 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Instrumental and Proximal Causal Inference with Gaussian Processes
Mar 02, 2026Instrumental variable (IV) and proximal causal learning (Proxy) methods are central frameworks for causal inference in the presence of unobserved confounding. Despite substantial methodological advances, existing approaches rarely provide reliable epistemic uncertainty (EU) quantification. We address this gap through a Deconditional Gaussian Process (DGP) framework for uncertainty-aware causal learning. Our formulation recovers popular kernel estimators as the posterior mean, ensuring predictive precision, while the posterior variance yields principled and well-calibrated EU. Moreover, the probabilistic structure enables systematic model selection via marginal log-likelihood optimization. Empirical results demonstrate strong predictive performance alongside informative EU quantification, evaluated via empirical coverage frequencies and decision-aware accuracy rejection curves. Together, our approach provides a unified, practical solution for causal inference under unobserved confounding with reliable uncertainty.
ALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
CloseUpShot: Close-up Novel View Synthesis from Sparse-views via Point-conditioned Diffusion Model
Nov 17, 2025Reconstructing 3D scenes and synthesizing novel views from sparse input views is a highly challenging task. Recent advances in video diffusion models have demonstrated strong temporal reasoning capabilities, making them a promising tool for enhancing reconstruction quality under sparse-view settings. However, existing approaches are primarily designed for modest viewpoint variations, which struggle in capturing fine-grained details in close-up scenarios since input information is severely limited. In this paper, we present a diffusion-based framework, called CloseUpShot, for close-up novel view synthesis from sparse inputs via point-conditioned video diffusion. Specifically, we observe that pixel-warping conditioning suffers from severe sparsity and background leakage in close-up settings. To address this, we propose hierarchical warping and occlusion-aware noise suppression, enhancing the quality and completeness of the conditioning images for the video diffusion model. Furthermore, we introduce global structure guidance, which leverages a dense fused point cloud to provide consistent geometric context to the diffusion process, to compensate for the lack of globally consistent 3D constraints in sparse conditioning inputs. Extensive experiments on multiple datasets demonstrate that our method outperforms existing approaches, especially in close-up novel view synthesis, clearly validating the effectiveness of our design.
AMIA: Automatic Masking and Joint Intention Analysis Makes LVLMs Robust Jailbreak Defenders
May 30, 2025We introduce AMIA, a lightweight, inference-only defense for Large Vision-Language Models (LVLMs) that (1) Automatically Masks a small set of text-irrelevant image patches to disrupt adversarial perturbations, and (2) conducts joint Intention Analysis to uncover and mitigate hidden harmful intents before response generation. Without any retraining, AMIA improves defense success rates across diverse LVLMs and jailbreak benchmarks from an average of 52.4% to 81.7%, preserves general utility with only a 2% average accuracy drop, and incurs only modest inference overhead. Ablation confirms both masking and intention analysis are essential for a robust safety-utility trade-off.
Transformer representation learning is necessary for dynamic multi-modal physiological data on small-cohort patients
Apr 05, 2025



Postoperative delirium (POD), a severe neuropsychiatric complication affecting nearly 50% of high-risk surgical patients, is defined as an acute disorder of attention and cognition, It remains significantly underdiagnosed in the intensive care units (ICUs) due to subjective monitoring methods. Early and accurate diagnosis of POD is critical and achievable. Here, we propose a POD prediction framework comprising a Transformer representation model followed by traditional machine learning algorithms. Our approaches utilizes multi-modal physiological data, including amplitude-integrated electroencephalography (aEEG), vital signs, electrocardiographic monitor data as well as hemodynamic parameters. We curated the first multi-modal POD dataset encompassing two patient types and evaluated the various Transformer architectures for representation learning. Empirical results indicate a consistent improvements of sensitivity and Youden index in patient TYPE I using Transformer representations, particularly our fusion adaptation of Pathformer. By enabling effective delirium diagnosis from postoperative day 1 to 3, our extensive experimental findings emphasize the potential of multi-modal physiological data and highlight the necessity of representation learning via multi-modal Transformer architecture in clinical diagnosis.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
The Energy Loss Phenomenon in RLHF: A New Perspective on Mitigating Reward Hacking
Jan 31, 2025



This work identifies the Energy Loss Phenomenon in Reinforcement Learning from Human Feedback (RLHF) and its connection to reward hacking. Specifically, energy loss in the final layer of a Large Language Model (LLM) gradually increases during the RL process, with an excessive increase in energy loss characterizing reward hacking. Beyond empirical analysis, we further provide a theoretical foundation by proving that, under mild conditions, the increased energy loss reduces the upper bound of contextual relevance in LLMs, which is a critical aspect of reward hacking as the reduced contextual relevance typically indicates overfitting to reward model-favored patterns in RL. To address this issue, we propose an Energy loss-aware PPO algorithm (EPPO) which penalizes the increase in energy loss in the LLM's final layer during reward calculation to prevent excessive energy loss, thereby mitigating reward hacking. We theoretically show that EPPO can be conceptually interpreted as an entropy-regularized RL algorithm, which provides deeper insights into its effectiveness. Extensive experiments across various LLMs and tasks demonstrate the commonality of the energy loss phenomenon, as well as the effectiveness of \texttt{EPPO} in mitigating reward hacking and improving RLHF performance.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Dec 05, 2024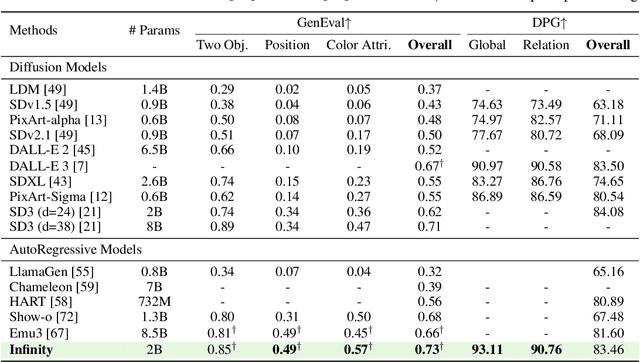

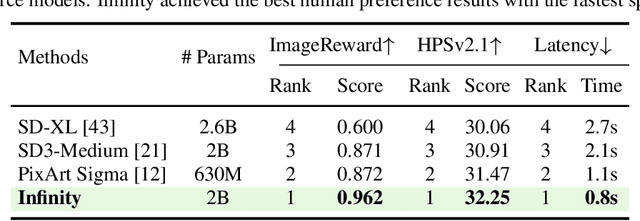

We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution, photorealistic images following language instruction. Infinity redefines visual autoregressive model under a bitwise token prediction framework with an infinite-vocabulary tokenizer & classifier and bitwise self-correction mechanism, remarkably improving the generation capacity and details. By theoretically scaling the tokenizer vocabulary size to infinity and concurrently scaling the transformer size, our method significantly unleashes powerful scaling capabilities compared to vanilla VAR. Infinity sets a new record for autoregressive text-to-image models, outperforming top-tier diffusion models like SD3-Medium and SDXL. Notably, Infinity surpasses SD3-Medium by improving the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, achieving a win rate of 66%. Without extra optimization, Infinity generates a high-quality 1024x1024 image in 0.8 seconds, making it 2.6x faster than SD3-Medium and establishing it as the fastest text-to-image model. Models and codes will be released to promote further exploration of Infinity for visual generation and unified tokenizer modeling.
A Semi-Supervised Approach with Error Reflection for Echocardiography Segmentation
Dec 01, 2024



Segmenting internal structure from echocardiography is essential for the diagnosis and treatment of various heart diseases. Semi-supervised learning shows its ability in alleviating annotations scarcity. While existing semi-supervised methods have been successful in image segmentation across various medical imaging modalities, few have attempted to design methods specifically addressing the challenges posed by the poor contrast, blurred edge details and noise of echocardiography. These characteristics pose challenges to the generation of high-quality pseudo-labels in semi-supervised segmentation based on Mean Teacher. Inspired by human reflection on erroneous practices, we devise an error reflection strategy for echocardiography semi-supervised segmentation architecture. The process triggers the model to reflect on inaccuracies in unlabeled image segmentation, thereby enhancing the robustness of pseudo-label generation. Specifically, the strategy is divided into two steps. The first step is called reconstruction reflection. The network is tasked with reconstructing authentic proxy images from the semantic masks of unlabeled images and their auxiliary sketches, while maximizing the structural similarity between the original inputs and the proxies. The second step is called guidance correction. Reconstruction error maps decouple unreliable segmentation regions. Then, reliable data that are more likely to occur near high-density areas are leveraged to guide the optimization of unreliable data potentially located around decision boundaries. Additionally, we introduce an effective data augmentation strategy, termed as multi-scale mixing up strategy, to minimize the empirical distribution gap between labeled and unlabeled images and perceive diverse scales of cardiac anatomical structures. Extensive experiments demonstrate the competitiveness of the proposed method.