 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaCotta: Synthetic Multilingual Paraphrase Corpora from the Most Diverse Translation Sample Pair
May 10, 2022
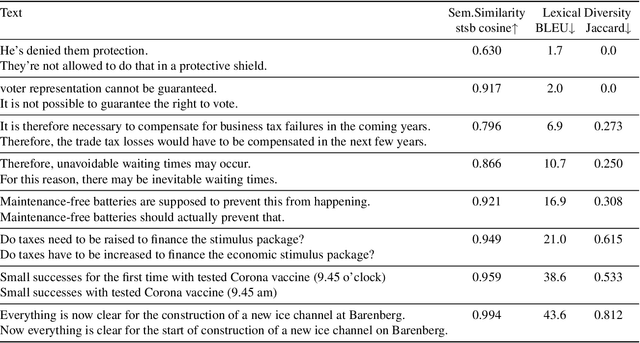
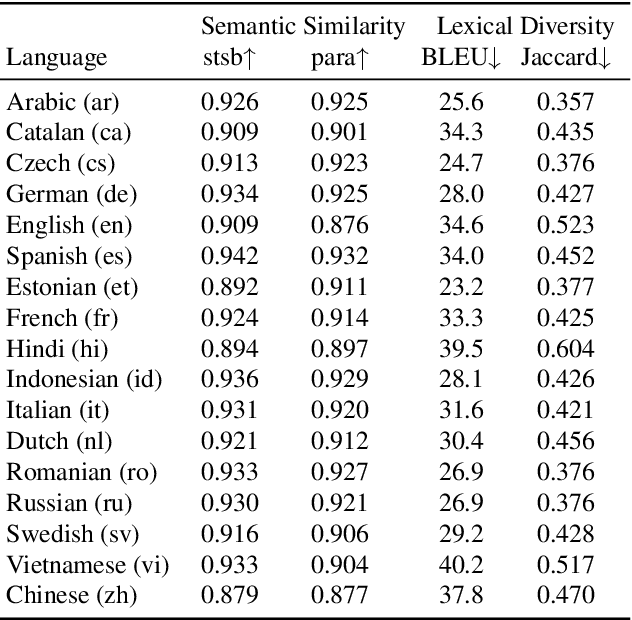
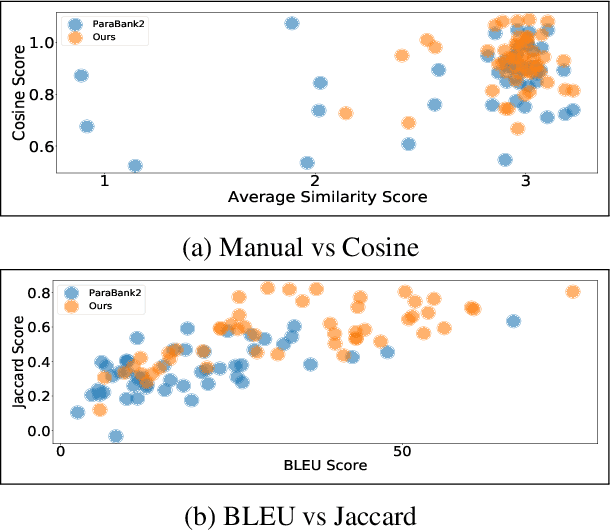
We release our synthetic parallel paraphrase corpus across 17 languages: Arabic, Catalan, Czech, German, English, Spanish, Estonian, French, Hindi, Indonesian, Italian, Dutch, Romanian, Russian, Swedish, Vietnamese, and Chinese. Our method relies only on monolingual data and a neural machine translation system to generate paraphrases, hence simple to apply. We generate multiple translation samples using beam search and choose the most lexically diverse pair according to their sentence BLEU. We compare our generated corpus with the \texttt{ParaBank2}. According to our evaluation, our synthetic paraphrase pairs are semantically similar and lexically diverse.
It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpretation Data
Oct 11, 2021
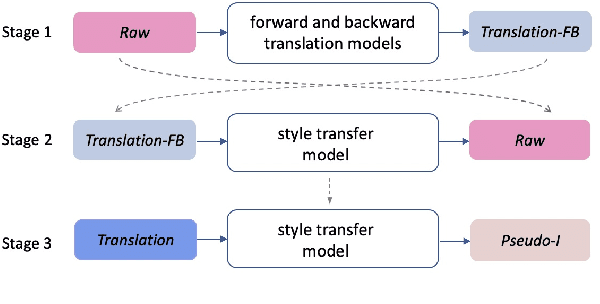

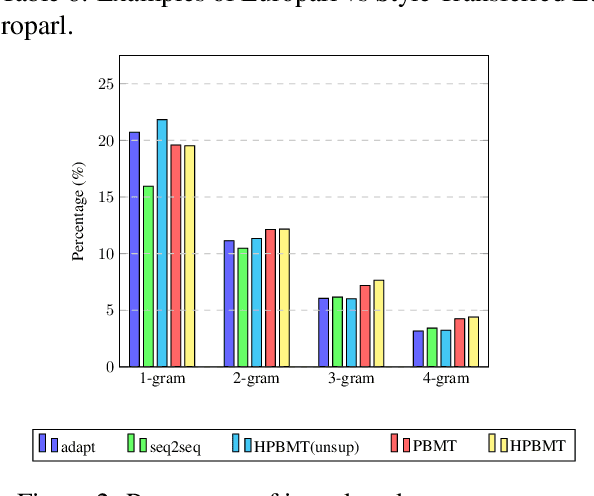
Most existing simultaneous machine translation (SiMT) systems are trained and evaluated on offline translation corpora. We argue that SiMT systems should be trained and tested on real interpretation data. To illustrate this argument, we propose an interpretation test set and conduct a realistic evaluation of SiMT trained on offline translations. Our results, on our test set along with 3 existing smaller scale language pairs, highlight the difference of up-to 13.83 BLEU score when SiMT models are evaluated on translation vs interpretation data. In the absence of interpretation training data, we propose a translation-to-interpretation (T2I) style transfer method which allows converting existing offline translations into interpretation-style data, leading to up-to 2.8 BLEU improvement. However, the evaluation gap remains notable, calling for constructing large-scale interpretation corpora better suited for evaluating and developing SiMT systems.
Learning Coupled Policies for Simultaneous Machine Translation
Feb 11, 2020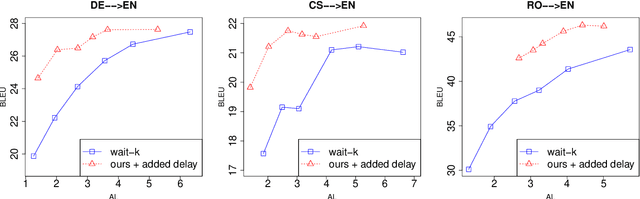
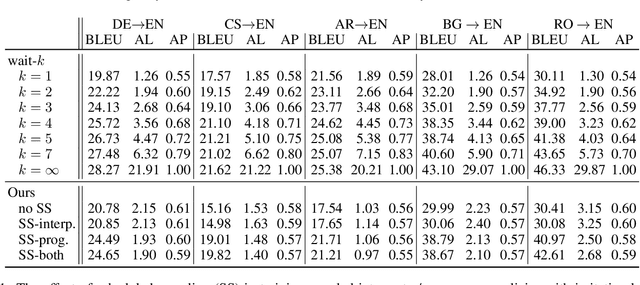

In simultaneous machine translation, the system needs to incrementally generate the output translation before the input sentence ends. This is a coupled decision process consisting of a programmer and interpreter. The programmer's policy decides about when to WRITE the next output or READ the next input, and the interpreter's policy decides what word to write. We present an imitation learning (IL) approach to efficiently learn effective coupled programmer-interpreter policies. To enable IL, we present an algorithmic oracle to produce oracle READ/WRITE actions for training bilingual sentence-pairs using the notion of word alignments. We attribute the effectiveness of the learned coupled policies to (i) scheduled sampling addressing the coupled exposure bias, and (ii) quality of oracle actions capturing enough information from the partial input before writing the output. Experiments show our method outperforms strong baselines in terms of translation quality and delay, when translating from German/Arabic/Czech/Bulgarian/Romanian to English.
Multilingual Neural Machine Translation With Soft Decoupled Encoding
Feb 09, 2019


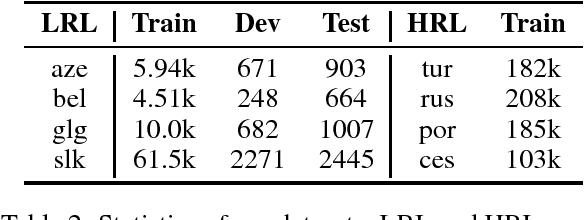
Multilingual training of neural machine translation (NMT) systems has led to impressive accuracy improvements on low-resource languages. However, there are still significant challenges in efficiently learning word representations in the face of paucity of data. In this paper, we propose Soft Decoupled Encoding (SDE), a multilingual lexicon encoding framework specifically designed to share lexical-level information intelligently without requiring heuristic preprocessing such as pre-segmenting the data. SDE represents a word by its spelling through a character encoding, and its semantic meaning through a latent embedding space shared by all languages. Experiments on a standard dataset of four low-resource languages show consistent improvements over strong multilingual NMT baselines, with gains of up to 2 BLEU on one of the tested languages, achieving the new state-of-the-art on all four language pairs.
XNMT: The eXtensible Neural Machine Translation Toolkit
Mar 01, 2018


This paper describes XNMT, the eXtensible Neural Machine Translation toolkit. XNMT distin- guishes itself from other open-source NMT toolkits by its focus on modular code design, with the purpose of enabling fast iteration in research and replicable, reliable results. In this paper we describe the design of XNMT and its experiment configuration system, and demonstrate its utility on the tasks of machine translation, speech recognition, and multi-tasked machine translation/parsing. XNMT is available open-source at https://github.com/neulab/xnmt
Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the "Speaking Rosetta" JSALT 2017 Workshop
Feb 14, 2018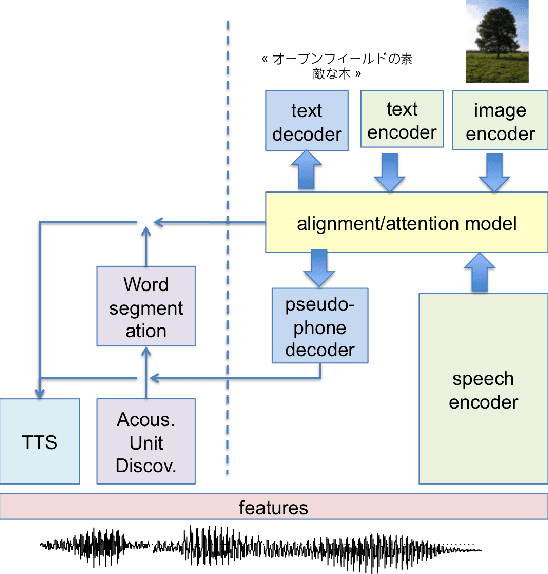

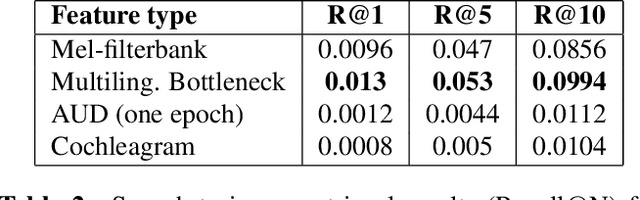
We summarize the accomplishments of a multi-disciplinary workshop exploring the computational and scientific issues surrounding the discovery of linguistic units (subwords and words) in a language without orthography. We study the replacement of orthographic transcriptions by images and/or translated text in a well-resourced language to help unsupervised discovery from raw speech.
Neural Machine Translation via Binary Code Prediction
Apr 23, 2017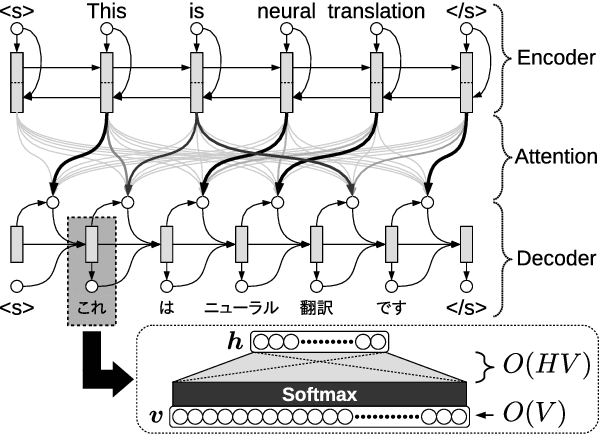
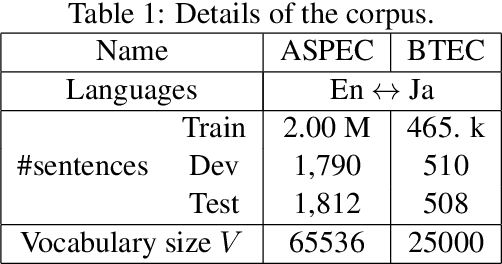

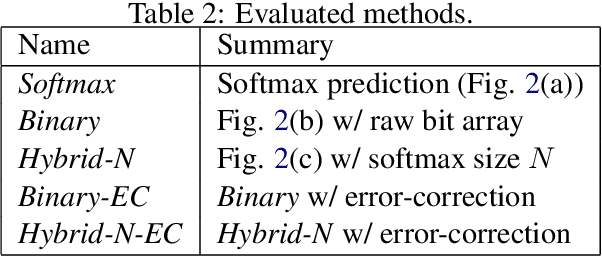
In this paper, we propose a new method for calculating the output layer in neural machine translation systems. The method is based on predicting a binary code for each word and can reduce computation time/memory requirements of the output layer to be logarithmic in vocabulary size in the best case. In addition, we also introduce two advanced approaches to improve the robustness of the proposed model: using error-correcting codes and combining softmax and binary codes. Experiments on two English-Japanese bidirectional translation tasks show proposed models achieve BLEU scores that approach the softmax, while reducing memory usage to the order of less than 1/10 and improving decoding speed on CPUs by x5 to x10.
Incorporating Discrete Translation Lexicons into Neural Machine Translation
Oct 05, 2016
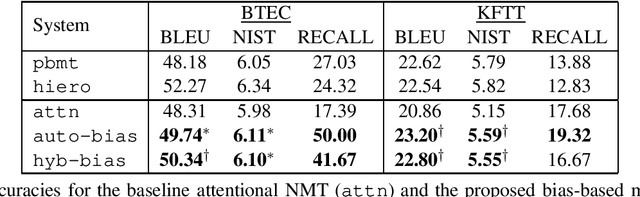
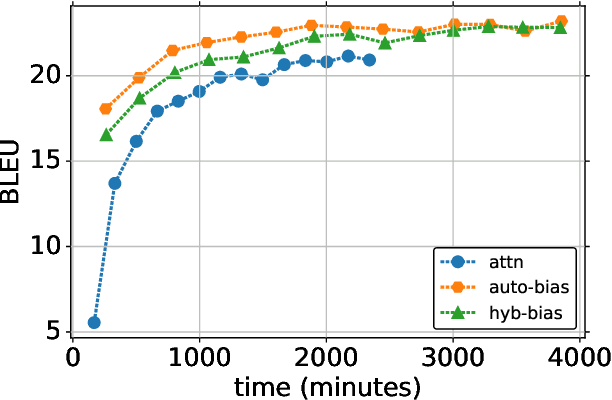
Neural machine translation (NMT) often makes mistakes in translating low-frequency content words that are essential to understanding the meaning of the sentence. We propose a method to alleviate this problem by augmenting NMT systems with discrete translation lexicons that efficiently encode translations of these low-frequency words. We describe a method to calculate the lexicon probability of the next word in the translation candidate by using the attention vector of the NMT model to select which source word lexical probabilities the model should focus on. We test two methods to combine this probability with the standard NMT probability: (1) using it as a bias, and (2) linear interpolation. Experiments on two corpora show an improvement of 2.0-2.3 BLEU and 0.13-0.44 NIST score, and faster convergence time.