 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming
Jan 16, 2026Large Language Models (LLMs) increasingly succeed on competitive programming problems, yet existing evaluations conflate algorithmic reasoning with code-level implementation. We argue that competitive programming is fundamentally a problem-solving task and propose centering natural-language editorials in both solution generation and evaluation. Generating an editorial prior to code improves solve rates for some LLMs, with substantially larger gains when using expertly written gold editorials. However, even with gold editorials, models continue to struggle with implementation, while the gap between generated and gold editorials reveals a persistent problem-solving bottleneck in specifying correct and complete algorithms. Beyond pass/fail metrics, we diagnose reasoning errors by comparing model-generated editorials to gold standards using expert annotations and validate an LLM-as-a-judge protocol for scalable evaluation. We introduce a dataset of 83 ICPC-style problems with gold editorials and full test suites, and evaluate 19 LLMs, arguing that future benchmarks should explicitly separate problem solving from implementation.
Can Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
TextGames: Learning to Self-Play Text-Based Puzzle Games via Language Model Reasoning
Feb 25, 2025Reasoning is a fundamental capability of large language models (LLMs), enabling them to comprehend, analyze, and solve complex problems. In this paper, we introduce TextGames, an innovative benchmark specifically crafted to assess LLMs through demanding text-based games that require advanced skills in pattern recognition, spatial awareness, arithmetic, and logical reasoning. Our analysis probes LLMs' performance in both single-turn and multi-turn reasoning, and their abilities in leveraging feedback to correct subsequent answers through self-reflection. Our findings reveal that, although LLMs exhibit proficiency in addressing most easy and medium-level problems, they face significant challenges with more difficult tasks. In contrast, humans are capable of solving all tasks when given sufficient time. Moreover, we observe that LLMs show improved performance in multi-turn predictions through self-reflection, yet they still struggle with sequencing, counting, and following complex rules consistently. Additionally, models optimized for reasoning outperform pre-trained LLMs that prioritize instruction following, highlighting the crucial role of reasoning skills in addressing highly complex problems.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Beyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Oct 04, 2024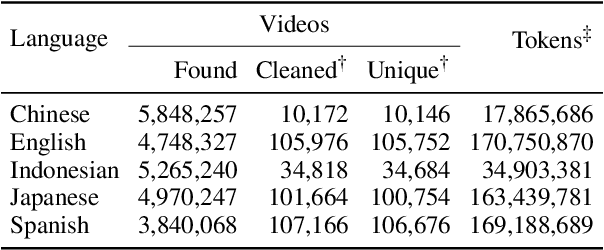
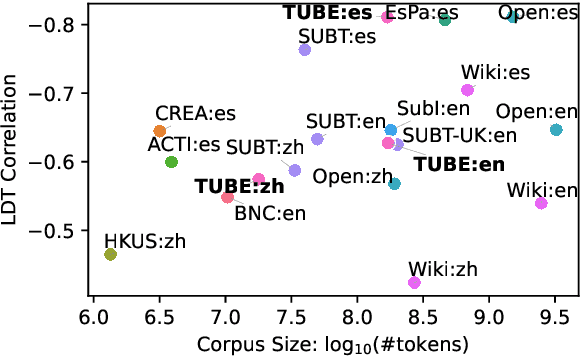
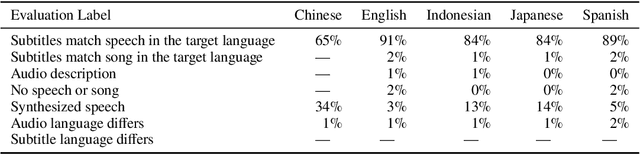
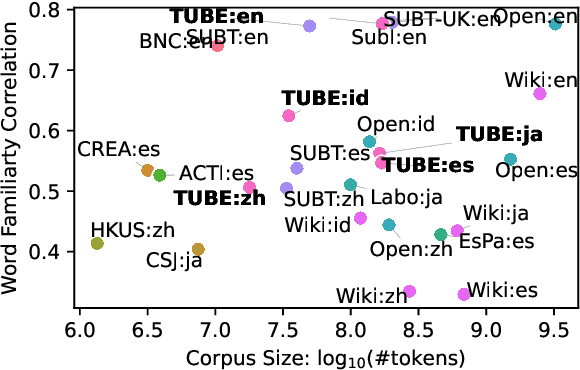
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024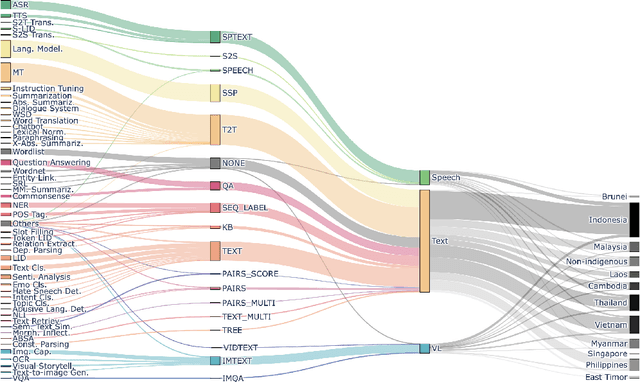
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.