 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoPETR: Improving Temporal Camera-Only 3D Detection by Integrating Enhanced Rotary Position Embedding
Apr 18, 2025This technical report introduces a targeted improvement to the StreamPETR framework, specifically aimed at enhancing velocity estimation, a critical factor influencing the overall NuScenes Detection Score. While StreamPETR exhibits strong 3D bounding box detection performance as reflected by its high mean Average Precision our analysis identified velocity estimation as a substantial bottleneck when evaluated on the NuScenes dataset. To overcome this limitation, we propose a customized positional embedding strategy tailored to enhance temporal modeling capabilities. Experimental evaluations conducted on the NuScenes test set demonstrate that our improved approach achieves a state-of-the-art NDS of 70.86% using the ViT-L backbone, setting a new benchmark for camera-only 3D object detection.
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Aug 13, 2024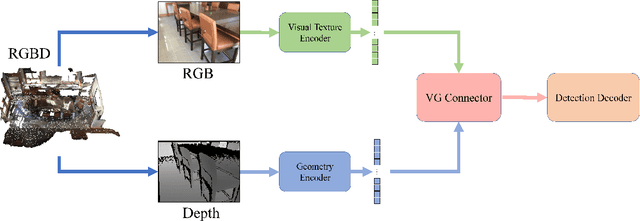
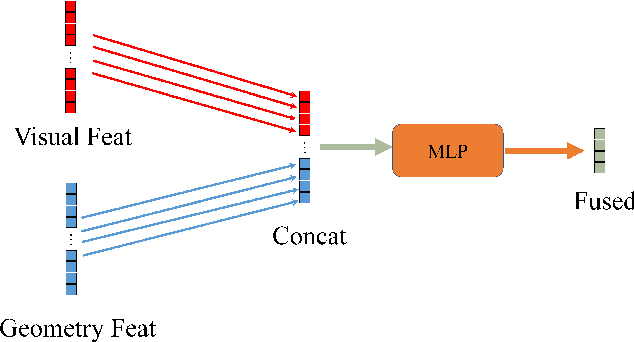
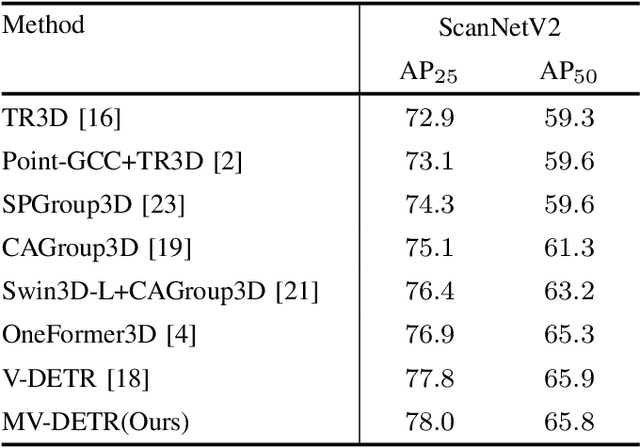
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78\% AP which create new state of the art on ScanNetv2 benchmark.
LVIC: Multi-modality segmentation by Lifting Visual Info as Cue
Mar 08, 2024


Multi-modality fusion is proven an effective method for 3d perception for autonomous driving. However, most current multi-modality fusion pipelines for LiDAR semantic segmentation have complicated fusion mechanisms. Point painting is a quite straight forward method which directly bind LiDAR points with visual information. Unfortunately, previous point painting like methods suffer from projection error between camera and LiDAR. In our experiments, we find that this projection error is the devil in point painting. As a result of that, we propose a depth aware point painting mechanism, which significantly boosts the multi-modality fusion. Apart from that, we take a deeper look at the desired visual feature for LiDAR to operate semantic segmentation. By Lifting Visual Information as Cue, LVIC ranks 1st on nuScenes LiDAR semantic segmentation benchmark. Our experiments show the robustness and effectiveness. Codes would be make publicly available soon.
PeP: a Point enhanced Painting method for unified point cloud tasks
Oct 11, 2023


Point encoder is of vital importance for point cloud recognition. As the very beginning step of whole model pipeline, adding features from diverse sources and providing stronger feature encoding mechanism would provide better input for downstream modules. In our work, we proposed a novel PeP module to tackle above issue. PeP contains two main parts, a refined point painting method and a LM-based point encoder. Experiments results on the nuScenes and KITTI datasets validate the superior performance of our PeP. The advantages leads to strong performance on both semantic segmentation and object detection, in both lidar and multi-modal settings. Notably, our PeP module is model agnostic and plug-and-play. Our code will be publicly available soon.
HuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Aug 24, 2023

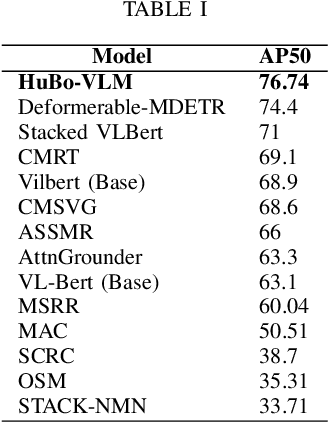
Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
OG: Equip vision occupancy with instance segmentation and visual grounding
Jul 12, 2023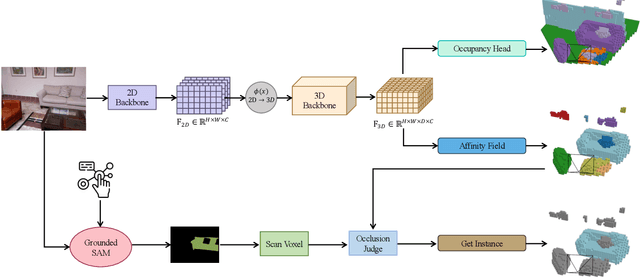
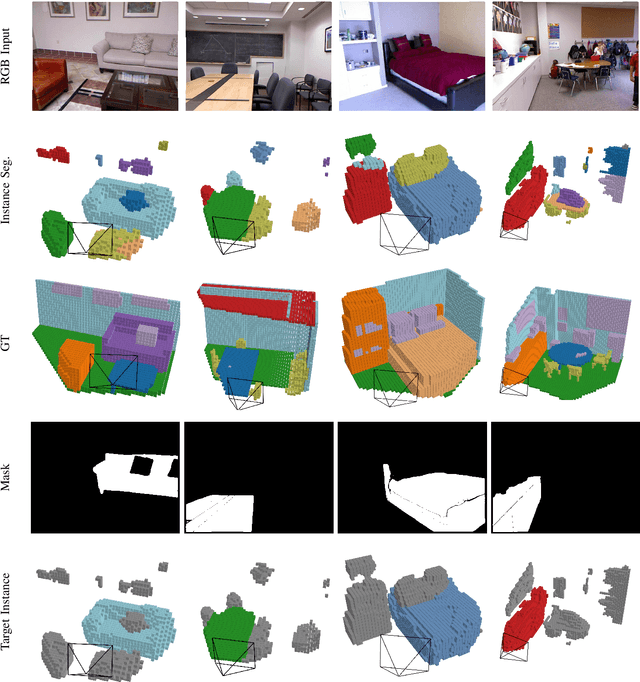
Occupancy prediction tasks focus on the inference of both geometry and semantic labels for each voxel, which is an important perception mission. However, it is still a semantic segmentation task without distinguishing various instances. Further, although some existing works, such as Open-Vocabulary Occupancy (OVO), have already solved the problem of open vocabulary detection, visual grounding in occupancy has not been solved to the best of our knowledge. To tackle the above two limitations, this paper proposes Occupancy Grounding (OG), a novel method that equips vanilla occupancy instance segmentation ability and could operate visual grounding in a voxel manner with the help of grounded-SAM. Keys to our approach are (1) affinity field prediction for instance clustering and (2) association strategy for aligning 2D instance masks and 3D occupancy instances. Extensive experiments have been conducted whose visualization results and analysis are shown below. Our code will be publicly released soon.
OVO: Open-Vocabulary Occupancy
May 25, 2023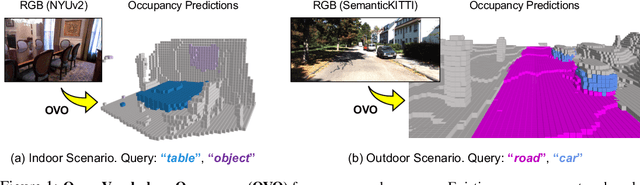

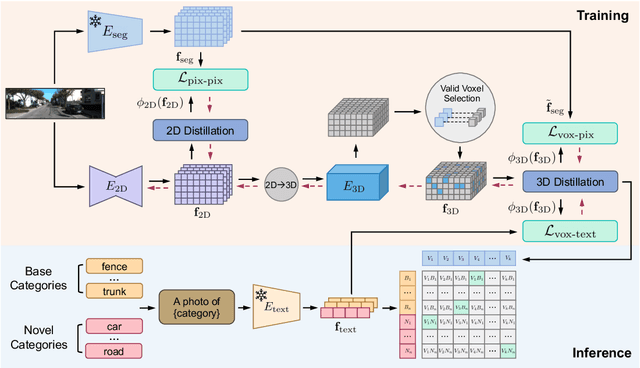

Semantic occupancy prediction aims to infer dense geometry and semantics of surroundings for an autonomous agent to operate safely in the 3D environment. Existing occupancy prediction methods are almost entirely trained on human-annotated volumetric data. Although of high quality, the generation of such 3D annotations is laborious and costly, restricting them to a few specific object categories in the training dataset. To address this limitation, this paper proposes Open Vocabulary Occupancy (OVO), a novel approach that allows semantic occupancy prediction of arbitrary classes but without the need for 3D annotations during training. Keys to our approach are (1) knowledge distillation from a pre-trained 2D open-vocabulary segmentation model to the 3D occupancy network, and (2) pixel-voxel filtering for high-quality training data generation. The resulting framework is simple, compact, and compatible with most state-of-the-art semantic occupancy prediction models. On NYUv2 and SemanticKITTI datasets, OVO achieves competitive performance compared to supervised semantic occupancy prediction approaches. Furthermore, we conduct extensive analyses and ablation studies to offer insights into the design of the proposed framework.
Predicting within and across language phoneme recognition performance of self-supervised learning speech pre-trained models
Jun 24, 2022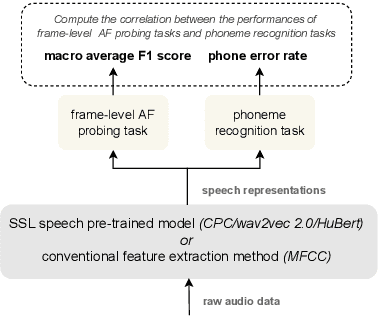
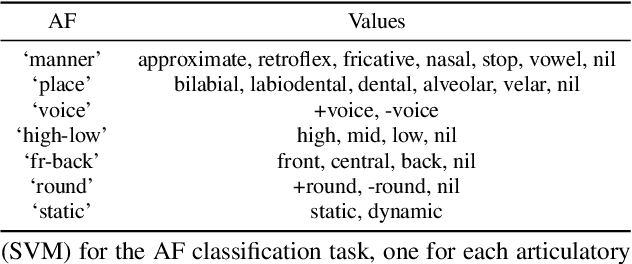
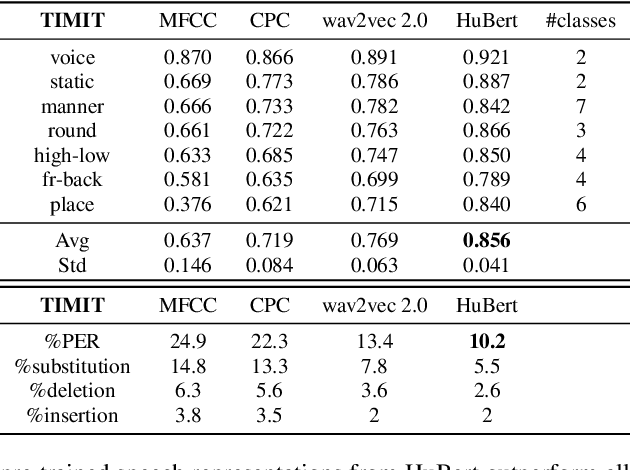
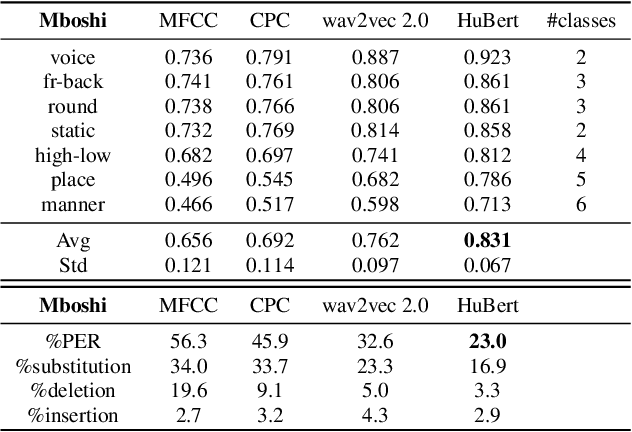
In this work, we analyzed and compared speech representations extracted from different frozen self-supervised learning (SSL) speech pre-trained models on their ability to capture articulatory features (AF) information and their subsequent prediction of phone recognition performance for within and across language scenarios. Specifically, we compared CPC, wav2vec 2.0, and HuBert. First, frame-level AF probing tasks were implemented. Subsequently, phone-level end-to-end ASR systems for phoneme recognition tasks were implemented, and the performance on the frame-level AF probing task and the phone accuracy were correlated. Compared to the conventional speech representation MFCC, all SSL pre-trained speech representations captured more AF information, and achieved better phoneme recognition performance within and across languages, with HuBert performing best. The frame-level AF probing task is a good predictor of phoneme recognition performance, showing the importance of capturing AF information in the speech representations. Compared with MFCC, in the within-language scenario, the performance of these SSL speech pre-trained models on AF probing tasks achieved a maximum relative increase of 34.4%, and it resulted in the lowest PER of 10.2%. In the cross-language scenario, the maximum relative increase of 26.7% also resulted in the lowest PER of 23.0%.