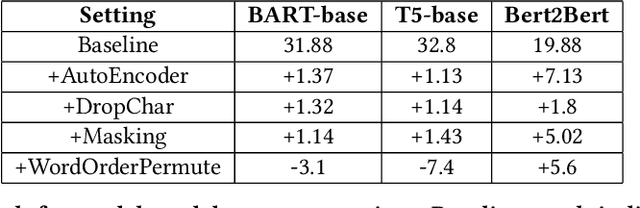
With the democratization of e-commerce platforms, an increasingly diversified user base is opting to shop online. To provide a comfortable and reliable shopping experience, it's important to enable users to interact with the platform in the language of their choice. An accurate query translation is essential for Cross-Lingual Information Retrieval (CLIR) with vernacular queries. Due to internet-scale operations, e-commerce platforms get millions of search queries every day. However, creating a parallel training set to train an in-domain translation model is cumbersome. This paper proposes an unsupervised domain adaptation approach to translate search queries without using any parallel corpus. We use an open-domain translation model (trained on public corpus) and adapt it to the query data using only the monolingual queries from two languages. In addition, fine-tuning with a small labeled set further improves the result. For demonstration, we show results for Hindi to English query translation and use mBART-large-50 model as the baseline to improve upon. Experimental results show that, without using any parallel corpus, we obtain more than 20 BLEU points improvement over the baseline while fine-tuning with a small 50k labeled set provides more than 27 BLEU points improvement over the baseline.
Deep Q learning for fooling neural networks
Nov 13, 2018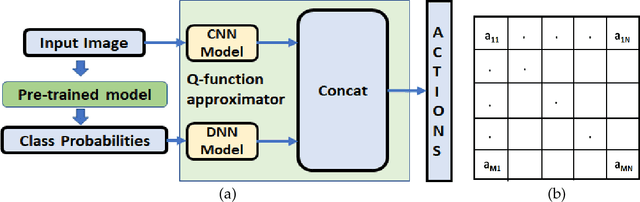


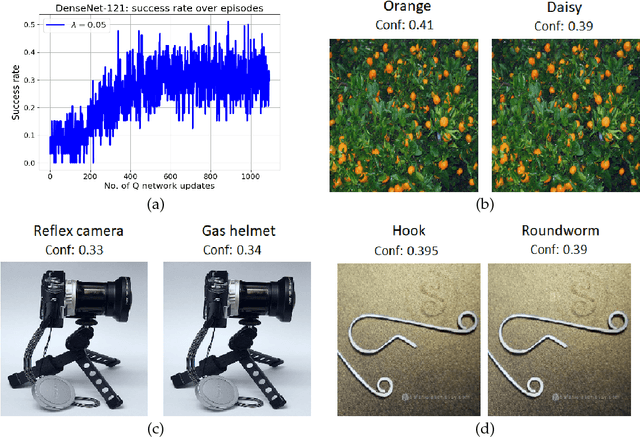
Deep learning models are vulnerable to external attacks. In this paper, we propose a Reinforcement Learning (RL) based approach to generate adversarial examples for the pre-trained (target) models. We assume a semi black-box setting where the only access an adversary has to the target model is the class probabilities obtained for the input queries. We train a Deep Q Network (DQN) agent which, with experience, learns to attack only a small portion of image pixels to generate non-targeted adversarial images. Initially, an agent explores an environment by sequentially modifying random sets of image pixels and observes its effect on the class probabilities. At the end of an episode, it receives a positive (negative) reward if it succeeds (fails) to alter the label of the image. Experimental results with MNIST, CIFAR-10 and Imagenet datasets demonstrate that our RL framework is able to learn an effective attack policy.
Siamese networks for generating adversarial examples
May 03, 2018
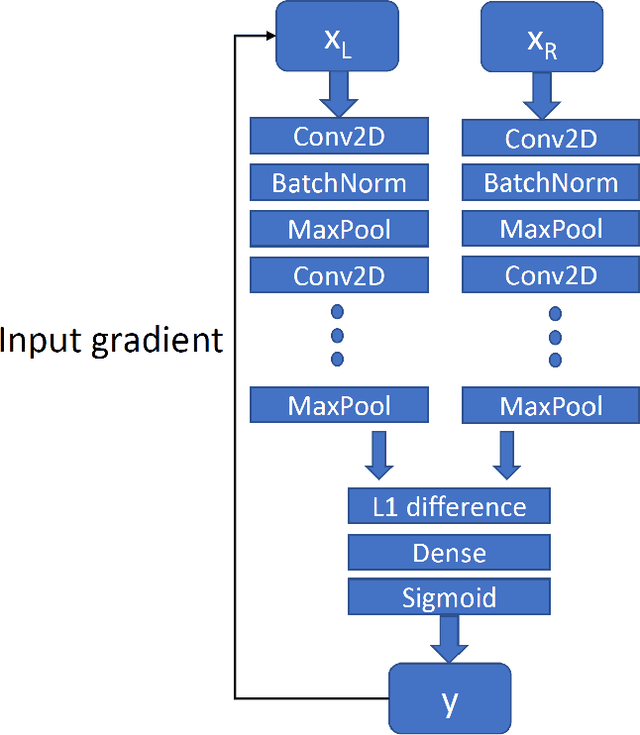


Machine learning models are vulnerable to adversarial examples. An adversary modifies the input data such that humans still assign the same label, however, machine learning models misclassify it. Previous approaches in the literature demonstrated that adversarial examples can even be generated for the remotely hosted model. In this paper, we propose a Siamese network based approach to generate adversarial examples for a multiclass target CNN. We assume that the adversary do not possess any knowledge of the target data distribution, and we use an unlabeled mismatched dataset to query the target, e.g., for the ResNet-50 target, we use the Food-101 dataset as the query. Initially, the target model assigns labels to the query dataset, and a Siamese network is trained on the image pairs derived from these multiclass labels. We learn the \emph{adversarial perturbations} for the Siamese model and show that these perturbations are also adversarial w.r.t. the target model. In experimental results, we demonstrate effectiveness of our approach on MNIST, CIFAR-10 and ImageNet targets with TinyImageNet/Food-101 query datasets.
Knowledge distillation using unlabeled mismatched images
Mar 21, 2017



Current approaches for Knowledge Distillation (KD) either directly use training data or sample from the training data distribution. In this paper, we demonstrate effectiveness of 'mismatched' unlabeled stimulus to perform KD for image classification networks. For illustration, we consider scenarios where this is a complete absence of training data, or mismatched stimulus has to be used for augmenting a small amount of training data. We demonstrate that stimulus complexity is a key factor for distillation's good performance. Our examples include use of various datasets for stimulating MNIST and CIFAR teachers.
Layer-wise training of deep networks using kernel similarity
Mar 21, 2017



Deep learning has shown promising results in many machine learning applications. The hierarchical feature representation built by deep networks enable compact and precise encoding of the data. A kernel analysis of the trained deep networks demonstrated that with deeper layers, more simple and more accurate data representations are obtained. In this paper, we propose an approach for layer-wise training of a deep network for the supervised classification task. A transformation matrix of each layer is obtained by solving an optimization aimed at a better representation where a subsequent layer builds its representation on the top of the features produced by a previous layer. We compared the performance of our approach with a DNN trained using back-propagation which has same architecture as ours. Experimental results on the real image datasets demonstrate efficacy of our approach. We also performed kernel analysis of layer representations to validate the claim of better feature encoding.
Stamp processing with examplar features
Sep 16, 2016


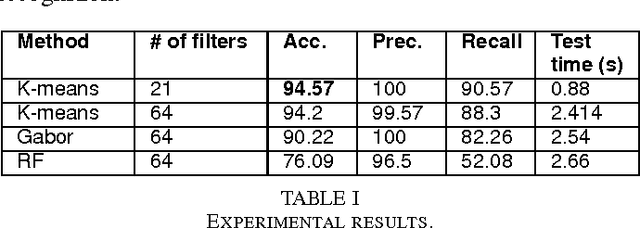
Document digitization is becoming increasingly crucial. In this work, we propose a shape based approach for automatic stamp verification/detection in document images using an unsupervised feature learning. Given a small set of training images, our algorithm learns an appropriate shape representation using an unsupervised clustering. Experimental results demonstrate the effectiveness of our framework in challenging scenarios.
Ashwin: Plug-and-Play System for Machine-Human Image Annotation
Sep 09, 2016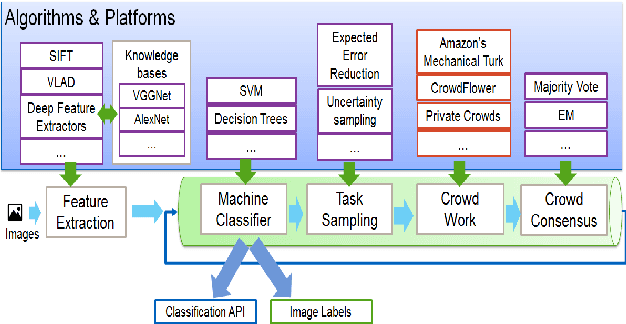
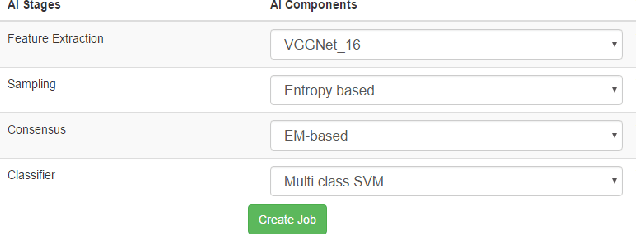
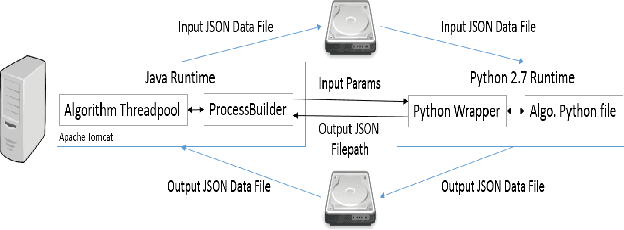
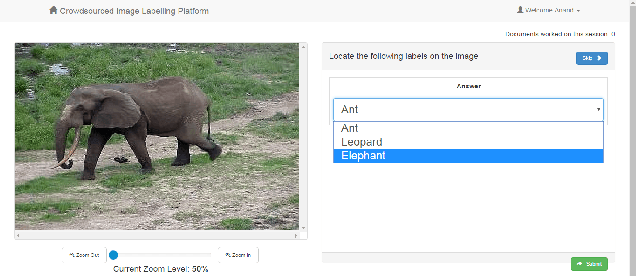
We present an end-to-end machine-human image annotation system where each component can be attached in a plug-and-play fashion. These components include Feature Extraction, Machine Classifier, Task Sampling and Crowd Consensus.