 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-spontaneous Dutch Speech Dataset for Speech Enhancement and Speech Recognition
Mar 10, 2026We present DRES: a 1.5-hour Dutch realistic elicited (semi-spontaneous) speech dataset from 80 speakers recorded in noisy, public indoor environments. DRES was designed as a test set for the evaluation of state-of-the-art (SOTA) automatic speech recognition (ASR) and speech enhancement (SE) models in a real-world scenario: a person speaking in a public indoor space with background talkers and noise. The speech was recorded with a four-channel linear microphone array. In this work we evaluate the speech quality of five well-known single-channel SE algorithms and the recognition performance of eight SOTA off-the-shelf ASR models before and after applying SE on the speech of DRES. We found that five out of the eight ASR models have WERs lower than 22% on DRES, despite the challenging conditions. In contrast to recent work, we did not find a positive effect of modern single-channel SE on ASR performance, emphasizing the importance of evaluating in realistic conditions.
Objective and Subjective Evaluation of Diffusion-Based Speech Enhancement for Dysarthric Speech
Aug 25, 2025Dysarthric speech poses significant challenges for automatic speech recognition (ASR) systems due to its high variability and reduced intelligibility. In this work we explore the use of diffusion models for dysarthric speech enhancement, which is based on the hypothesis that using diffusion-based speech enhancement moves the distribution of dysarthric speech closer to that of typical speech, which could potentially improve dysarthric speech recognition performance. We assess the effect of two diffusion-based and one signal-processing-based speech enhancement algorithms on intelligibility and speech quality of two English dysarthric speech corpora. We applied speech enhancement to both typical and dysarthric speech and evaluate the ASR performance using Whisper-Turbo, and the subjective and objective speech quality of the original and enhanced dysarthric speech. We also fine-tuned Whisper-Turbo on the enhanced speech to assess its impact on recognition performance.
Loudspeaker Beamforming to Enhance Speech Recognition Performance of Voice Driven Applications
Jan 14, 2025
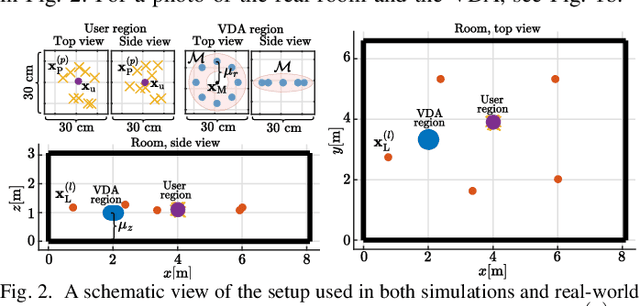


In this paper we propose a robust loudspeaker beamforming algorithm which is used to enhance the performance of voice driven applications in scenarios where the loudspeakers introduce the majority of the noise, e.g. when music is playing loudly. The loudspeaker beamformer modifies the loudspeaker playback signals to create a low-acoustic-energy region around the device that implements automatic speech recognition for a voice driven application (VDA). The algorithm utilises a distortion measure based on human auditory perception to limit the distortion perceived by human listeners. Simulations and real-world experiments show that the proposed loudspeaker beamformer improves the speech recognition performance in all tested scenarios. Moreover, the algorithm allows to further reduce the acoustic energy around the VDA device at the expense of reduced objective audio quality at the listener's location.
Good practices for evaluation of machine learning systems
Dec 04, 2024



Many development decisions affect the results obtained from ML experiments: training data, features, model architecture, hyperparameters, test data, etc. Among these aspects, arguably the most important design decisions are those that involve the evaluation procedure. This procedure is what determines whether the conclusions drawn from the experiments will or will not generalize to unseen data and whether they will be relevant to the application of interest. If the data is incorrectly selected, the wrong metric is chosen for evaluation or the significance of the comparisons between models is overestimated, conclusions may be misleading or result in suboptimal development decisions. To avoid such problems, the evaluation protocol should be very carefully designed before experimentation starts. In this work we discuss the main aspects involved in the design of the evaluation protocol: data selection, metric selection, and statistical significance. This document is not meant to be an exhaustive tutorial on each of these aspects. Instead, the goal is to explain the main guidelines that should be followed in each case. We include examples taken from the speech processing field, and provide a list of common mistakes related to each aspect.
Self-supervised Speech Representations Still Struggle with African American Vernacular English
Aug 26, 2024

Underperformance of ASR systems for speakers of African American Vernacular English (AAVE) and other marginalized language varieties is a well-documented phenomenon, and one that reinforces the stigmatization of these varieties. We investigate whether or not the recent wave of Self-Supervised Learning (SSL) speech models can close the gap in ASR performance between AAVE and Mainstream American English (MAE). We evaluate four SSL models (wav2vec 2.0, HuBERT, WavLM, and XLS-R) on zero-shot Automatic Speech Recognition (ASR) for these two varieties and find that these models perpetuate the bias in performance against AAVE. Additionally, the models have higher word error rates on utterances with more phonological and morphosyntactic features of AAVE. Despite the success of SSL speech models in improving ASR for low resource varieties, SSL pre-training alone may not bridge the gap between AAVE and MAE. Our code is publicly available at https://github.com/cmu-llab/s3m-aave.
As Biased as You Measure: Methodological Pitfalls of Bias Evaluations in Speaker Verification Research
Aug 24, 2024
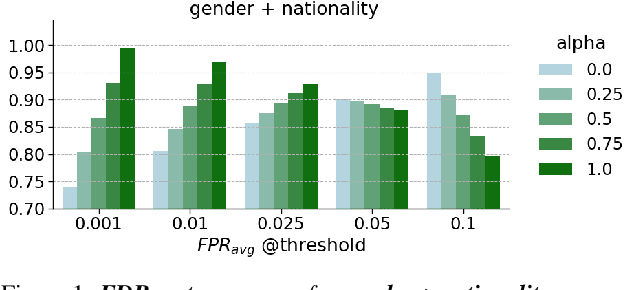
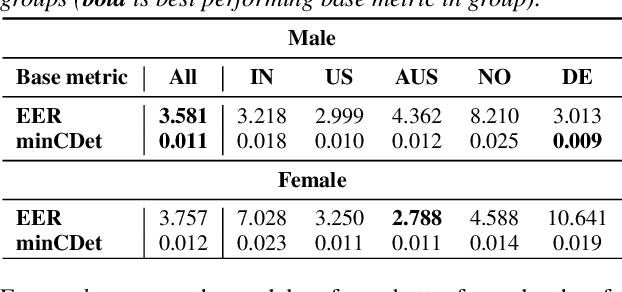
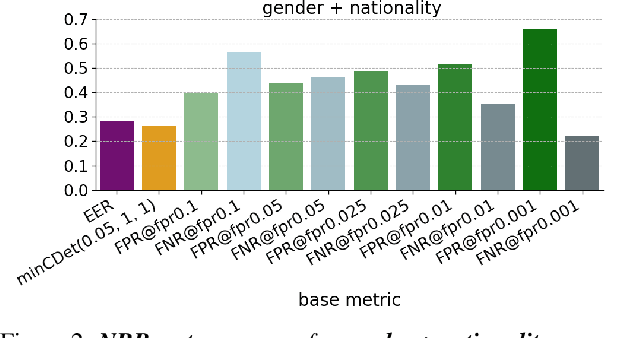
Detecting and mitigating bias in speaker verification systems is important, as datasets, processing choices and algorithms can lead to performance differences that systematically favour some groups of people while disadvantaging others. Prior studies have thus measured performance differences across groups to evaluate bias. However, when comparing results across studies, it becomes apparent that they draw contradictory conclusions, hindering progress in this area. In this paper we investigate how measurement impacts the outcomes of bias evaluations. We show empirically that bias evaluations are strongly influenced by base metrics that measure performance, by the choice of ratio or difference-based bias measure, and by the aggregation of bias measures into meta-measures. Based on our findings, we recommend the use of ratio-based bias measures, in particular when the values of base metrics are small, or when base metrics with different orders of magnitude need to be compared.
Improving child speech recognition with augmented child-like speech
Jun 12, 2024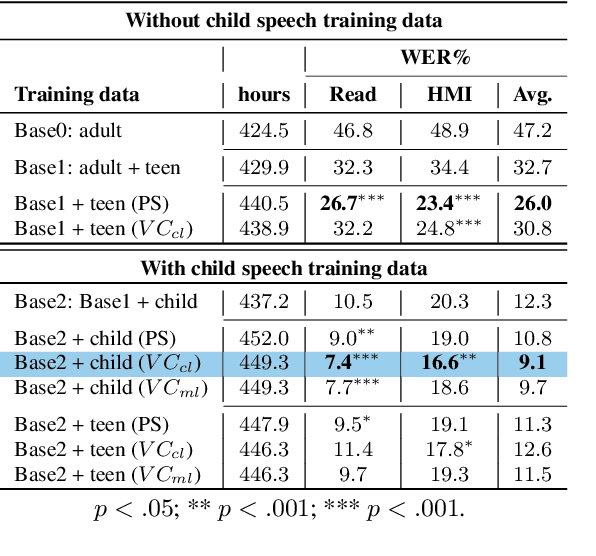
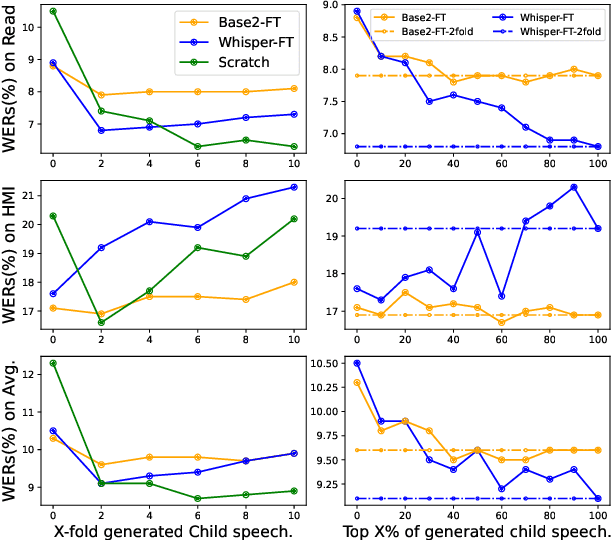
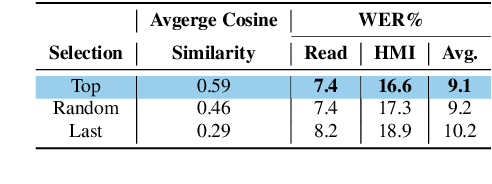
State-of-the-art ASRs show suboptimal performance for child speech. The scarcity of child speech limits the development of child speech recognition (CSR). Therefore, we studied child-to-child voice conversion (VC) from existing child speakers in the dataset and additional (new) child speakers via monolingual and cross-lingual (Dutch-to-German) VC, respectively. The results showed that cross-lingual child-to-child VC significantly improved child ASR performance. Experiments on the impact of the quantity of child-to-child cross-lingual VC-generated data on fine-tuning (FT) ASR models gave the best results with two-fold augmentation for our FT-Conformer model and FT-Whisper model which reduced WERs with ~3% absolute compared to the baseline, and with six-fold augmentation for the model trained from scratch, which improved by an absolute 3.6% WER. Moreover, using a small amount of "high-quality" VC-generated data achieved similar results to those of our best-FT models.
Exploring data augmentation in bias mitigation against non-native-accented speech
Dec 24, 2023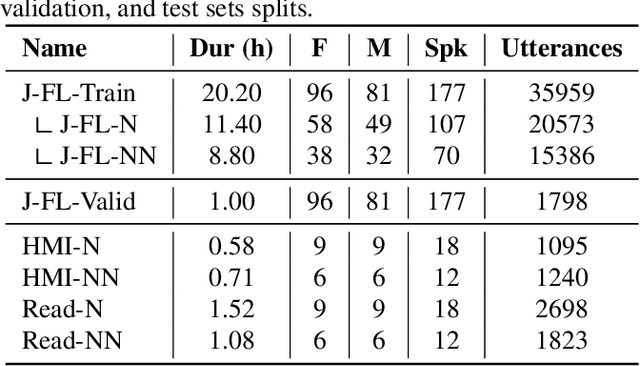
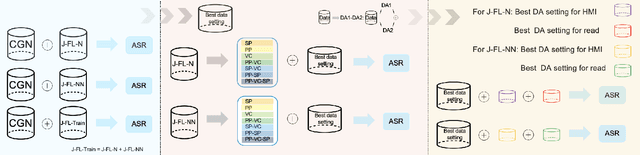
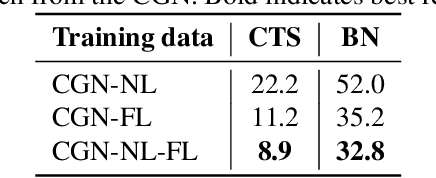
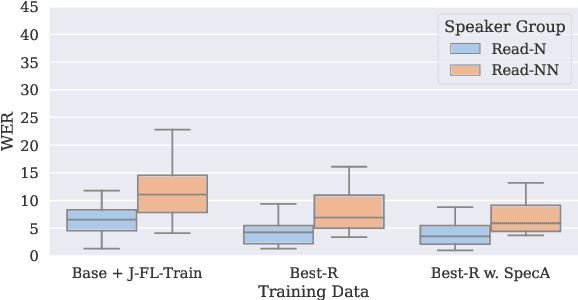
Automatic speech recognition (ASR) should serve every speaker, not only the majority ``standard'' speakers of a language. In order to build inclusive ASR, mitigating the bias against speaker groups who speak in a ``non-standard'' or ``diverse'' way is crucial. We aim to mitigate the bias against non-native-accented Flemish in a Flemish ASR system. Since this is a low-resource problem, we investigate the optimal type of data augmentation, i.e., speed/pitch perturbation, cross-lingual voice conversion-based methods, and SpecAugment, applied to both native Flemish and non-native-accented Flemish, for bias mitigation. The results showed that specific types of data augmentation applied to both native and non-native-accented speech improve non-native-accented ASR while applying data augmentation to the non-native-accented speech is more conducive to bias reduction. Combining both gave the largest bias reduction for human-machine interaction (HMI) as well as read-type speech.
Improving Whispered Speech Recognition Performance using Pseudo-whispered based Data Augmentation
Nov 09, 2023
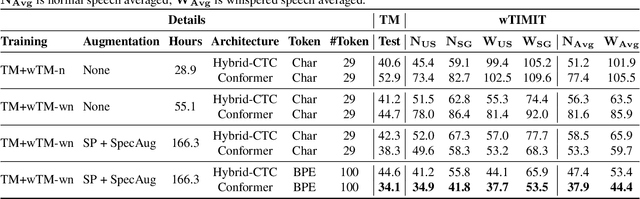

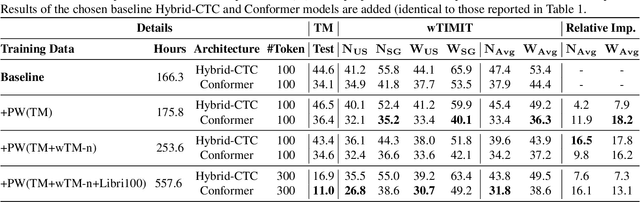
Whispering is a distinct form of speech known for its soft, breathy, and hushed characteristics, often used for private communication. The acoustic characteristics of whispered speech differ substantially from normally phonated speech and the scarcity of adequate training data leads to low automatic speech recognition (ASR) performance. To address the data scarcity issue, we use a signal processing-based technique that transforms the spectral characteristics of normal speech to those of pseudo-whispered speech. We augment an End-to-End ASR with pseudo-whispered speech and achieve an 18.2% relative reduction in word error rate for whispered speech compared to the baseline. Results for the individual speaker groups in the wTIMIT database show the best results for US English. Further investigation showed that the lack of glottal information in whispered speech has the largest impact on whispered speech ASR performance.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023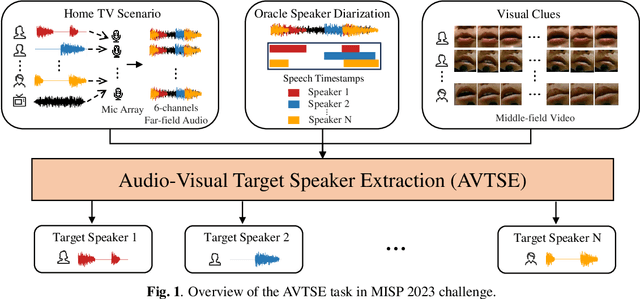
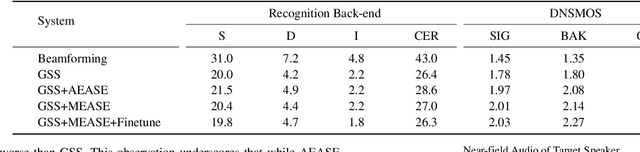
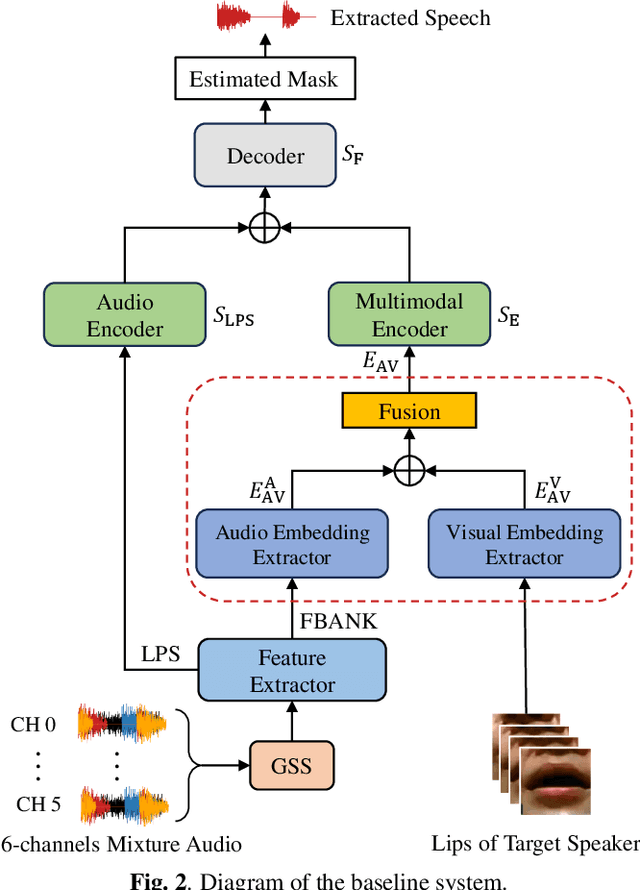

Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.