 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
NusaCrowd: A Call for Open and Reproducible NLP Research in Indonesian Languages
Aug 01, 2022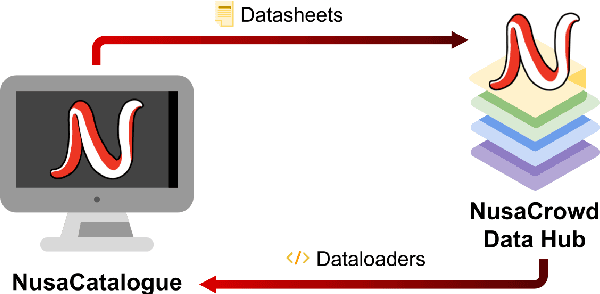
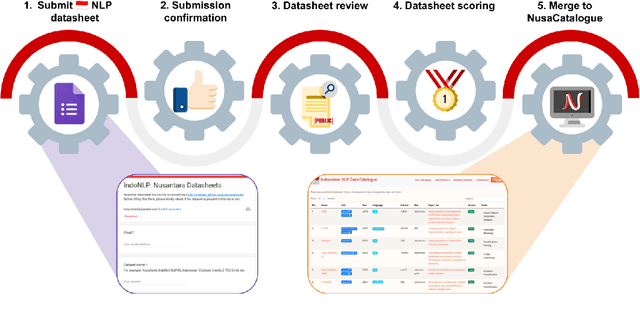
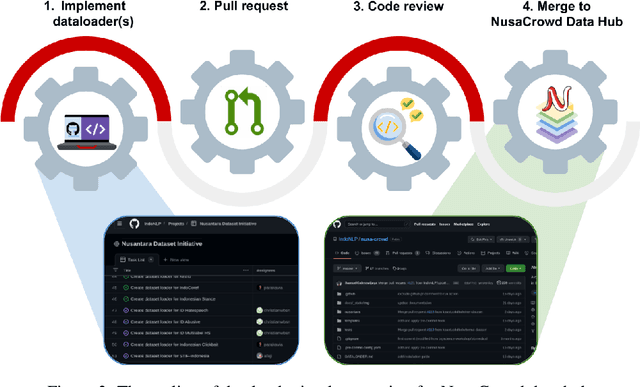
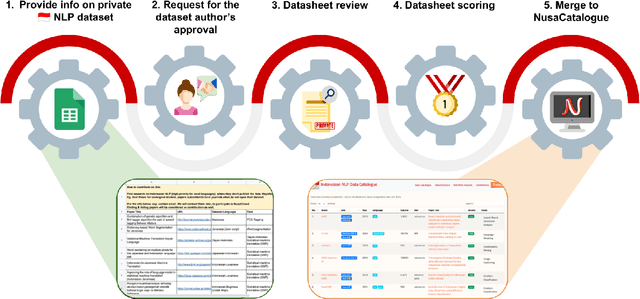
At the center of the underlying issues that halt Indonesian natural language processing (NLP) research advancement, we find data scarcity. Resources in Indonesian languages, especially the local ones, are extremely scarce and underrepresented. Many Indonesian researchers do not publish their dataset. Furthermore, the few public datasets that we have are scattered across different platforms, thus makes performing reproducible and data-centric research in Indonesian NLP even more arduous. Rising to this challenge, we initiate the first Indonesian NLP crowdsourcing effort, NusaCrowd. NusaCrowd strives to provide the largest datasheets aggregation with standardized data loading for NLP tasks in all Indonesian languages. By enabling open and centralized access to Indonesian NLP resources, we hope NusaCrowd can tackle the data scarcity problem hindering NLP progress in Indonesia and bring NLP practitioners to move towards collaboration.
IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Apr 16, 2021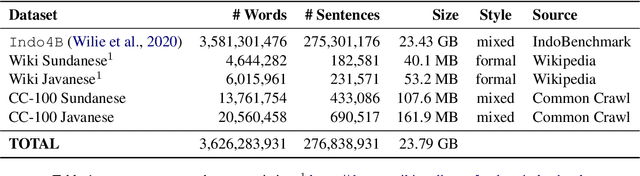
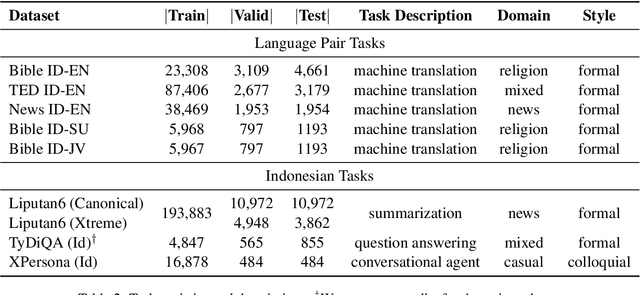
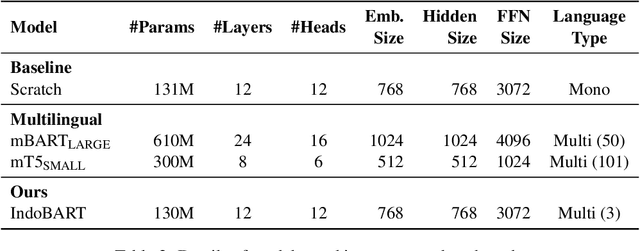
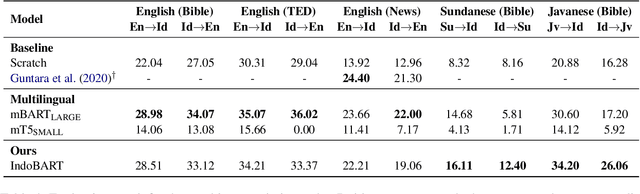
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding
Oct 08, 2020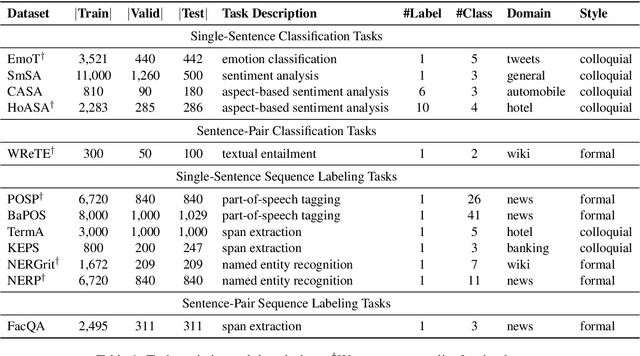
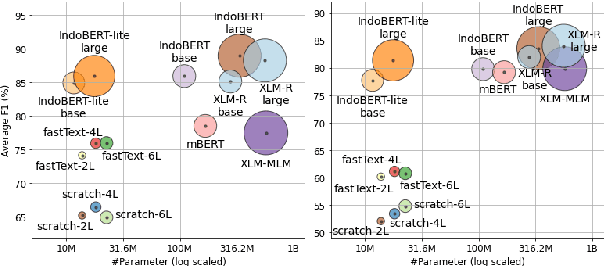
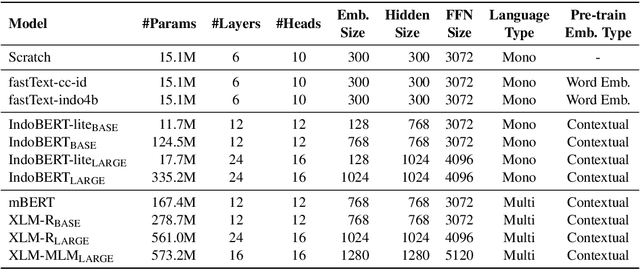
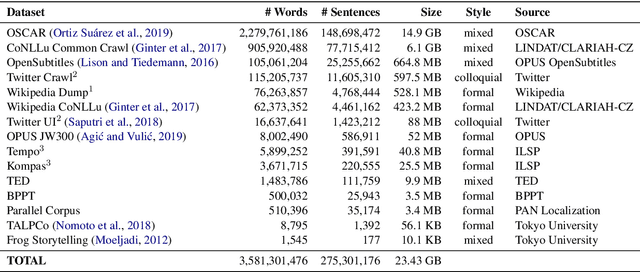
Although Indonesian is known to be the fourth most frequently used language over the internet, the research progress on this language in the natural language processing (NLP) is slow-moving due to a lack of available resources. In response, we introduce the first-ever vast resource for the training, evaluating, and benchmarking on Indonesian natural language understanding (IndoNLU) tasks. IndoNLU includes twelve tasks, ranging from single sentence classification to pair-sentences sequence labeling with different levels of complexity. The datasets for the tasks lie in different domains and styles to ensure task diversity. We also provide a set of Indonesian pre-trained models (IndoBERT) trained from a large and clean Indonesian dataset Indo4B collected from publicly available sources such as social media texts, blogs, news, and websites. We release baseline models for all twelve tasks, as well as the framework for benchmark evaluation, and thus it enables everyone to benchmark their system performances.