 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Free Domain Adaptation for Translation of Noisy Questions with Question Specific Rewards
Oct 23, 2023
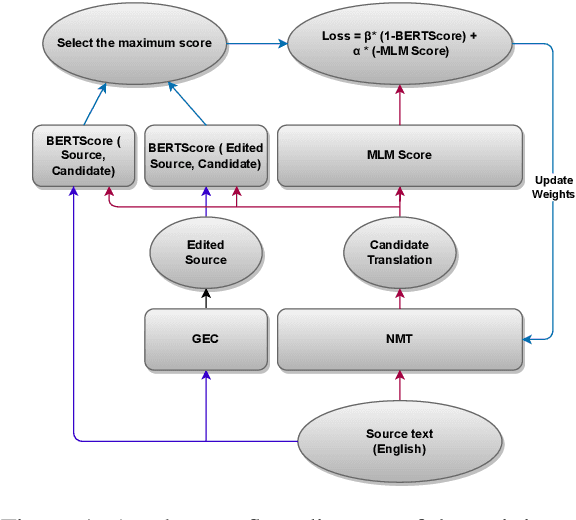


Community Question-Answering (CQA) portals serve as a valuable tool for helping users within an organization. However, making them accessible to non-English-speaking users continues to be a challenge. Translating questions can broaden the community's reach, benefiting individuals with similar inquiries in various languages. Translating questions using Neural Machine Translation (NMT) poses more challenges, especially in noisy environments, where the grammatical correctness of the questions is not monitored. These questions may be phrased as statements by non-native speakers, with incorrect subject-verb order and sometimes even missing question marks. Creating a synthetic parallel corpus from such data is also difficult due to its noisy nature. To address this issue, we propose a training methodology that fine-tunes the NMT system only using source-side data. Our approach balances adequacy and fluency by utilizing a loss function that combines BERTScore and Masked Language Model (MLM) Score. Our method surpasses the conventional Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on synthetic target data, by achieving a 1.9 BLEU score improvement. Our model exhibits robustness while we add noise to our baseline, and still achieve 1.1 BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed methodology is model-agnostic and is only necessary during the training phase. We make the codes and datasets publicly available at \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html#DomainAdapt} for facilitating further research.
Study of Encoder-Decoder Architectures for Code-Mix Search Query Translation
Aug 07, 2022

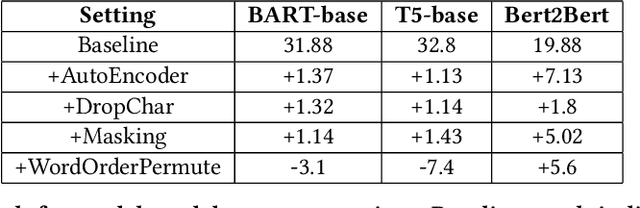

With the broad reach of the internet and smartphones, e-commerce platforms have an increasingly diversified user base. Since native language users are not conversant in English, their preferred browsing mode is their regional language or a combination of their regional language and English. From our recent study on the query data, we noticed that many of the queries we receive are code-mix, specifically Hinglish i.e. queries with one or more Hindi words written in English (Latin) script. We propose a transformer-based approach for code-mix query translation to enable users to search with these queries. We demonstrate the effectiveness of pre-trained encoder-decoder models trained on a large corpus of the unlabeled English text for this task. Using generic domain translation models, we created a pseudo-labelled dataset for training the model on the search queries and verified the effectiveness of various data augmentation techniques. Further, to reduce the latency of the model, we use knowledge distillation and weight quantization. Effectiveness of the proposed method has been validated through experimental evaluations and A/B testing. The model is currently live on Flipkart app and website, serving millions of queries.