 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Opinions at Scale: Incremental Opinion Summarization using XL-OPSUMM
Jun 16, 2024



Opinion summarization in e-commerce encapsulates the collective views of numerous users about a product based on their reviews. Typically, a product on an e-commerce platform has thousands of reviews, each review comprising around 10-15 words. While Large Language Models (LLMs) have shown proficiency in summarization tasks, they struggle to handle such a large volume of reviews due to context limitations. To mitigate, we propose a scalable framework called Xl-OpSumm that generates summaries incrementally. However, the existing test set, AMASUM has only 560 reviews per product on average. Due to the lack of a test set with thousands of reviews, we created a new test set called Xl-Flipkart by gathering data from the Flipkart website and generating summaries using GPT-4. Through various automatic evaluations and extensive analysis, we evaluated the framework's efficiency on two datasets, AMASUM and Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1 gain of 3.70% over the next best-performing model.
Product Description and QA Assisted Self-Supervised Opinion Summarization
Apr 08, 2024



In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Feb 23, 2024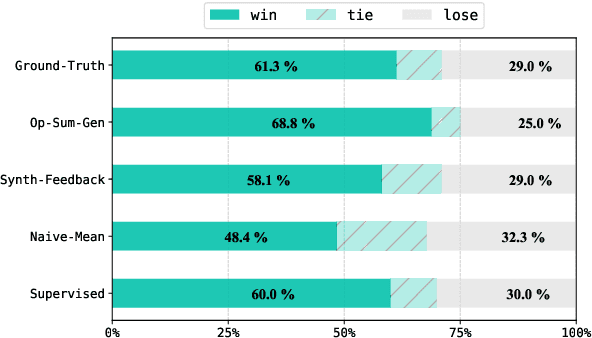



Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in steering Language Models (LMs) towards human values/goals. The key to the strategy is employing a reward model ({$\varphi$}) which can reflect a latent reward model with humans. While this strategy has proven to be effective, the training methodology requires a lot of human preference annotation (usually of the order of tens of thousands) to train {$\varphi$}. Such large-scale preference annotations can be achievable if the reward model can be ubiquitously used. However, human values/goals are subjective and depend on the nature of the task. This poses a challenge in collecting diverse preferences for downstream applications. To address this, we propose a novel methodology to infuse domain knowledge into {$\varphi$}, which reduces the size of preference annotation required. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (just $940$ samples) while advancing the state-of-the-art. Our contributions include a novel Reward Modelling technique, a new dataset (PromptOpinSumm) for Opinion Summarization, and a human preference dataset (OpinPref). The proposed methodology opens avenues for efficient RLHF, making it more adaptable to diverse applications with varying human values. We release the artifacts for usage under MIT License.
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Feb 18, 2024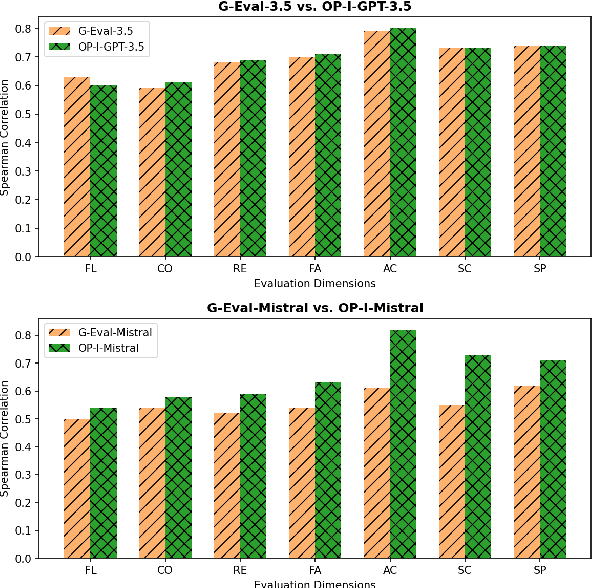



Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.
Reference Free Domain Adaptation for Translation of Noisy Questions with Question Specific Rewards
Oct 23, 2023
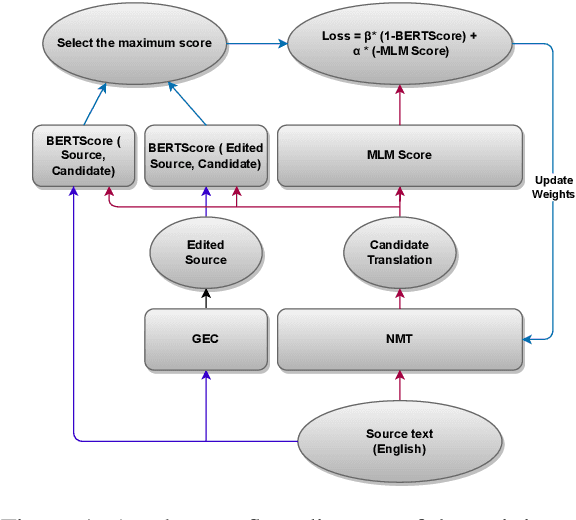


Community Question-Answering (CQA) portals serve as a valuable tool for helping users within an organization. However, making them accessible to non-English-speaking users continues to be a challenge. Translating questions can broaden the community's reach, benefiting individuals with similar inquiries in various languages. Translating questions using Neural Machine Translation (NMT) poses more challenges, especially in noisy environments, where the grammatical correctness of the questions is not monitored. These questions may be phrased as statements by non-native speakers, with incorrect subject-verb order and sometimes even missing question marks. Creating a synthetic parallel corpus from such data is also difficult due to its noisy nature. To address this issue, we propose a training methodology that fine-tunes the NMT system only using source-side data. Our approach balances adequacy and fluency by utilizing a loss function that combines BERTScore and Masked Language Model (MLM) Score. Our method surpasses the conventional Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on synthetic target data, by achieving a 1.9 BLEU score improvement. Our model exhibits robustness while we add noise to our baseline, and still achieve 1.1 BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed methodology is model-agnostic and is only necessary during the training phase. We make the codes and datasets publicly available at \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html#DomainAdapt} for facilitating further research.
An Application to Generate Style Guided Compatible Outfit
May 02, 2022Fashion recommendation has witnessed a phenomenal growth of research, particularly in the domains of shop-the-look, contextaware outfit creation, personalizing outfit creation etc. Majority of the work in this area focuses on better understanding of the notion of complimentary relationship between lifestyle items. Quite recently, some works have realised that style plays a vital role in fashion, especially in the understanding of compatibility learning and outfit creation. In this paper, we would like to present the end-to-end design of a methodology in which we aim to generate outfits guided by styles or themes using a novel style encoder network. We present an extensive analysis of different aspects of our method through various experiments. We also provide a demonstration api to showcase the ability of our work in generating outfits based on an anchor item and styles.
Recommendation of Compatible Outfits Conditioned on Style
Mar 30, 2022

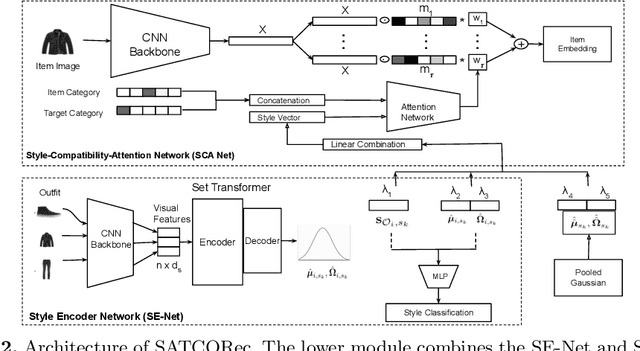

Recommendation in the fashion domain has seen a recent surge in research in various areas, for example, shop-the-look, context-aware outfit creation, personalizing outfit creation, etc. The majority of state of the art approaches in the domain of outfit recommendation pursue to improve compatibility among items so as to produce high quality outfits. Some recent works have realized that style is an important factor in fashion and have incorporated it in compatibility learning and outfit generation. These methods often depend on the availability of fine-grained product categories or the presence of rich item attributes (e.g., long-skirt, mini-skirt, etc.). In this work, we aim to generate outfits conditional on styles or themes as one would dress in real life, operating under the practical assumption that each item is mapped to a high level category as driven by the taxonomy of an online portal, like outdoor, formal etc and an image. We use a novel style encoder network that renders outfit styles in a smooth latent space. We present an extensive analysis of different aspects of our method and demonstrate its superiority over existing state of the art baselines through rigorous experiments.