 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Unseen: Visual Metaphor Captioning for Videos
Jun 07, 2024Metaphors are a common communication tool used in our day-to-day life. The detection and generation of metaphors in textual form have been studied extensively but metaphors in other forms have been under-explored. Recent studies have shown that Vision-Language (VL) models cannot understand visual metaphors in memes and adverts. As of now, no probing studies have been done that involve complex language phenomena like metaphors with videos. Hence, we introduce a new VL task of describing the metaphors present in the videos in our work. To facilitate this novel task, we construct and release a manually created dataset with 705 videos and 2115 human-written captions, along with a new metric called Average Concept Distance (ACD), to automatically evaluate the creativity of the metaphors generated. We also propose a novel low-resource video metaphor captioning system: GIT-LLaVA, which obtains comparable performance to SoTA video language models on the proposed task. We perform a comprehensive analysis of existing video language models on this task and publish our dataset, models, and benchmark results to enable further research.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
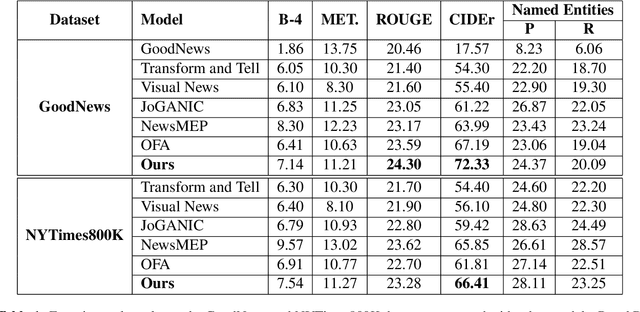
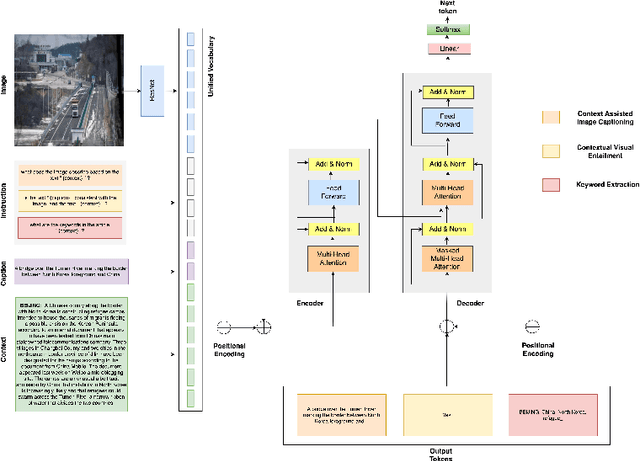
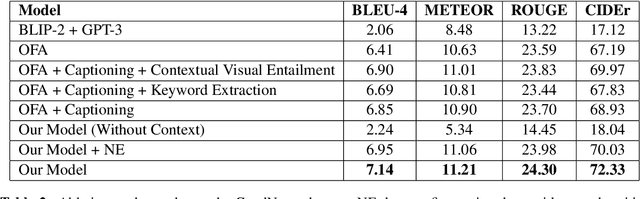
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
A Match Made in Heaven: A Multi-task Framework for Hyperbole and Metaphor Detection
May 30, 2023Hyperbole and metaphor are common in day-to-day communication (e.g., "I am in deep trouble": how does trouble have depth?), which makes their detection important, especially in a conversational AI setting. Existing approaches to automatically detect metaphor and hyperbole have studied these language phenomena independently, but their relationship has hardly, if ever, been explored computationally. In this paper, we propose a multi-task deep learning framework to detect hyperbole and metaphor simultaneously. We hypothesize that metaphors help in hyperbole detection, and vice-versa. To test this hypothesis, we annotate two hyperbole datasets- HYPO and HYPO-L- with metaphor labels. Simultaneously, we annotate two metaphor datasets- TroFi and LCC- with hyperbole labels. Experiments using these datasets give an improvement of the state of the art of hyperbole detection by 12%. Additionally, our multi-task learning (MTL) approach shows an improvement of up to 17% over single-task learning (STL) for both hyperbole and metaphor detection, supporting our hypothesis. To the best of our knowledge, ours is the first demonstration of computational leveraging of linguistic intimacy between metaphor and hyperbole, leading to showing the superiority of MTL over STL for hyperbole and metaphor detection.