 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVERSE: Deciphering Internet Views on the U.S. Military Through Video Comment Stance Analysis, A Novel Benchmark Dataset for Stance Classification
Mar 05, 2024Stance detection of social media text is a key component of downstream tasks involving the identification of groups of users with opposing opinions on contested topics such as vaccination and within arguments. In particular, stance provides an indication of an opinion towards an entity. This paper introduces DIVERSE, a dataset of over 173,000 YouTube video comments annotated for their stance towards videos of the U.S. military. The stance is annotated through a human-guided, machine-assisted labeling methodology that makes use of weak signals of tone within the sentence as supporting indicators, as opposed to using manual annotations by humans. These weak signals consist of the presence of hate speech and sarcasm, the presence of specific keywords, the sentiment of the text, and the stance inference from two Large Language Models. The weak signals are then consolidated using a data programming model before each comment is annotated with a final stance label. On average, the videos have 200 comments each, and the stance of the comments skews slightly towards the "against" characterization for both the U.S. Army and the videos posted on the channel.
Developing a Natural Language Understanding Model to Characterize Cable News Bias
Oct 17, 2023



Media bias has been extensively studied by both social and computational sciences. However, current work still has a large reliance on human input and subjective assessment to label biases. This is especially true for cable news research. To address these issues, we develop an unsupervised machine learning method to characterize the bias of cable news programs without any human input. This method relies on the analysis of what topics are mentioned through Named Entity Recognition and how those topics are discussed through Stance Analysis in order to cluster programs with similar biases together. Applying our method to 2020 cable news transcripts, we find that program clusters are consistent over time and roughly correspond to the cable news network of the program. This method reveals the potential for future tools to objectively assess media bias and characterize unfamiliar media environments.
Use of Large Language Models for Stance Classification
Sep 24, 2023Stance detection, the task of predicting an author's viewpoint towards a subject of interest, has long been a focal point of research. Current stance detection methods predominantly rely on manual annotation of sentences, followed by training a supervised machine learning model. This manual annotation process, however, imposes limitations on the model's ability to fully comprehend the stances in the sentence and hampers its potential to generalize across different contexts. In this study, we investigate the use of Large Language Models (LLMs) for the task of stance classification, with an absolute minimum use of human labels. We scrutinize four distinct types of prompting schemes combined with LLMs, comparing their accuracies with manual stance determination. Our study reveals that while LLMs can match or sometimes even exceed the benchmark results in each dataset, their overall accuracy is not definitively better than what can be produced by supervised models. This suggests potential areas for improvement in the stance classification for LLMs. The application of LLMs, however, opens up promising avenues for unsupervised stance detection, thereby curtailing the need for manual collection and annotation of stances. This not only streamlines the process but also paves the way for expanding stance detection capabilities across languages. Through this paper, we shed light on the stance classification abilities of LLMs, thereby contributing valuable insights that can guide future advancements in this domain.
Measuring Classification Decision Certainty and Doubt
Mar 28, 2023Quantitative characterizations and estimations of uncertainty are of fundamental importance in optimization and decision-making processes. Herein, we propose intuitive scores, which we call certainty and doubt, that can be used in both a Bayesian and frequentist framework to assess and compare the quality and uncertainty of predictions in (multi-)classification decision machine learning problems.
Multi-modal Networks Reveal Patterns of Operational Similarity of Terrorist Organizations
Dec 15, 2021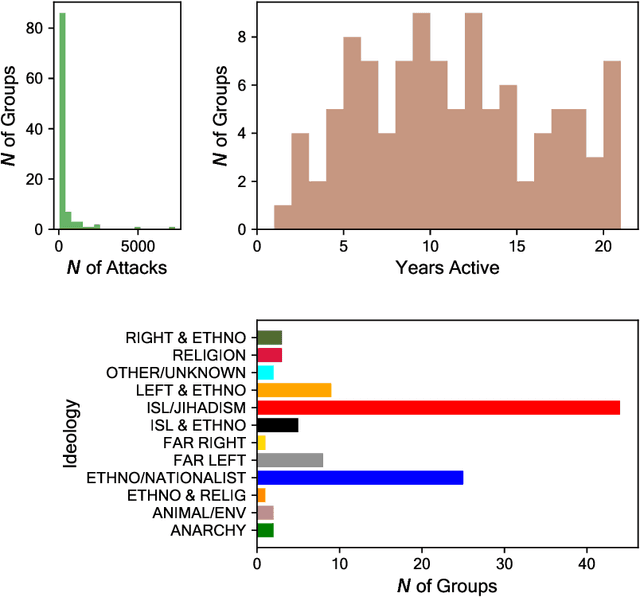
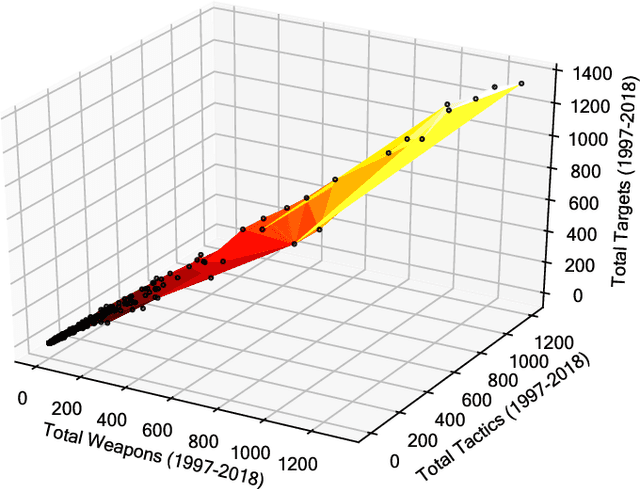
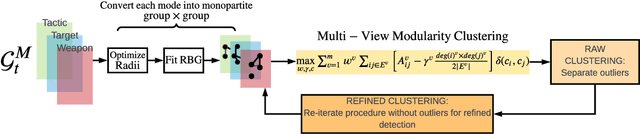
Capturing dynamics of operational similarity among terrorist groups is critical to provide actionable insights for counter-terrorism and intelligence monitoring. Yet, in spite of its theoretical and practical relevance, research addressing this problem is currently lacking. We tackle this problem proposing a novel computational framework for detecting clusters of terrorist groups sharing similar behaviors, focusing on groups' yearly repertoire of deployed tactics, attacked targets, and utilized weapons. Specifically considering those organizations that have plotted at least 50 attacks from 1997 to 2018, accounting for a total of 105 groups responsible for more than 42,000 events worldwide, we offer three sets of results. First, we show that over the years global terrorism has been characterized by increasing operational cohesiveness. Second, we highlight that year-to-year stability in co-clustering among groups has been particularly high from 2009 to 2018, indicating temporal consistency of similarity patterns in the last decade. Third, we demonstrate that operational similarity between two organizations is driven by three factors: (a) their overall activity; (b) the difference in the diversity of their operational repertoires; (c) the difference in a combined measure of diversity and activity. Groups' operational preferences, geographical homophily and ideological affinity have no consistent role in determining operational similarity.
* 42 pages, 19 figures