 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Hack for Transformers against Heavy Long-Text Classification on a Time- and Memory-Limited GPU Service
Mar 19, 2024

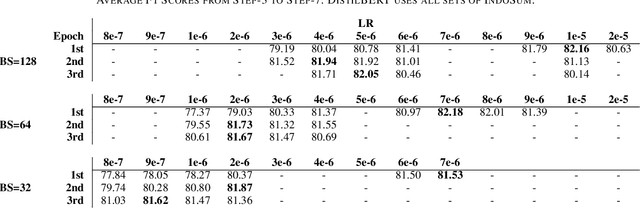
Many NLP researchers rely on free computational services, such as Google Colab, to fine-tune their Transformer models, causing a limitation for hyperparameter optimization (HPO) in long-text classification due to the method having quadratic complexity and needing a bigger resource. In Indonesian, only a few works were found on long-text classification using Transformers. Most only use a small amount of data and do not report any HPO. In this study, using 18k news articles, we investigate which pretrained models are recommended to use based on the output length of the tokenizer. We then compare some hacks to shorten and enrich the sequences, which are the removals of stopwords, punctuation, low-frequency words, and recurring words. To get a fair comparison, we propose and run an efficient and dynamic HPO procedure that can be done gradually on a limited resource and does not require a long-running optimization library. Using the best hack found, we then compare 512, 256, and 128 tokens length. We find that removing stopwords while keeping punctuation and low-frequency words is the best hack. Some of our setups manage to outperform taking 512 first tokens using a smaller 128 or 256 first tokens which manage to represent the same information while requiring less computational resources. The findings could help developers to efficiently pursue optimal performance of the models using limited resources.
Investigating Text Shortening Strategy in BERT: Truncation vs Summarization
Mar 19, 2024



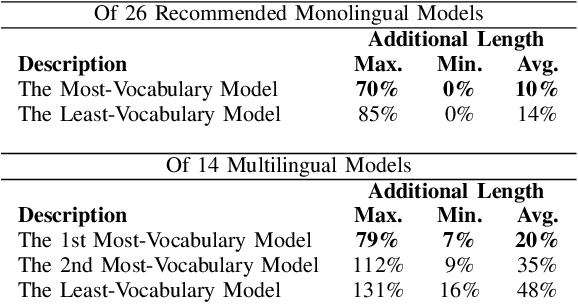
The parallelism of Transformer-based models comes at the cost of their input max-length. Some studies proposed methods to overcome this limitation, but none of them reported the effectiveness of summarization as an alternative. In this study, we investigate the performance of document truncation and summarization in text classification tasks. Each of the two was investigated with several variations. This study also investigated how close their performances are to the performance of full-text. We used a dataset of summarization tasks based on Indonesian news articles (IndoSum) to do classification tests. This study shows how the summaries outperform the majority of truncation method variations and lose to only one. The best strategy obtained in this study is taking the head of the document. The second is extractive summarization. This study explains what happened to the result, leading to further research in order to exploit the potential of document summarization as a shortening alternative. The code and data used in this work are publicly available in https://github.com/mirzaalimm/TruncationVsSummarization.
COPAL-ID: Indonesian Language Reasoning with Local Culture and Nuances
Nov 13, 2023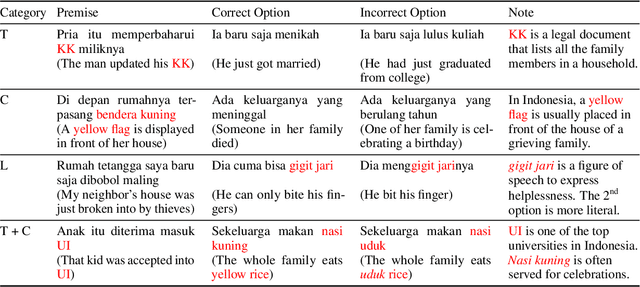

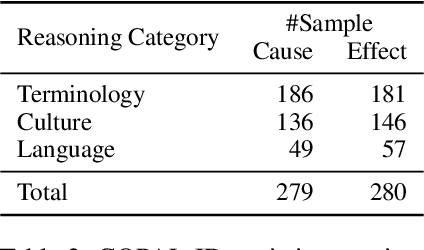
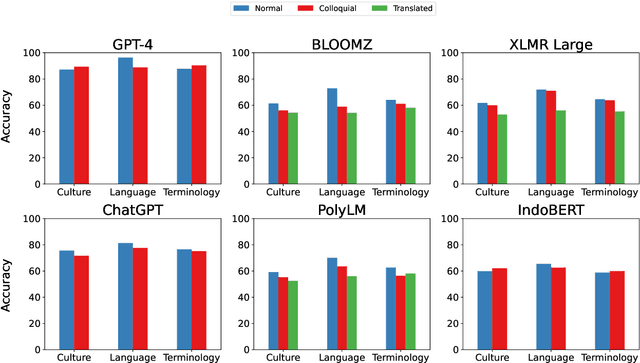
We present publicly available COPAL-ID, a novel Indonesian language common sense reasoning dataset. Unlike the previous Indonesian COPA dataset (XCOPA-ID), COPAL-ID incorporates Indonesian local and cultural nuances, and therefore, provides a more natural portrayal of day-to-day causal reasoning within the Indonesian cultural sphere. Professionally written by natives from scratch, COPAL-ID is more fluent and free from awkward phrases, unlike the translated XCOPA-ID. In addition, we present COPAL-ID in both standard Indonesian and in Jakartan Indonesian--a dialect commonly used in daily conversation. COPAL-ID poses a greater challenge for existing open-sourced and closed state-of-the-art multilingual language models, yet is trivially easy for humans. Our findings suggest that even the current best open-source, multilingual model struggles to perform well, achieving 65.47% accuracy on COPAL-ID, significantly lower than on the culturally-devoid XCOPA-ID (79.40%). Despite GPT-4's impressive score, it suffers the same performance degradation compared to its XCOPA-ID score, and it still falls short of human performance. This shows that these language models are still way behind in comprehending the local nuances of Indonesian.
On "Scientific Debt" in NLP: A Case for More Rigour in Language Model Pre-Training Research
Jun 05, 2023This evidence-based position paper critiques current research practices within the language model pre-training literature. Despite rapid recent progress afforded by increasingly better pre-trained language models (PLMs), current PLM research practices often conflate different possible sources of model improvement, without conducting proper ablation studies and principled comparisons between different models under comparable conditions. These practices (i) leave us ill-equipped to understand which pre-training approaches should be used under what circumstances; (ii) impede reproducibility and credit assignment; and (iii) render it difficult to understand: "How exactly does each factor contribute to the progress that we have today?" We provide a case in point by revisiting the success of BERT over its baselines, ELMo and GPT-1, and demonstrate how -- under comparable conditions where the baselines are tuned to a similar extent -- these baselines (and even-simpler variants thereof) can, in fact, achieve competitive or better performance than BERT. These findings demonstrate how disentangling different factors of model improvements can lead to valuable new insights. We conclude with recommendations for how to encourage and incentivize this line of work, and accelerate progress towards a better and more systematic understanding of what factors drive the progress of our foundation models today.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022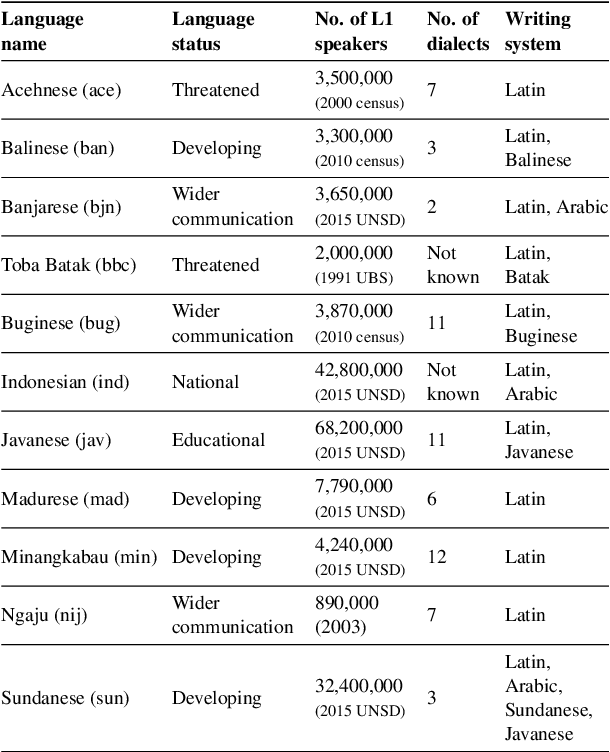
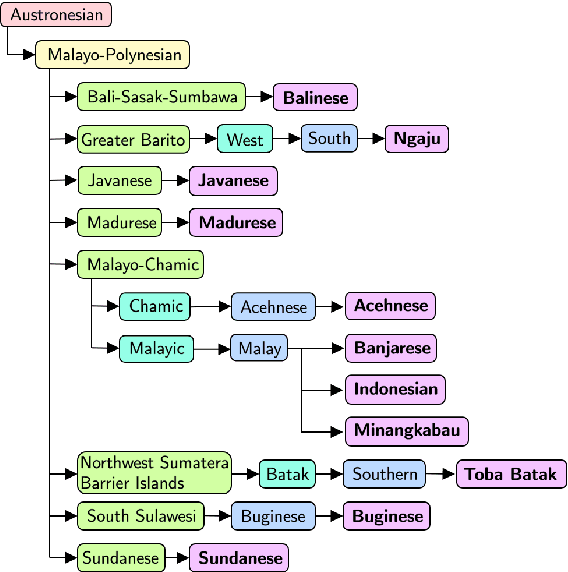
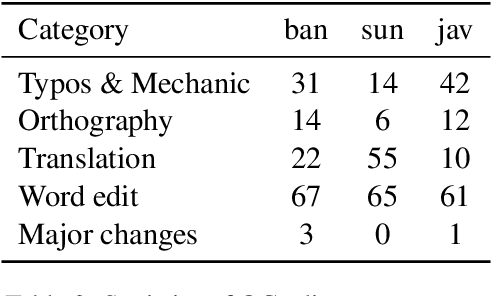
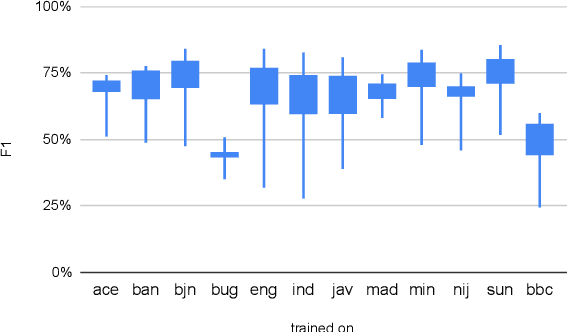
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
ParaCotta: Synthetic Multilingual Paraphrase Corpora from the Most Diverse Translation Sample Pair
May 10, 2022
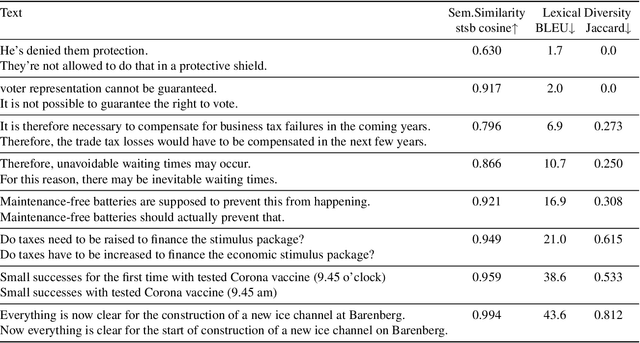
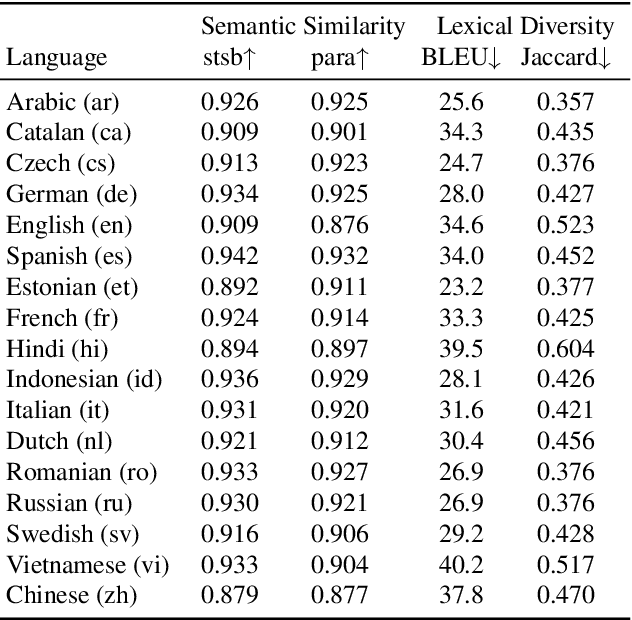
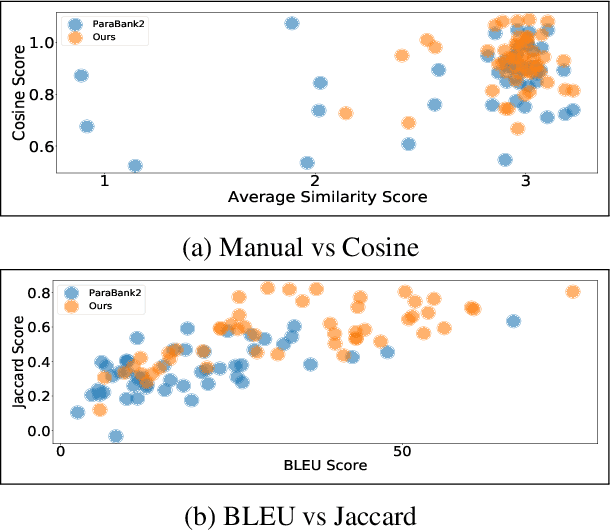
We release our synthetic parallel paraphrase corpus across 17 languages: Arabic, Catalan, Czech, German, English, Spanish, Estonian, French, Hindi, Indonesian, Italian, Dutch, Romanian, Russian, Swedish, Vietnamese, and Chinese. Our method relies only on monolingual data and a neural machine translation system to generate paraphrases, hence simple to apply. We generate multiple translation samples using beam search and choose the most lexically diverse pair according to their sentence BLEU. We compare our generated corpus with the \texttt{ParaBank2}. According to our evaluation, our synthetic paraphrase pairs are semantically similar and lexically diverse.
Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
Mar 29, 2022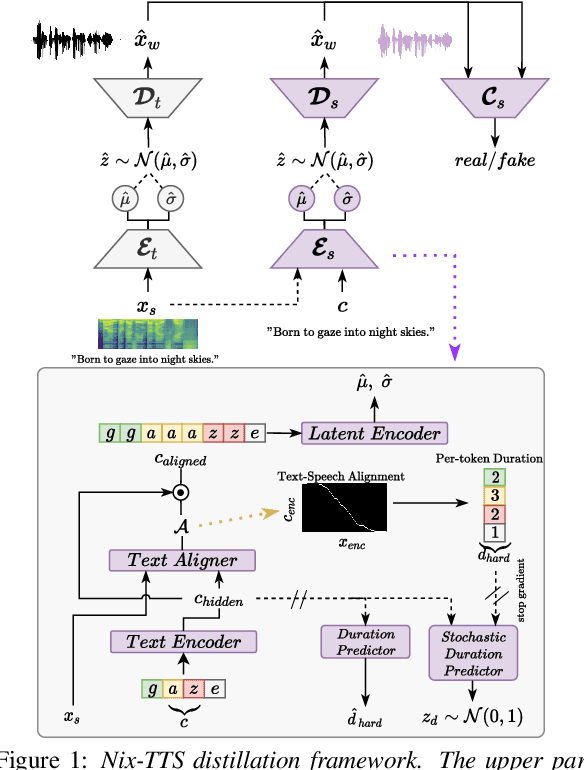
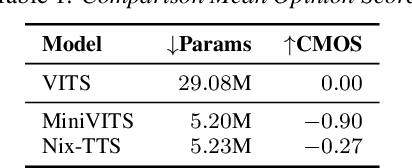
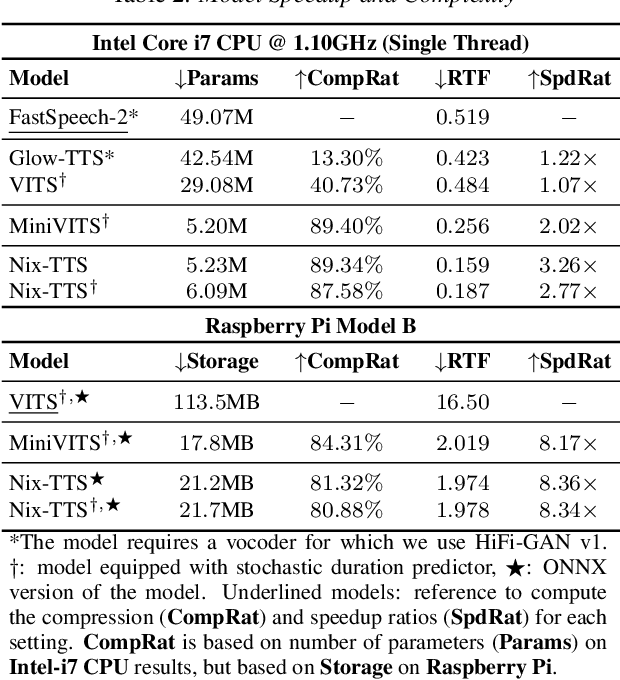
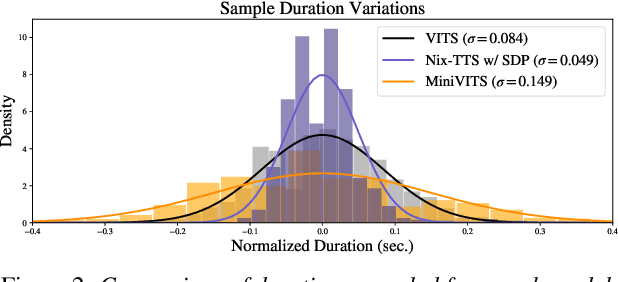
We propose Nix-TTS, a lightweight neural TTS (Text-to-Speech) model achieved by applying knowledge distillation to a powerful yet large-sized generative TTS teacher model. Distilling a TTS model might sound unintuitive due to the generative and disjointed nature of TTS architectures, but pre-trained TTS models can be simplified into encoder and decoder structures, where the former encodes text into some latent representation and the latter decodes the latent into speech data. We devise a framework to distill each component in a non end-to-end fashion. Nix-TTS is end-to-end (vocoder-free) with only 5.23M parameters or up to 82\% reduction of the teacher model, it achieves over 3.26$\times$ and 8.36$\times$ inference speedup on Intel-i7 CPU and Raspberry Pi respectively, and still retains a fair voice naturalness and intelligibility compared to the teacher model. We publicly release Nix-TTS pretrained models and audio samples in English (https://github.com/rendchevi/nix-tts).
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Mar 24, 2022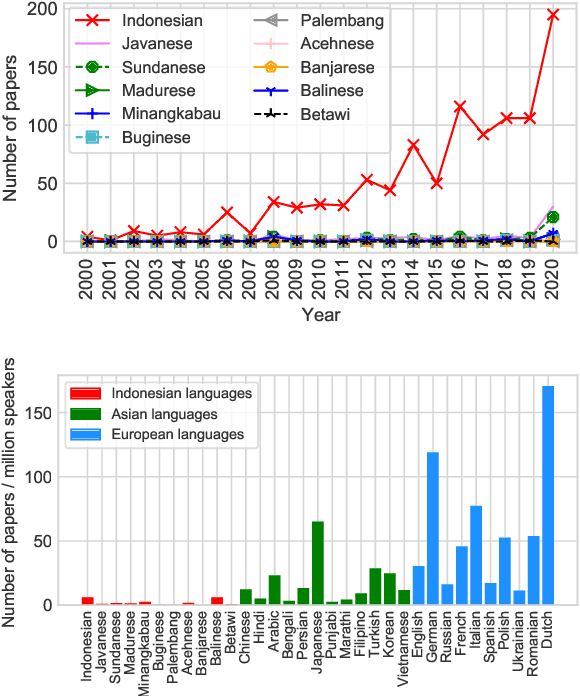
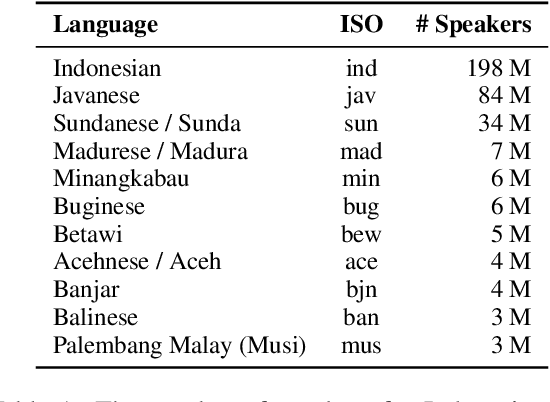
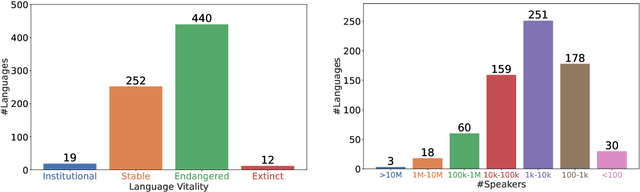

NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.
Which Student is Best? A Comprehensive Knowledge Distillation Exam for Task-Specific BERT Models
Jan 03, 2022
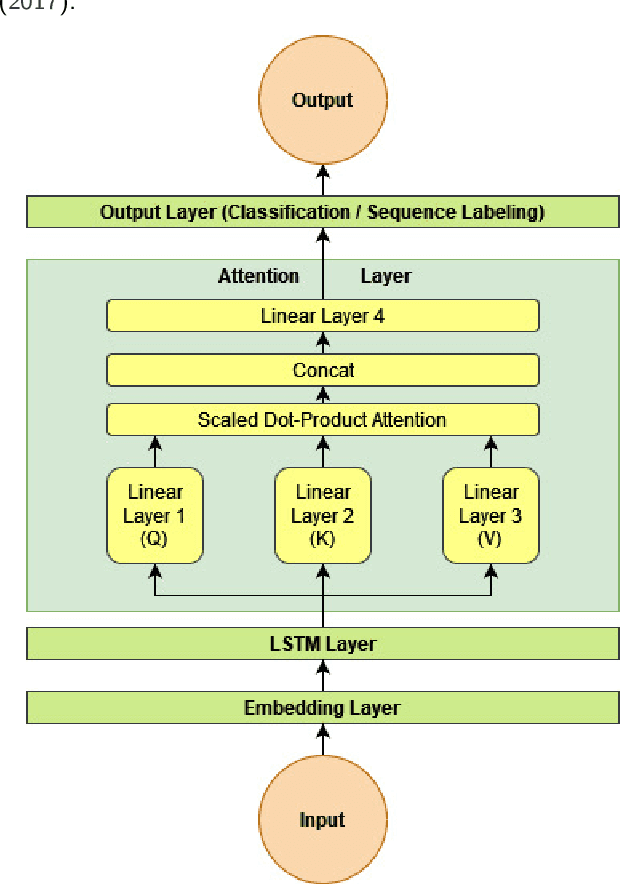
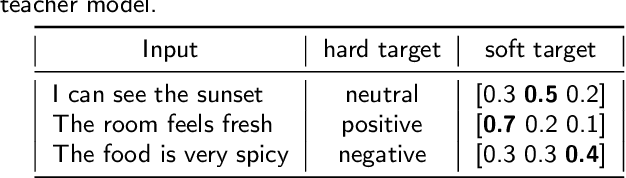
We perform knowledge distillation (KD) benchmark from task-specific BERT-base teacher models to various student models: BiLSTM, CNN, BERT-Tiny, BERT-Mini, and BERT-Small. Our experiment involves 12 datasets grouped in two tasks: text classification and sequence labeling in the Indonesian language. We also compare various aspects of distillations including the usage of word embeddings and unlabeled data augmentation. Our experiments show that, despite the rising popularity of Transformer-based models, using BiLSTM and CNN student models provide the best trade-off between performance and computational resource (CPU, RAM, and storage) compared to pruned BERT models. We further propose some quick wins on performing KD to produce small NLP models via efficient KD training mechanisms involving simple choices of loss functions, word embeddings, and unlabeled data preparation.
Synthetic Source Language Augmentation for Colloquial Neural Machine Translation
Dec 30, 2020

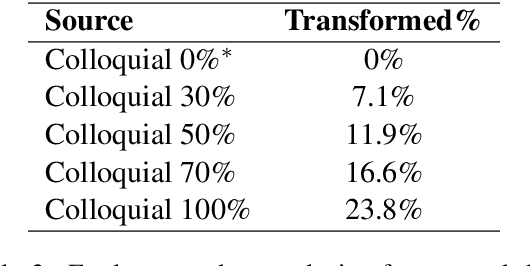
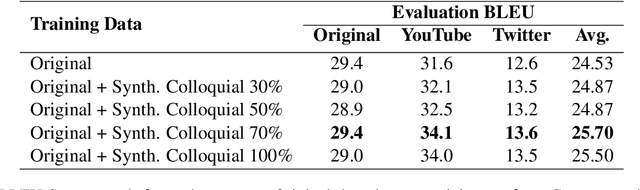
Neural machine translation (NMT) is typically domain-dependent and style-dependent, and it requires lots of training data. State-of-the-art NMT models often fall short in handling colloquial variations of its source language and the lack of parallel data in this regard is a challenging hurdle in systematically improving the existing models. In this work, we develop a novel colloquial Indonesian-English test-set collected from YouTube transcript and Twitter. We perform synthetic style augmentation to the source of formal Indonesian language and show that it improves the baseline Id-En models (in BLEU) over the new test data.