 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Opinions at Scale: Incremental Opinion Summarization using XL-OPSUMM
Jun 16, 2024



Opinion summarization in e-commerce encapsulates the collective views of numerous users about a product based on their reviews. Typically, a product on an e-commerce platform has thousands of reviews, each review comprising around 10-15 words. While Large Language Models (LLMs) have shown proficiency in summarization tasks, they struggle to handle such a large volume of reviews due to context limitations. To mitigate, we propose a scalable framework called Xl-OpSumm that generates summaries incrementally. However, the existing test set, AMASUM has only 560 reviews per product on average. Due to the lack of a test set with thousands of reviews, we created a new test set called Xl-Flipkart by gathering data from the Flipkart website and generating summaries using GPT-4. Through various automatic evaluations and extensive analysis, we evaluated the framework's efficiency on two datasets, AMASUM and Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1 gain of 3.70% over the next best-performing model.
Product Description and QA Assisted Self-Supervised Opinion Summarization
Apr 08, 2024



In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Feb 23, 2024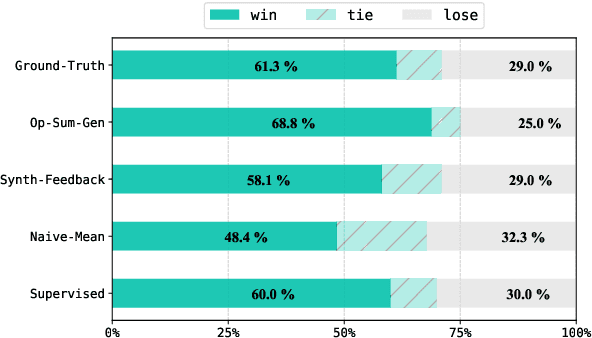



Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in steering Language Models (LMs) towards human values/goals. The key to the strategy is employing a reward model ({$\varphi$}) which can reflect a latent reward model with humans. While this strategy has proven to be effective, the training methodology requires a lot of human preference annotation (usually of the order of tens of thousands) to train {$\varphi$}. Such large-scale preference annotations can be achievable if the reward model can be ubiquitously used. However, human values/goals are subjective and depend on the nature of the task. This poses a challenge in collecting diverse preferences for downstream applications. To address this, we propose a novel methodology to infuse domain knowledge into {$\varphi$}, which reduces the size of preference annotation required. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (just $940$ samples) while advancing the state-of-the-art. Our contributions include a novel Reward Modelling technique, a new dataset (PromptOpinSumm) for Opinion Summarization, and a human preference dataset (OpinPref). The proposed methodology opens avenues for efficient RLHF, making it more adaptable to diverse applications with varying human values. We release the artifacts for usage under MIT License.
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Feb 18, 2024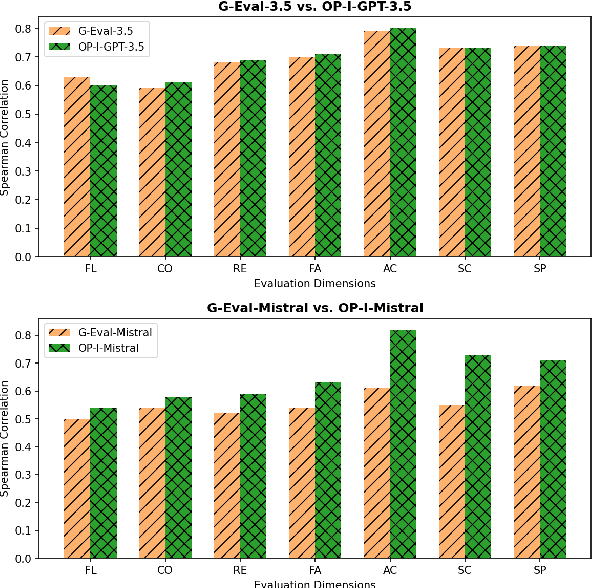



Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.
A Match Made in Heaven: A Multi-task Framework for Hyperbole and Metaphor Detection
May 30, 2023Hyperbole and metaphor are common in day-to-day communication (e.g., "I am in deep trouble": how does trouble have depth?), which makes their detection important, especially in a conversational AI setting. Existing approaches to automatically detect metaphor and hyperbole have studied these language phenomena independently, but their relationship has hardly, if ever, been explored computationally. In this paper, we propose a multi-task deep learning framework to detect hyperbole and metaphor simultaneously. We hypothesize that metaphors help in hyperbole detection, and vice-versa. To test this hypothesis, we annotate two hyperbole datasets- HYPO and HYPO-L- with metaphor labels. Simultaneously, we annotate two metaphor datasets- TroFi and LCC- with hyperbole labels. Experiments using these datasets give an improvement of the state of the art of hyperbole detection by 12%. Additionally, our multi-task learning (MTL) approach shows an improvement of up to 17% over single-task learning (STL) for both hyperbole and metaphor detection, supporting our hypothesis. To the best of our knowledge, ours is the first demonstration of computational leveraging of linguistic intimacy between metaphor and hyperbole, leading to showing the superiority of MTL over STL for hyperbole and metaphor detection.