 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaEviScrib: Mamba and Evidence-Guided Consistency Make CNN Work Robustly for Scribble-Based Weakly Supervised Ultrasound Image Segmentation
Sep 28, 2024



Segmenting anatomical structures and lesions from ultrasound images contributes to disease assessment, diagnosis, and treatment. Weakly supervised learning (WSL) based on sparse annotation has achieved encouraging performance and demonstrated the potential to reduce annotation costs. However, ultrasound images often suffer from issues such as poor contrast, unclear edges, as well as varying sizes and locations of lesions. This makes it challenging for convolutional networks with local receptive fields to extract global morphological features from the sparse information provided by scribble annotations. Recently, the visual Mamba based on state space sequence models (SSMs) has significantly reduced computational complexity while ensuring long-range dependencies compared to Transformers. Consequently, for the first time, we apply scribble-based WSL to ultrasound image segmentation and propose a novel hybrid CNN-Mamba framework. Furthermore, due to the characteristics of ultrasound images and insufficient supervision signals, existing consistency regularization often filters out predictions near decision boundaries, leading to unstable predictions of edges. Hence, we introduce the Dempster-Shafer theory (DST) of evidence to devise an Evidence-Guided Consistency (EGC) strategy, which leverages high-evidence predictions more likely to occur near high-density regions to guide low-evidence predictions potentially present near decision boundaries for optimization. During training, the collaboration between the CNN branch and the Mamba branch in the proposed framework draws inspiration from each other based on the EGC strategy. Extensive experiments on four ultrasound public datasets for binary-class and multi-class segmentation demonstrate the competitiveness of the proposed method. The scribble-annotated dataset and code will be made available on https://github.com/GtLinyer/MambaEviScrib.
EDMAE: An Efficient Decoupled Masked Autoencoder for Standard View Identification in Pediatric Echocardiography
Mar 17, 2023
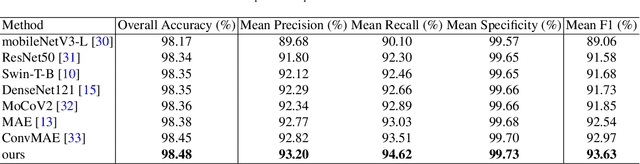

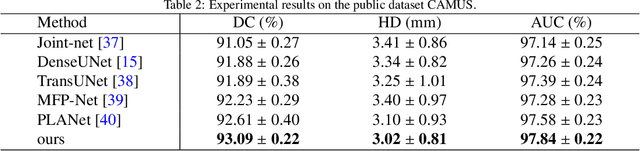
An efficient decoupled masked autoencoder (EDMAE), which is a novel self-supervised method is proposed for standard view recognition in pediatric echocardiography in this paper. The proposed EDMAE based on the encoder-decoder structure forms a new proxy task. The decoder of EDMAE consists of a teacher encoder and a student encoder, in which the teacher encoder extracts the latent representation of the masked image blocks, while the student encoder extracts the latent representation of the visible image blocks. A loss is calculated between the feature maps output from two encoders to ensure consistency in the latent representations they extracted. EDMAE replaces the VIT structure in the encoder of traditional MAE with pure convolution operation to improve training efficiency. EDMAE is pre-trained in a self-supervised manner on a large-scale private dataset of pediatric echocardiography, and then fine-tuned on the downstream task of standard view recognition. The high classification accuracy is achieved in 27 standard views of pediatric echocardiography. To further validate the effectiveness of the proposed method, another downstream task of cardiac ultrasound segmentation is performed on a public dataset CAMUS. The experiments show that the proposed method not only can surpass some recent supervised methods but also has more competitiveness on different downstream tasks.
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.
LEDCNet: A Lightweight and Efficient Semantic Segmentation Algorithm Using Dual Context Module for Extracting Ground Objects from UAV Aerial Remote Sensing Images
Dec 27, 2022


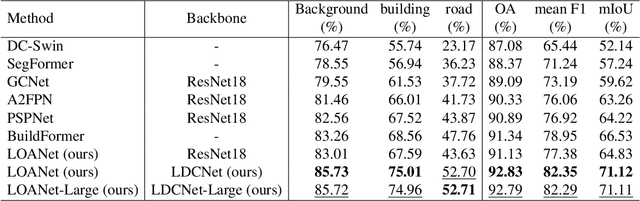
Semantic segmentation for extracting ground objects, such as road and house, from UAV remote sensing images by deep learning becomes a more efficient and convenient method than traditional manual segmentation in surveying and mapping field. In recent years, with the deepening of layers and boosting of complexity, the number of parameters in convolution-based semantic segmentation neural networks considerably increases, which is obviously not conducive to the wide application especially in the industry. In order to make the model lightweight and improve the model accuracy, a new lightweight and efficient network for the extraction of ground objects from UAV remote sensing images, named LEDCNet, is proposed. The proposed network adopts an encoder-decoder architecture in which a powerful lightweight backbone network called LDCNet is developed as the encoder. We would extend the LDCNet become a new generation backbone network of lightweight semantic segmentation algorithms. In the decoder part, the dual multi-scale context modules which consist of the ASPP module and the OCR module are designed to capture more context information from feature maps of UAV remote sensing images. Between ASPP and OCR, a FPN module is used to and fuse multi-scale features extracting from ASPP. A private dataset of remote sensing images taken by UAV which contains 2431 training sets, 945 validation sets, and 475 test sets is constructed. The proposed model performs well on this dataset, with only 1.4M parameters and 5.48G FLOPs, achieving an mIoU of 71.12%. The more extensive experiments on the public LoveDA dataset and CITY-OSM dataset to further verify the effectiveness of the proposed model with excellent results on mIoU of 65.27% and 74.39%, respectively. All the experimental results show the proposed model can not only lighten the network with few parameters but also improve the segmentation performance.