 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages
Sep 20, 2023



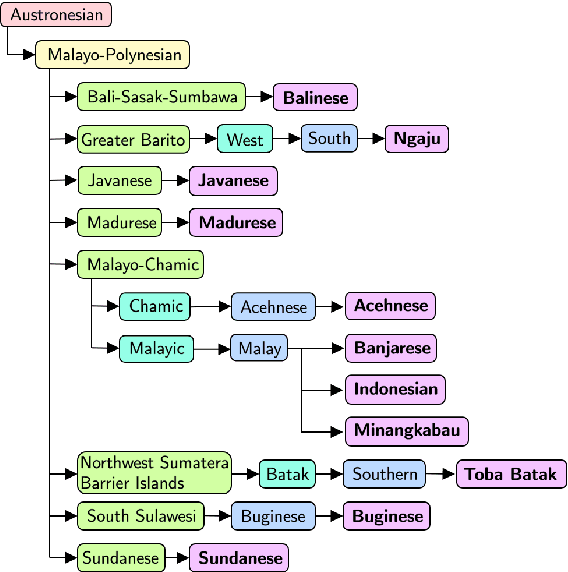
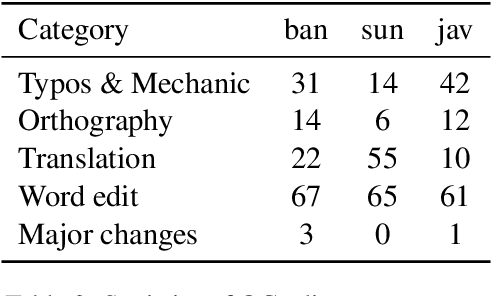
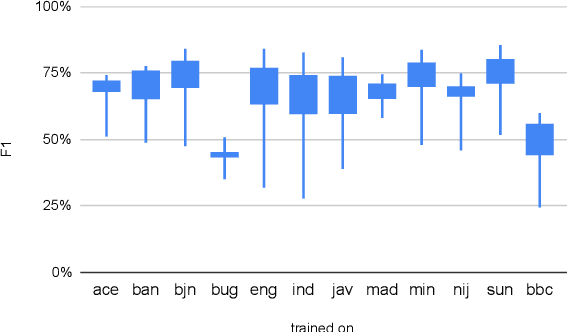
Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the \datasetname{} benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages. We release the NusaWrites dataset at https://github.com/IndoNLP/nusa-writes.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
NusaCrowd: A Call for Open and Reproducible NLP Research in Indonesian Languages
Aug 01, 2022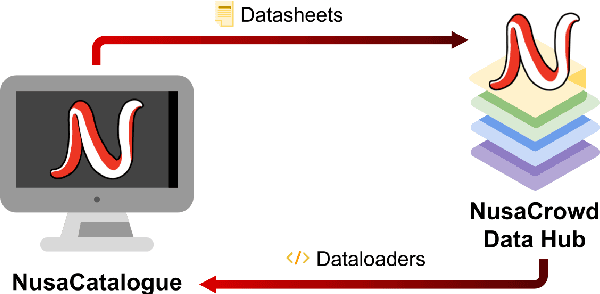
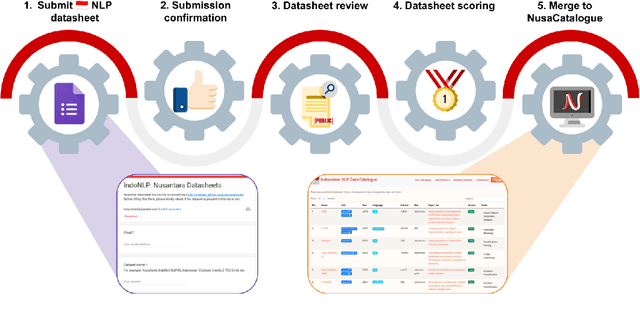
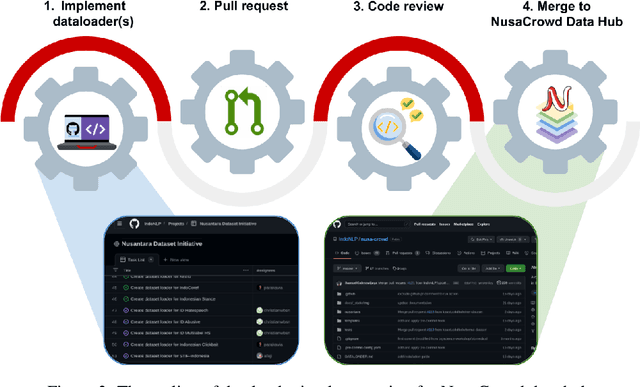
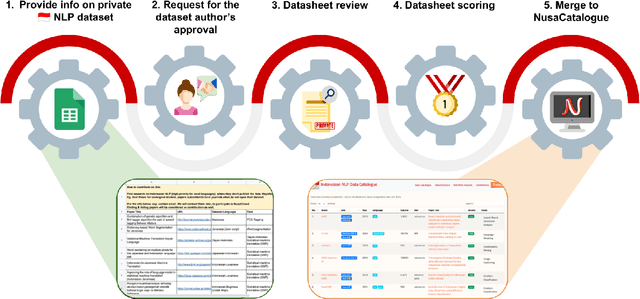
At the center of the underlying issues that halt Indonesian natural language processing (NLP) research advancement, we find data scarcity. Resources in Indonesian languages, especially the local ones, are extremely scarce and underrepresented. Many Indonesian researchers do not publish their dataset. Furthermore, the few public datasets that we have are scattered across different platforms, thus makes performing reproducible and data-centric research in Indonesian NLP even more arduous. Rising to this challenge, we initiate the first Indonesian NLP crowdsourcing effort, NusaCrowd. NusaCrowd strives to provide the largest datasheets aggregation with standardized data loading for NLP tasks in all Indonesian languages. By enabling open and centralized access to Indonesian NLP resources, we hope NusaCrowd can tackle the data scarcity problem hindering NLP progress in Indonesia and bring NLP practitioners to move towards collaboration.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022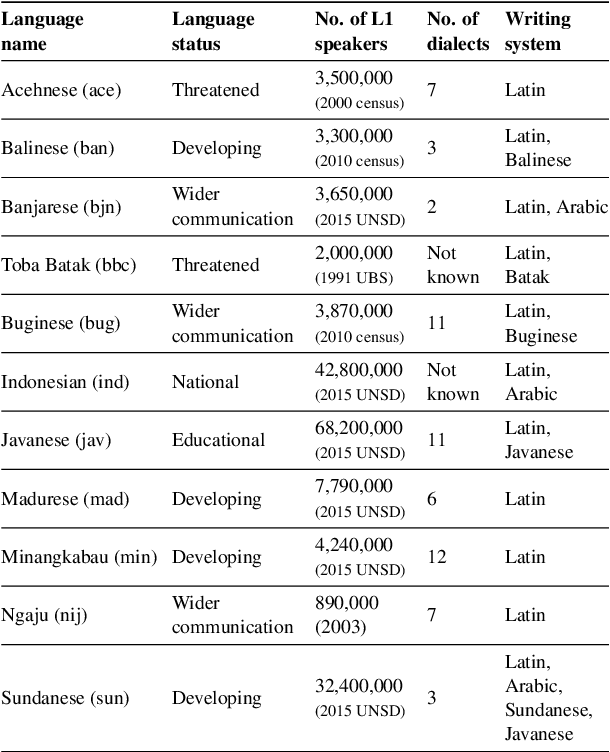
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Mar 24, 2022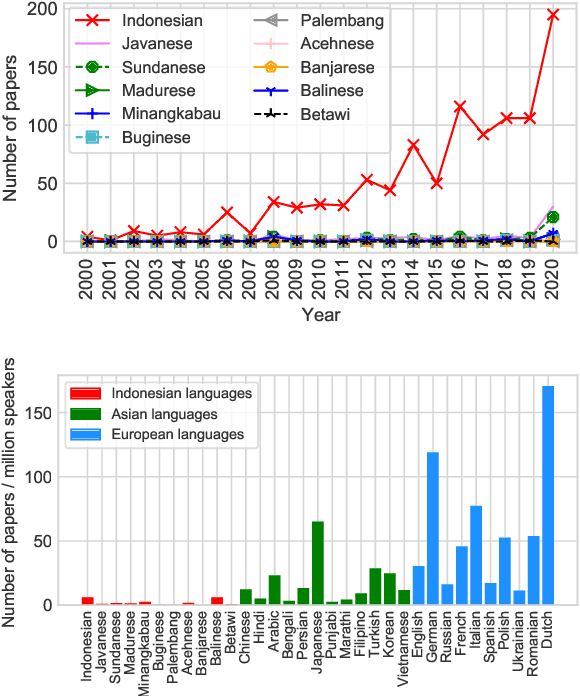
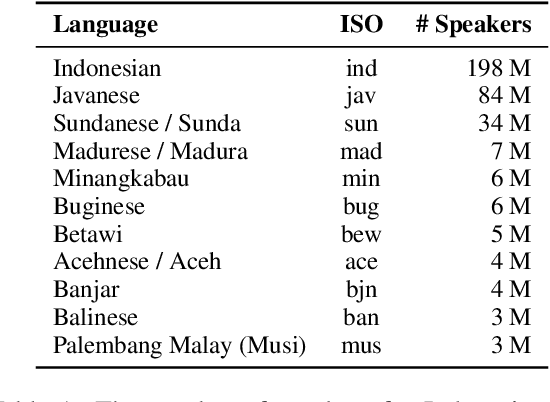
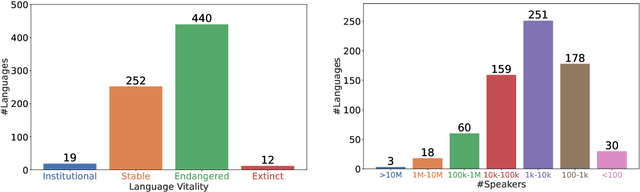

NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.