 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNusaCrowd: A Call for Open and Reproducible NLP Research in Indonesian Languages
Paper and Code
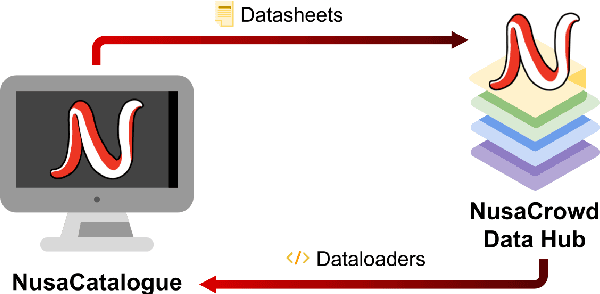
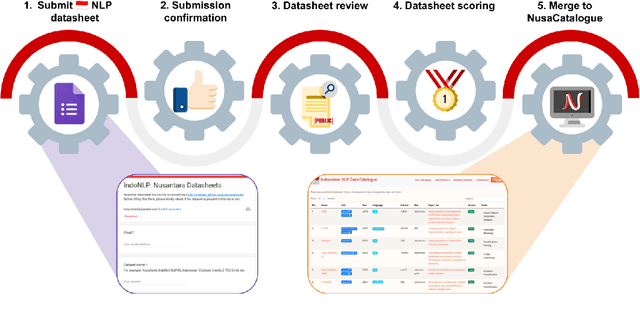
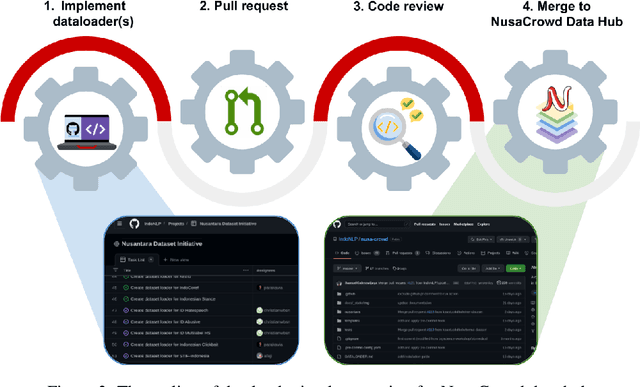
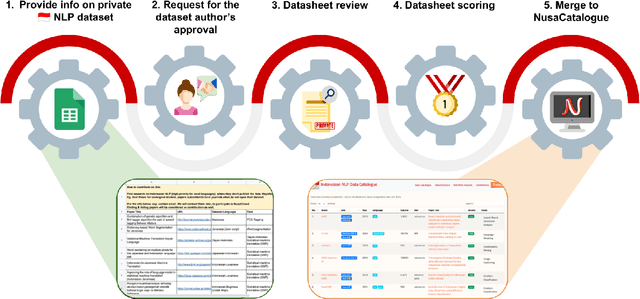
At the center of the underlying issues that halt Indonesian natural language processing (NLP) research advancement, we find data scarcity. Resources in Indonesian languages, especially the local ones, are extremely scarce and underrepresented. Many Indonesian researchers do not publish their dataset. Furthermore, the few public datasets that we have are scattered across different platforms, thus makes performing reproducible and data-centric research in Indonesian NLP even more arduous. Rising to this challenge, we initiate the first Indonesian NLP crowdsourcing effort, NusaCrowd. NusaCrowd strives to provide the largest datasheets aggregation with standardized data loading for NLP tasks in all Indonesian languages. By enabling open and centralized access to Indonesian NLP resources, we hope NusaCrowd can tackle the data scarcity problem hindering NLP progress in Indonesia and bring NLP practitioners to move towards collaboration.