 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylistic Evolution and LLM Neutrality in Singlish Language
Jan 10, 2026Singlish is a creole rooted in Singapore's multilingual environment and continues to evolve alongside social and technological change. This study investigates the evolution of Singlish over a decade of informal digital text messages. We propose a stylistic similarity framework that compares lexico-structural, pragmatic, psycholinguistic, and encoder-derived features across years to quantify temporal variation. Our analysis reveals notable diachronic changes in tone, expressivity and sentence construction over the years. Conversely, while some LLMs were able to generate superficially realistic Singlish messages, they do not produce temporally neutral outputs, and residual temporal signals remain detectable despite prompting and fine-tuning. Our findings highlight the dynamic evolution of Singlish, as well as the capabilities and limitations of current LLMs in modeling sociolectal and temporal variations in the colloquial language.
Measuring Fine-Grained Negotiation Tactics of Humans and LLMs in Diplomacy
Dec 20, 2025The study of negotiation styles dates back to Aristotle's ethos-pathos-logos rhetoric. Prior efforts primarily studied the success of negotiation agents. Here, we shift the focus towards the styles of negotiation strategies. Our focus is the strategic dialogue board game Diplomacy, which affords rich natural language negotiation and measures of game success. We used LLM-as-a-judge to annotate a large human-human set of Diplomacy games for fine-grained negotiation tactics from a sociologically-grounded taxonomy. Using a combination of the It Takes Two and WebDiplomacy datasets, we demonstrate the reliability of our LLM-as-a-Judge framework and show strong correlations between negotiation features and success in the Diplomacy setting. Lastly, we investigate the differences between LLM and human negotiation strategies and show that fine-tuning can steer LLM agents toward more human-like negotiation behaviors.
Humanizing Machines: Rethinking LLM Anthropomorphism Through a Multi-Level Framework of Design
Aug 25, 2025Large Language Models (LLMs) increasingly exhibit \textbf{anthropomorphism} characteristics -- human-like qualities portrayed across their outlook, language, behavior, and reasoning functions. Such characteristics enable more intuitive and engaging human-AI interactions. However, current research on anthropomorphism remains predominantly risk-focused, emphasizing over-trust and user deception while offering limited design guidance. We argue that anthropomorphism should instead be treated as a \emph{concept of design} that can be intentionally tuned to support user goals. Drawing from multiple disciplines, we propose that the anthropomorphism of an LLM-based artifact should reflect the interaction between artifact designers and interpreters. This interaction is facilitated by cues embedded in the artifact by the designers and the (cognitive) responses of the interpreters to the cues. Cues are categorized into four dimensions: \textit{perceptive, linguistic, behavioral}, and \textit{cognitive}. By analyzing the manifestation and effectiveness of each cue, we provide a unified taxonomy with actionable levers for practitioners. Consequently, we advocate for function-oriented evaluations of anthropomorphic design.
Improving User Behavior Prediction: Leveraging Annotator Metadata in Supervised Machine Learning Models
Mar 26, 2025Supervised machine-learning models often underperform in predicting user behaviors from conversational text, hindered by poor crowdsourced label quality and low NLP task accuracy. We introduce the Metadata-Sensitive Weighted-Encoding Ensemble Model (MSWEEM), which integrates annotator meta-features like fatigue and speeding. First, our results show MSWEEM outperforms standard ensembles by 14\% on held-out data and 12\% on an alternative dataset. Second, we find that incorporating signals of annotator behavior, such as speed and fatigue, significantly boosts model performance. Third, we find that annotators with higher qualifications, such as Master's, deliver more consistent and faster annotations. Given the increasing uncertainty over annotation quality, our experiments show that understanding annotator patterns is crucial for enhancing model accuracy in user behavior prediction.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
What is a Social Media Bot? A Global Comparison of Bot and Human Characteristics
Jan 01, 2025Chatter on social media is 20% bots and 80% humans. Chatter by bots and humans is consistently different: bots tend to use linguistic cues that can be easily automated while humans use cues that require dialogue understanding. Bots use words that match the identities they choose to present, while humans may send messages that are not related to the identities they present. Bots and humans differ in their communication structure: sampled bots have a star interaction structure, while sampled humans have a hierarchical structure. These conclusions are based on a large-scale analysis of social media tweets across ~200mil users across 7 events. Social media bots took the world by storm when social-cybersecurity researchers realized that social media users not only consisted of humans but also of artificial agents called bots. These bots wreck havoc online by spreading disinformation and manipulating narratives. Most research on bots are based on special-purposed definitions, mostly predicated on the event studied. This article first begins by asking, "What is a bot?", and we study the underlying principles of how bots are different from humans. We develop a first-principle definition of a social media bot. With this definition as a premise, we systematically compare characteristics between bots and humans across global events, and reflect on how the software-programmed bot is an Artificial Intelligent algorithm, and its potential for evolution as technology advances. Based on our results, we provide recommendations for the use and regulation of bots. Finally, we discuss open challenges and future directions: Detect, to systematically identify these automated and potentially evolving bots; Differentiate, to evaluate the goodness of the bot in terms of their content postings and relationship interactions; Disrupt, to moderate the impact of malicious bots.
What talking you?: Translating Code-Mixed Messaging Texts to English
Nov 08, 2024



Translation of code-mixed texts to formal English allow a wider audience to understand these code-mixed languages, and facilitate downstream analysis applications such as sentiment analysis. In this work, we look at translating Singlish, which is colloquial Singaporean English, to formal standard English. Singlish is formed through the code-mixing of multiple Asian languages and dialects. We analysed the presence of other Asian languages and variants which can facilitate translation. Our dataset is short message texts, written as informal communication between Singlish speakers. We use a multi-step prompting scheme on five Large Language Models (LLMs) for language detection and translation. Our analysis show that LLMs do not perform well in this task, and we describe the challenges involved in translation of code-mixed languages. We also release our dataset in this link https://github.com/luoqichan/singlish.
$\textit{Who Speaks Matters}$: Analysing the Influence of the Speaker's Ethnicity on Hate Classification
Oct 27, 2024Large Language Models (LLMs) offer a lucrative promise for scalable content moderation, including hate speech detection. However, they are also known to be brittle and biased against marginalised communities and dialects. This requires their applications to high-stakes tasks like hate speech detection to be critically scrutinized. In this work, we investigate the robustness of hate speech classification using LLMs, particularly when explicit and implicit markers of the speaker's ethnicity are injected into the input. For the explicit markers, we inject a phrase that mentions the speaker's identity. For the implicit markers, we inject dialectal features. By analysing how frequently model outputs flip in the presence of these markers, we reveal varying degrees of brittleness across 4 popular LLMs and 5 ethnicities. We find that the presence of implicit dialect markers in inputs causes model outputs to flip more than the presence of explicit markers. Further, the percentage of flips varies across ethnicities. Finally, we find that larger models are more robust. Our findings indicate the need for exercising caution in deploying LLMs for high-stakes tasks like hate speech detection.
Limpeh ga li gong: Challenges in Singlish Annotations
Oct 21, 2024
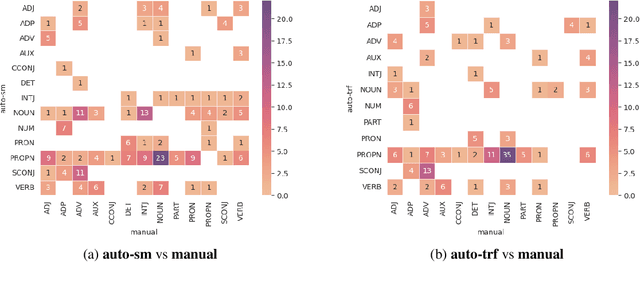


Singlish, or Colloquial Singapore English, is a language formed from oral and social communication within multicultural Singapore. In this work, we work on a fundamental Natural Language Processing (NLP) task: Parts-Of-Speech (POS) tagging of Singlish sentences. For our analysis, we build a parallel Singlish dataset containing direct English translations and POS tags, with translation and POS annotation done by native Singlish speakers. Our experiments show that automatic transition- and transformer- based taggers perform with only $\sim 80\%$ accuracy when evaluated against human-annotated POS labels, suggesting that there is indeed room for improvement on computation analysis of the language. We provide an exposition of challenges in Singlish annotation: its inconsistencies in form and semantics, the highly context-dependent particles of the language, its structural unique expressions, and the variation of the language on different mediums. Our task definition, resultant labels and results reflects the challenges in analysing colloquial languages formulated from a variety of dialects, and paves the way for future studies beyond POS tagging.
Disentangling Singlish Discourse Particles with Task-Driven Representation
Sep 30, 2024Singlish, or formally Colloquial Singapore English, is an English-based creole language originating from the SouthEast Asian country Singapore. The language contains influences from Sinitic languages such as Chinese dialects, Malay, Tamil and so forth. A fundamental task to understanding Singlish is to first understand the pragmatic functions of its discourse particles, upon which Singlish relies heavily to convey meaning. This work offers a preliminary effort to disentangle the Singlish discourse particles (lah, meh and hor) with task-driven representation learning. After disentanglement, we cluster these discourse particles to differentiate their pragmatic functions, and perform Singlish-to-English machine translation. Our work provides a computational method to understanding Singlish discourse particles, and opens avenues towards a deeper comprehension of the language and its usage.