 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving User Behavior Prediction: Leveraging Annotator Metadata in Supervised Machine Learning Models
Mar 26, 2025Supervised machine-learning models often underperform in predicting user behaviors from conversational text, hindered by poor crowdsourced label quality and low NLP task accuracy. We introduce the Metadata-Sensitive Weighted-Encoding Ensemble Model (MSWEEM), which integrates annotator meta-features like fatigue and speeding. First, our results show MSWEEM outperforms standard ensembles by 14\% on held-out data and 12\% on an alternative dataset. Second, we find that incorporating signals of annotator behavior, such as speed and fatigue, significantly boosts model performance. Third, we find that annotators with higher qualifications, such as Master's, deliver more consistent and faster annotations. Given the increasing uncertainty over annotation quality, our experiments show that understanding annotator patterns is crucial for enhancing model accuracy in user behavior prediction.
Is your LLM trapped in a Mental Set? Investigative study on how mental sets affect the reasoning capabilities of LLMs
Jan 21, 2025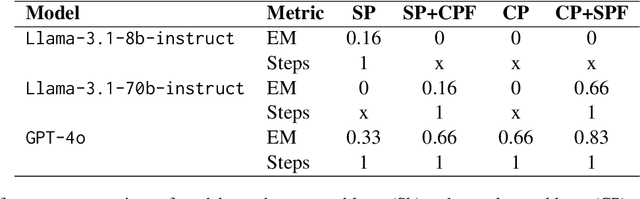
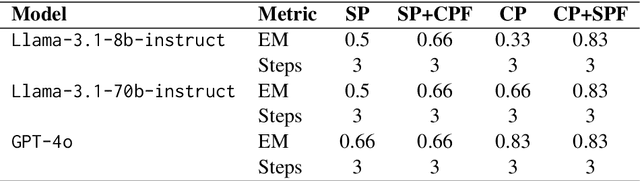

In this paper, we present an investigative study on how Mental Sets influence the reasoning capabilities of LLMs. LLMs have excelled in diverse natural language processing (NLP) tasks, driven by advancements in parameter-efficient fine-tuning (PEFT) and emergent capabilities like in-context learning (ICL). For complex reasoning tasks, selecting the right model for PEFT or ICL is critical, often relying on scores on benchmarks such as MMLU, MATH, and GSM8K. However, current evaluation methods, based on metrics like F1 Score or reasoning chain assessments by larger models, overlook a key dimension: adaptability to unfamiliar situations and overcoming entrenched thinking patterns. In cognitive psychology, Mental Set refers to the tendency to persist with previously successful strategies, even when they become inefficient - a challenge for problem solving and reasoning. We compare the performance of LLM models like Llama-3.1-8B-Instruct, Llama-3.1-70B-Instruct and GPT-4o in the presence of mental sets. To the best of our knowledge, this is the first study to integrate cognitive psychology concepts into the evaluation of LLMs for complex reasoning tasks, providing deeper insights into their adaptability and problem-solving efficacy.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
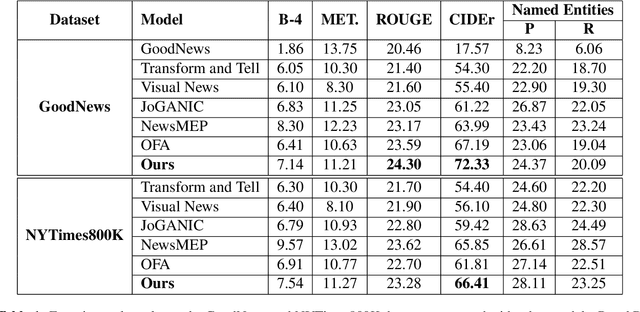
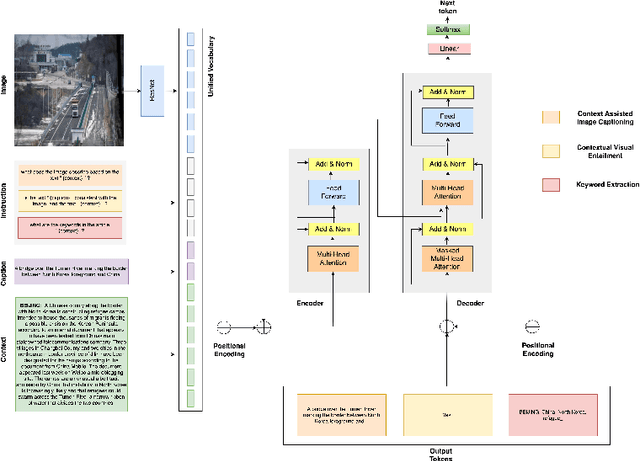
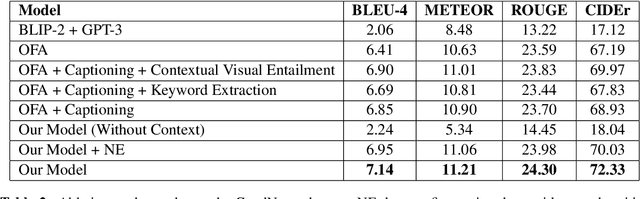
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
EmpathBERT: A BERT-based Framework for Demographic-aware Empathy Prediction
Jan 30, 2021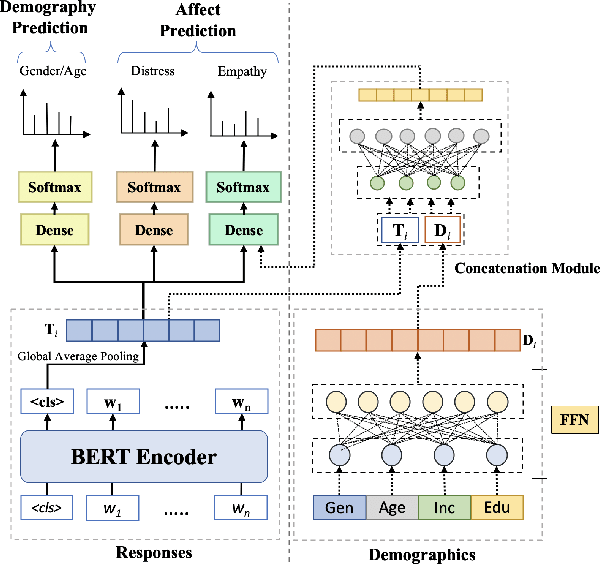

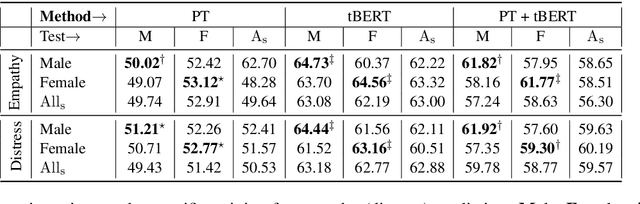
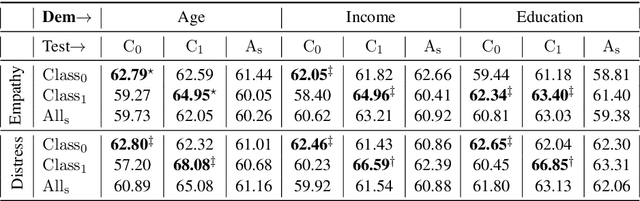
Affect preferences vary with user demographics, and tapping into demographic information provides important cues about the users' language preferences. In this paper, we utilize the user demographics, and propose EmpathBERT, a demographic-aware framework for empathy prediction based on BERT. Through several comparative experiments, we show that EmpathBERT surpasses traditional machine learning and deep learning models, and illustrate the importance of user demographics to predict empathy and distress in user responses to stimulative news articles. We also highlight the importance of affect information in the responses by developing affect-aware models to predict user demographic attributes.
Recognizing Emotion Cause in Conversations
Dec 24, 2020

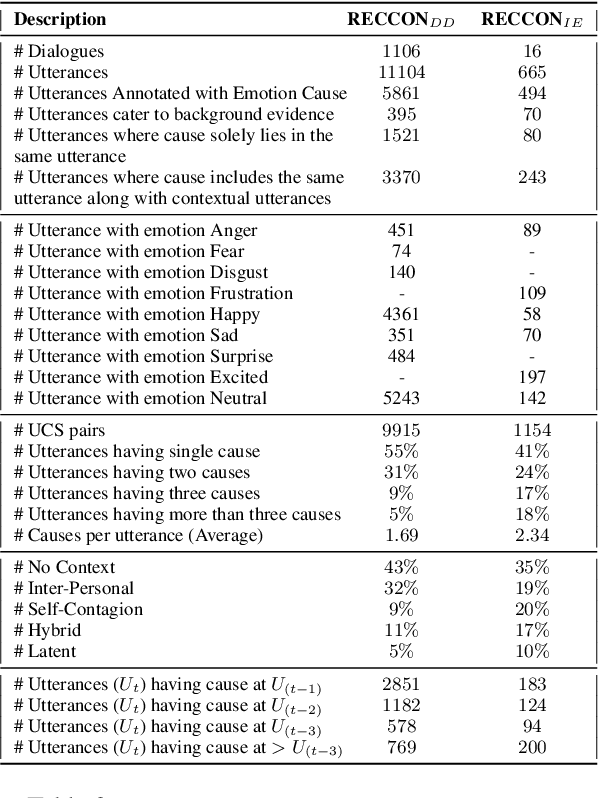

Recognizing the cause behind emotions in text is a fundamental yet under-explored area of research in NLP. Advances in this area hold the potential to improve interpretability and performance in affect-based models. Identifying emotion causes at the utterance level in conversations is particularly challenging due to the intermingling dynamic among the interlocutors. To this end, we introduce the task of recognizing emotion cause in conversations with an accompanying dataset named RECCON. Furthermore, we define different cause types based on the source of the causes and establish strong transformer-based baselines to address two different sub-tasks of RECCON: 1) Causal Span Extraction and 2) Causal Emotion Entailment. The dataset is available at https://github.com/declare-lab/RECCON.
An Integrated Approach for Improving Brand Consistency of Web Content: Modeling, Analysis and Recommendation
Nov 20, 2020
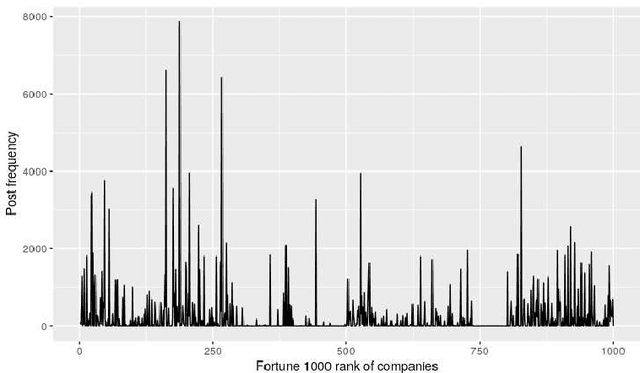
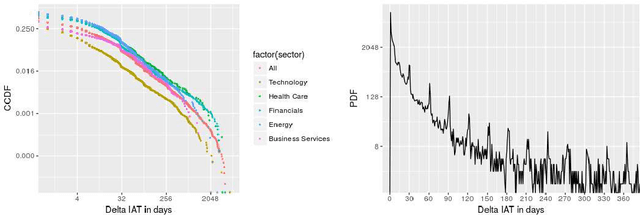
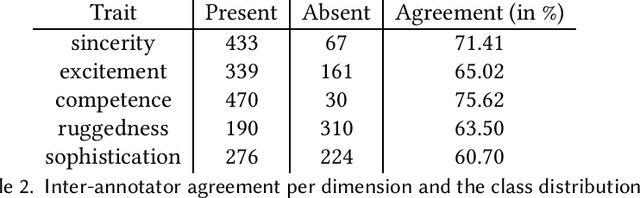
A consumer-dependent (business-to-consumer) organization tends to present itself as possessing a set of human qualities, which is termed as the brand personality of the company. The perception is impressed upon the consumer through the content, be it in the form of advertisement, blogs or magazines, produced by the organization. A consistent brand will generate trust and retain customers over time as they develop an affinity towards regularity and common patterns. However, maintaining a consistent messaging tone for a brand has become more challenging with the virtual explosion in the amount of content which needs to be authored and pushed to the Internet to maintain an edge in the era of digital marketing. To understand the depth of the problem, we collect around 300K web page content from around 650 companies. We develop trait-specific classification models by considering the linguistic features of the content. The classifier automatically identifies the web articles which are not consistent with the mission and vision of a company and further helps us to discover the conditions under which the consistency cannot be maintained. To address the brand inconsistency issue, we then develop a sentence ranking system that outputs the top three sentences that need to be changed for making a web article more consistent with the company's brand personality.
CaM-Gen:Causally-aware Metric-guided Text Generation
Oct 24, 2020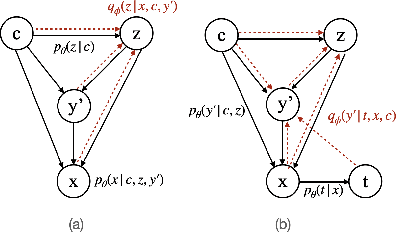
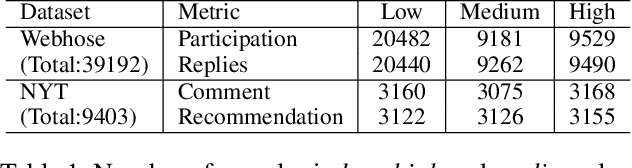
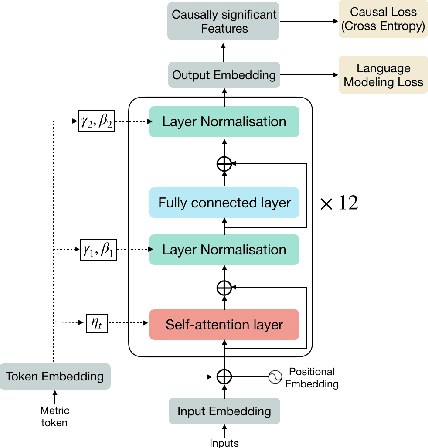
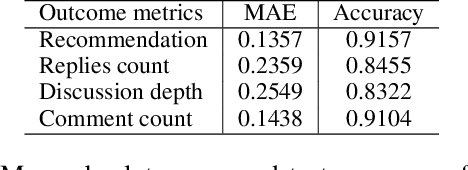
Content is created for a well-defined purpose, often described by a metric or a signal represented in the form of structured information. The relationship between the metrics or the goal of a target content and the content itself are non-trivial. While large scale language models show promising text generation capabilities, guiding and informing the generated text with external metrics is challenging. These metrics and the content tend to have inherent relationships and not all of them may directly impact the content. We introduce a CaM-Gen: Causally-aware Generative Networks guided by user-defined input metrics incorporating the causal relationships between the metric and the content features. We leverage causal inference techniques to identify the causally significant aspects of text that leads to the target metric and then explicitly guide the generative model towards these by a feedback mechanism. We propose this mechanism for variational autoencoder-based and transformer-based generative models. The proposed models beat baselines in terms of the target metric accuracy while maintaining the fluency and the language quality of the generated text. To the best of our knowledge, this is one of the early attempts at incorporating a metric-guide using causal inference towards controlled generation.
"To Target or Not to Target": Identification and Analysis of Abusive Text Using Ensemble of Classifiers
Jun 05, 2020



With rising concern around abusive and hateful behavior on social media platforms, we present an ensemble learning method to identify and analyze the linguistic properties of such content. Our stacked ensemble comprises of three machine learning models that capture different aspects of language and provide diverse and coherent insights about inappropriate language. The proposed approach provides comparable results to the existing state-of-the-art on the Twitter Abusive Behavior dataset (Founta et al. 2018) without using any user or network-related information; solely relying on textual properties. We believe that the presented insights and discussion of shortcomings of current approaches will highlight potential directions for future research.
Multi-label Categorization of Accounts of Sexism using a Neural Framework
Nov 18, 2019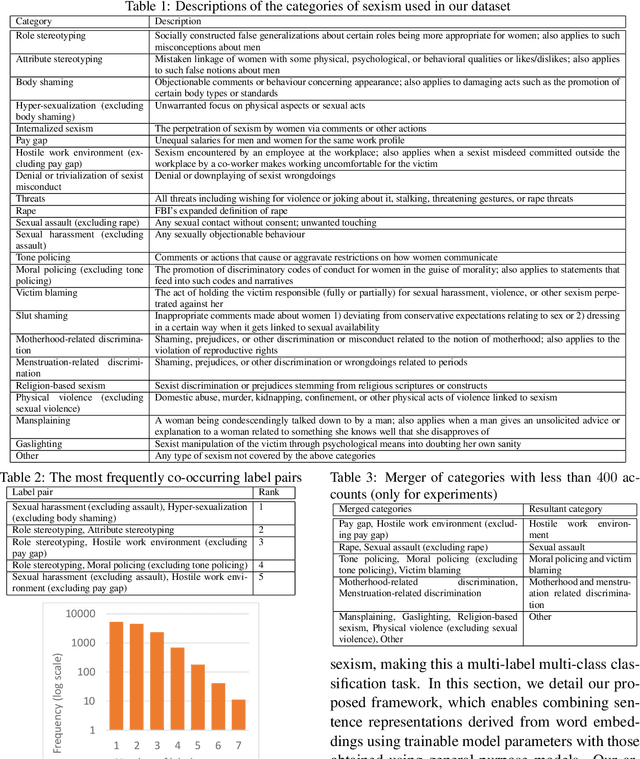
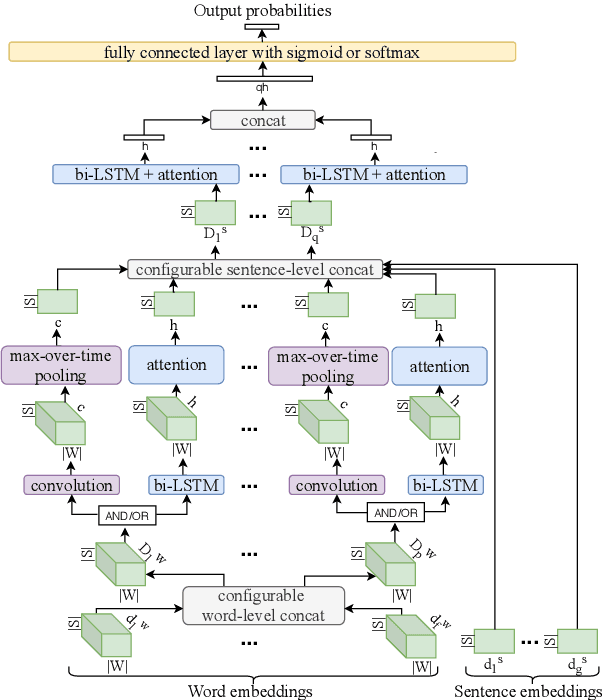


Sexism, an injustice that subjects women and girls to enormous suffering, manifests in blatant as well as subtle ways. In the wake of growing documentation of experiences of sexism on the web, the automatic categorization of accounts of sexism has the potential to assist social scientists and policy makers in studying and countering sexism better. The existing work on sexism classification, which is different from sexism detection, has certain limitations in terms of the categories of sexism used and/or whether they can co-occur. To the best of our knowledge, this is the first work on the multi-label classification of sexism of any kind(s), and we contribute the largest dataset for sexism categorization. We develop a neural solution for this multi-label classification that can combine sentence representations obtained using models such as BERT with distributional and linguistic word embeddings using a flexible, hierarchical architecture involving recurrent components and optional convolutional ones. Further, we leverage unlabeled accounts of sexism to infuse domain-specific elements into our framework. The best proposed method outperforms several deep learning as well as traditional machine learning baselines by an appreciable margin.
Affect Enriched Word Embeddings for News Information Retrieval
Sep 04, 2019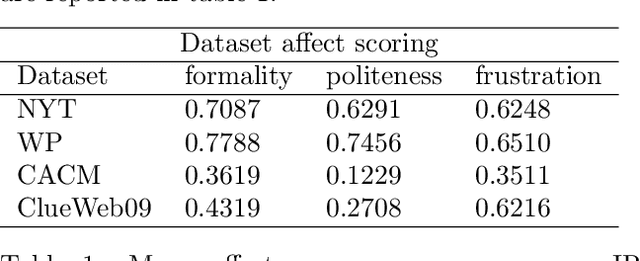
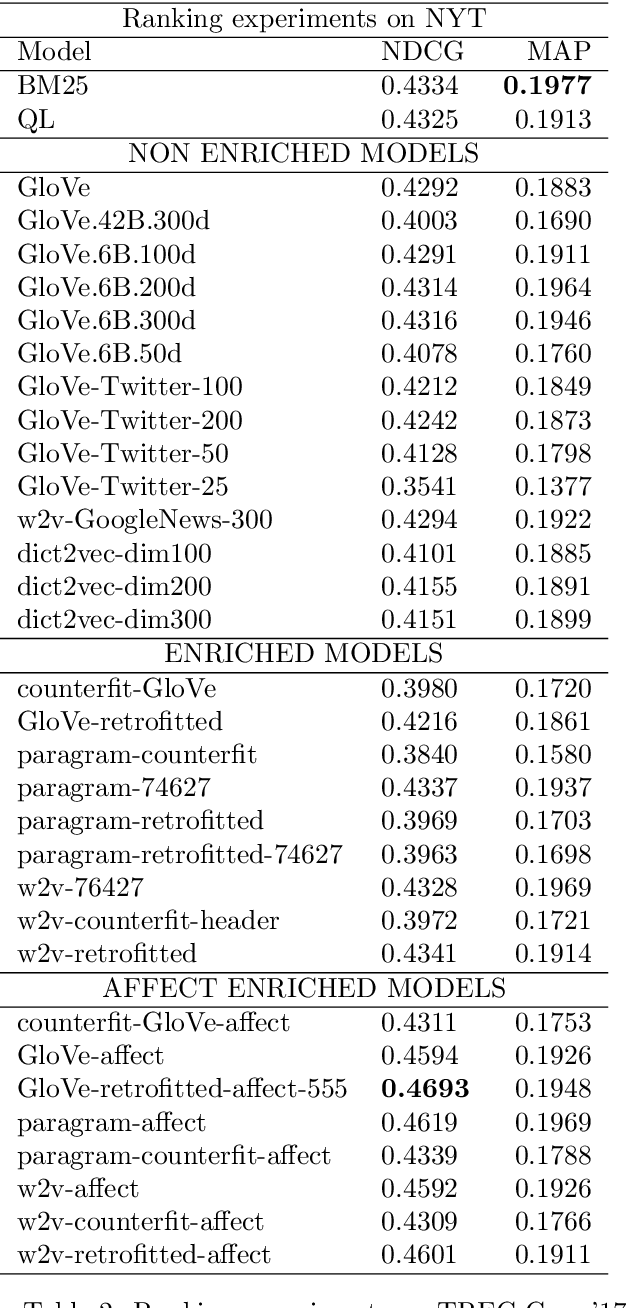
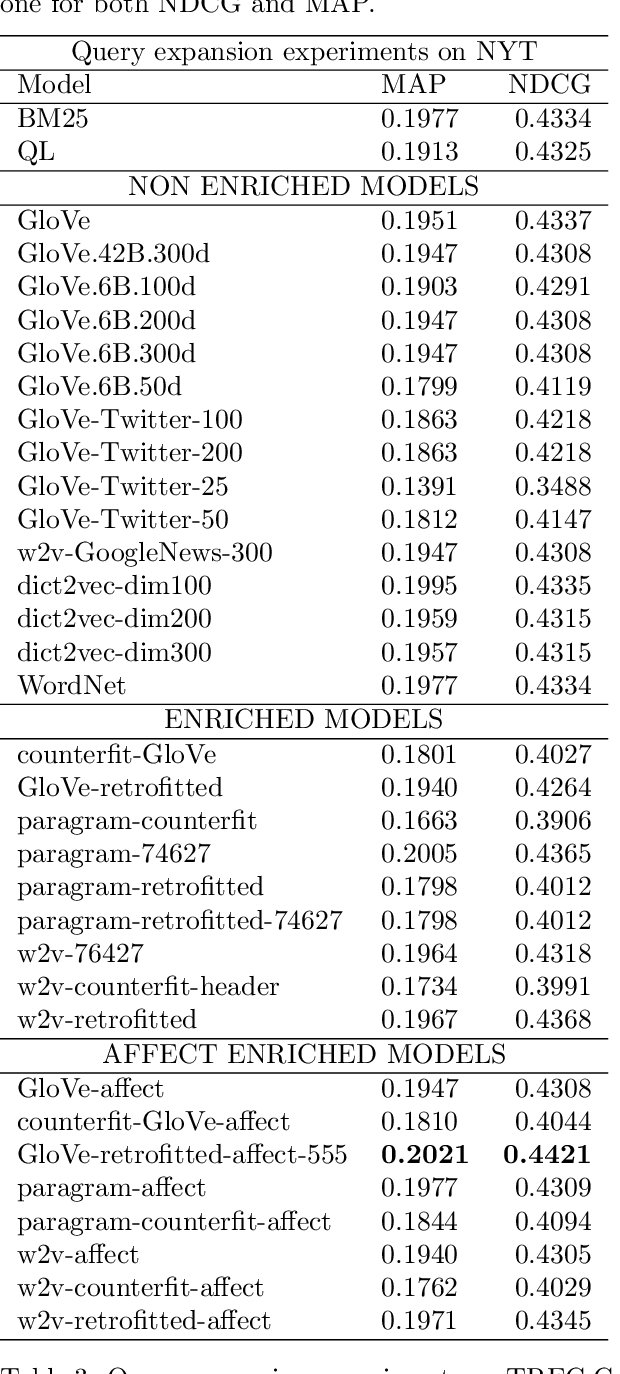
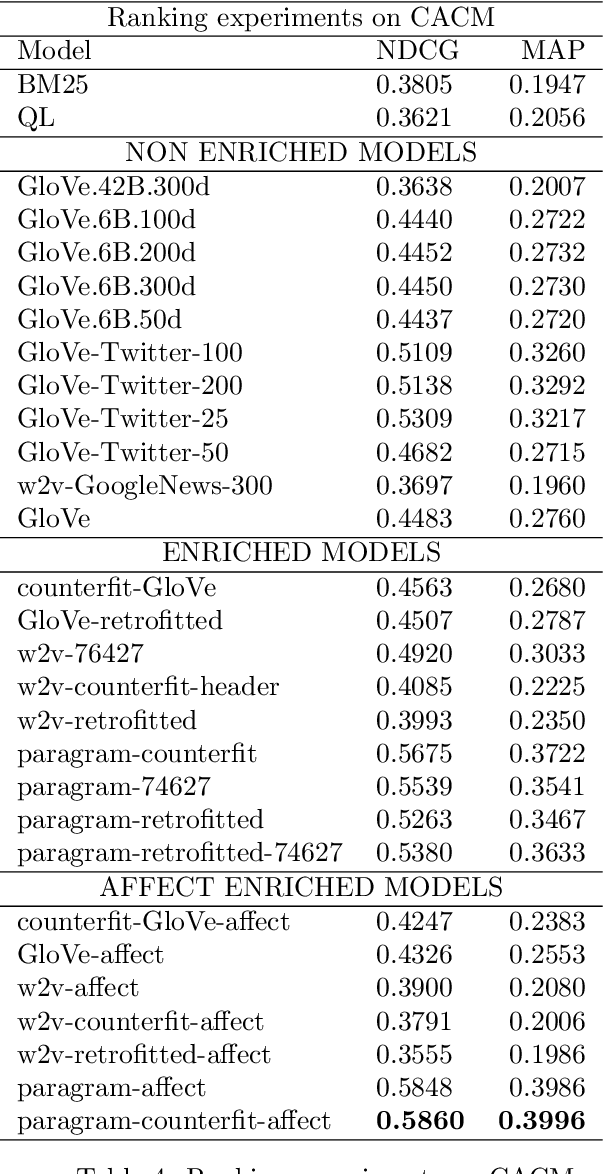
Distributed representations of words have shown to be useful to improve the effectiveness of IR systems in many sub-tasks like query expansion, retrieval and ranking. Algorithms like word2vec, GloVe and others are also key factors in many improvements in different NLP tasks. One common issue with such embedding models is that words like happy and sad appear in similar contexts and hence are wrongly clustered close in the embedding space. In this paper we leverage Aff2Vec, a set of word embeddings models which include affect information, in order to better capture the affect aspect in news text to achieve better results in information retrieval tasks, also such embeddings are less hit by the synonym/antonym issue. We evaluate their effectiveness on two IR related tasks (query expansion and ranking) over the New York Times dataset (TREC-core '17) comparing them against other word embeddings based models and classic ranking models.