 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErase to Improve: Erasable Reinforcement Learning for Search-Augmented LLMs
Oct 01, 2025While search-augmented large language models (LLMs) exhibit impressive capabilities, their reliability in complex multi-hop reasoning remains limited. This limitation arises from three fundamental challenges: decomposition errors, where tasks are incorrectly broken down; retrieval missing, where key evidence fails to be retrieved; and reasoning errors, where flawed logic propagates through the reasoning chain. A single failure in any of these stages can derail the final answer. We propose Erasable Reinforcement Learning (ERL), a novel framework that transforms fragile reasoning into a robust process. ERL explicitly identifies faulty steps, erases them, and regenerates reasoning in place, preventing defective logic from propagating through the reasoning chain. This targeted correction mechanism turns brittle reasoning into a more resilient process. Models trained with ERL, termed ESearch, achieve substantial improvements on HotpotQA, MuSiQue, 2Wiki, and Bamboogle, with the 3B model achieving +8.48% EM and +11.56% F1, and the 7B model achieving +5.38% EM and +7.22% F1 over previous state-of-the-art(SOTA) results. These findings suggest that erasable reinforcement learning provides a powerful paradigm shift for robust multi-step reasoning in LLMs.
PeP: a Point enhanced Painting method for unified point cloud tasks
Oct 11, 2023


Point encoder is of vital importance for point cloud recognition. As the very beginning step of whole model pipeline, adding features from diverse sources and providing stronger feature encoding mechanism would provide better input for downstream modules. In our work, we proposed a novel PeP module to tackle above issue. PeP contains two main parts, a refined point painting method and a LM-based point encoder. Experiments results on the nuScenes and KITTI datasets validate the superior performance of our PeP. The advantages leads to strong performance on both semantic segmentation and object detection, in both lidar and multi-modal settings. Notably, our PeP module is model agnostic and plug-and-play. Our code will be publicly available soon.
HuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Aug 24, 2023

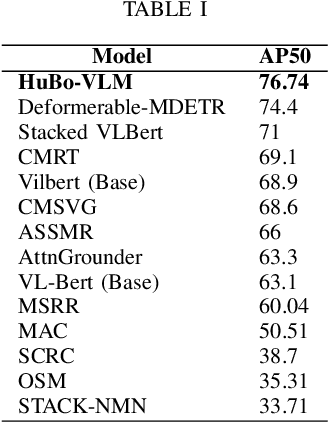
Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
OG: Equip vision occupancy with instance segmentation and visual grounding
Jul 12, 2023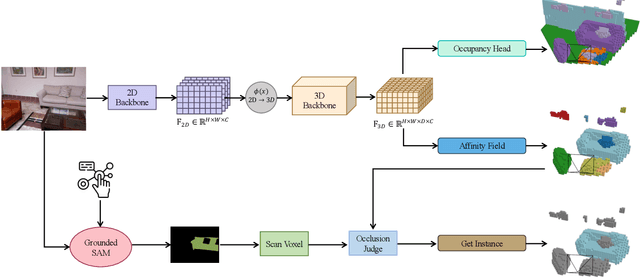
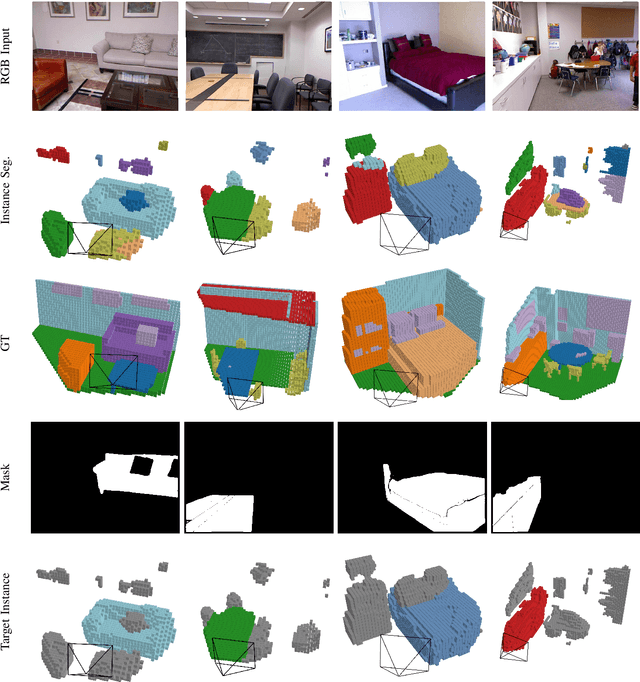
Occupancy prediction tasks focus on the inference of both geometry and semantic labels for each voxel, which is an important perception mission. However, it is still a semantic segmentation task without distinguishing various instances. Further, although some existing works, such as Open-Vocabulary Occupancy (OVO), have already solved the problem of open vocabulary detection, visual grounding in occupancy has not been solved to the best of our knowledge. To tackle the above two limitations, this paper proposes Occupancy Grounding (OG), a novel method that equips vanilla occupancy instance segmentation ability and could operate visual grounding in a voxel manner with the help of grounded-SAM. Keys to our approach are (1) affinity field prediction for instance clustering and (2) association strategy for aligning 2D instance masks and 3D occupancy instances. Extensive experiments have been conducted whose visualization results and analysis are shown below. Our code will be publicly released soon.
OVO: Open-Vocabulary Occupancy
May 25, 2023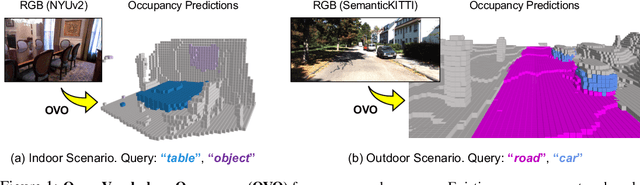

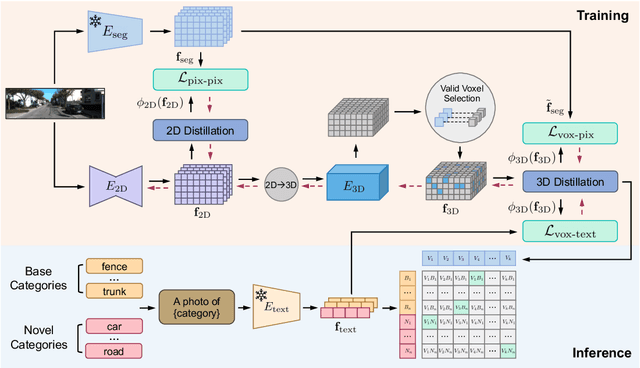

Semantic occupancy prediction aims to infer dense geometry and semantics of surroundings for an autonomous agent to operate safely in the 3D environment. Existing occupancy prediction methods are almost entirely trained on human-annotated volumetric data. Although of high quality, the generation of such 3D annotations is laborious and costly, restricting them to a few specific object categories in the training dataset. To address this limitation, this paper proposes Open Vocabulary Occupancy (OVO), a novel approach that allows semantic occupancy prediction of arbitrary classes but without the need for 3D annotations during training. Keys to our approach are (1) knowledge distillation from a pre-trained 2D open-vocabulary segmentation model to the 3D occupancy network, and (2) pixel-voxel filtering for high-quality training data generation. The resulting framework is simple, compact, and compatible with most state-of-the-art semantic occupancy prediction models. On NYUv2 and SemanticKITTI datasets, OVO achieves competitive performance compared to supervised semantic occupancy prediction approaches. Furthermore, we conduct extensive analyses and ablation studies to offer insights into the design of the proposed framework.
BundleRecon: Ray Bundle-Based 3D Neural Reconstruction
May 12, 2023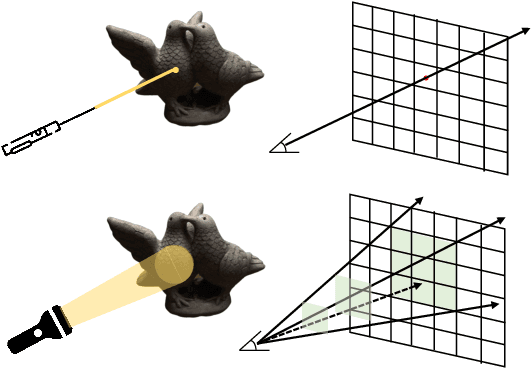
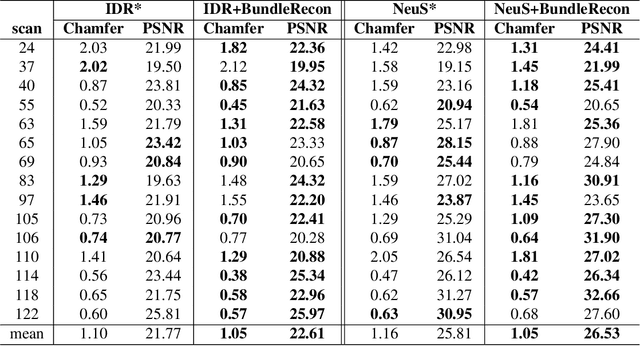
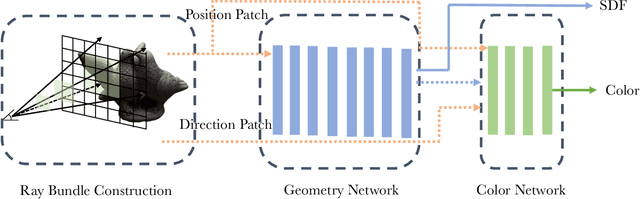

With the growing popularity of neural rendering, there has been an increasing number of neural implicit multi-view reconstruction methods. While many models have been enhanced in terms of positional encoding, sampling, rendering, and other aspects to improve the reconstruction quality, current methods do not fully leverage the information among neighboring pixels during the reconstruction process. To address this issue, we propose an enhanced model called BundleRecon. In the existing approaches, sampling is performed by a single ray that corresponds to a single pixel. In contrast, our model samples a patch of pixels using a bundle of rays, which incorporates information from neighboring pixels. Furthermore, we design bundle-based constraints to further improve the reconstruction quality. Experimental results demonstrate that BundleRecon is compatible with the existing neural implicit multi-view reconstruction methods and can improve their reconstruction quality.
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.