 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempDiffReg: Temporal Diffusion Model for Non-Rigid 2D-3D Vascular Registration
Jan 26, 2026Transarterial chemoembolization (TACE) is a preferred treatment option for hepatocellular carcinoma and other liver malignancies, yet it remains a highly challenging procedure due to complex intra-operative vascular navigation and anatomical variability. Accurate and robust 2D-3D vessel registration is essential to guide microcatheter and instruments during TACE, enabling precise localization of vascular structures and optimal therapeutic targeting. To tackle this issue, we develop a coarse-to-fine registration strategy. First, we introduce a global alignment module, structure-aware perspective n-point (SA-PnP), to establish correspondence between 2D and 3D vessel structures. Second, we propose TempDiffReg, a temporal diffusion model that performs vessel deformation iteratively by leveraging temporal context to capture complex anatomical variations and local structural changes. We collected data from 23 patients and constructed 626 paired multi-frame samples for comprehensive evaluation. Experimental results demonstrate that the proposed method consistently outperforms state-of-the-art (SOTA) methods in both accuracy and anatomical plausibility. Specifically, our method achieves a mean squared error (MSE) of 0.63 mm and a mean absolute error (MAE) of 0.51 mm in registration accuracy, representing 66.7\% lower MSE and 17.7\% lower MAE compared to the most competitive existing approaches. It has the potential to assist less-experienced clinicians in safely and efficiently performing complex TACE procedures, ultimately enhancing both surgical outcomes and patient care. Code and data are available at: \textcolor{blue}{https://github.com/LZH970328/TempDiffReg.git}
Mamba2MIL: State Space Duality Based Multiple Instance Learning for Computational Pathology
Aug 27, 2024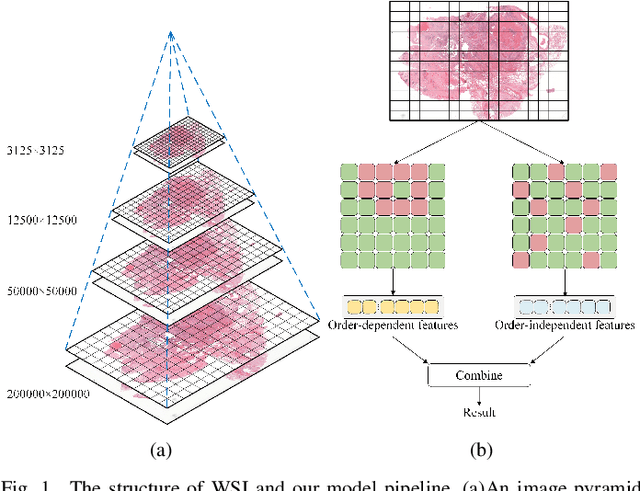
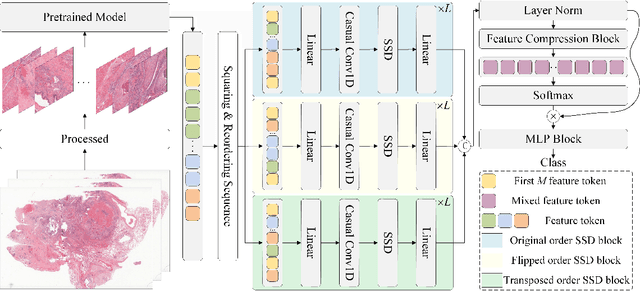
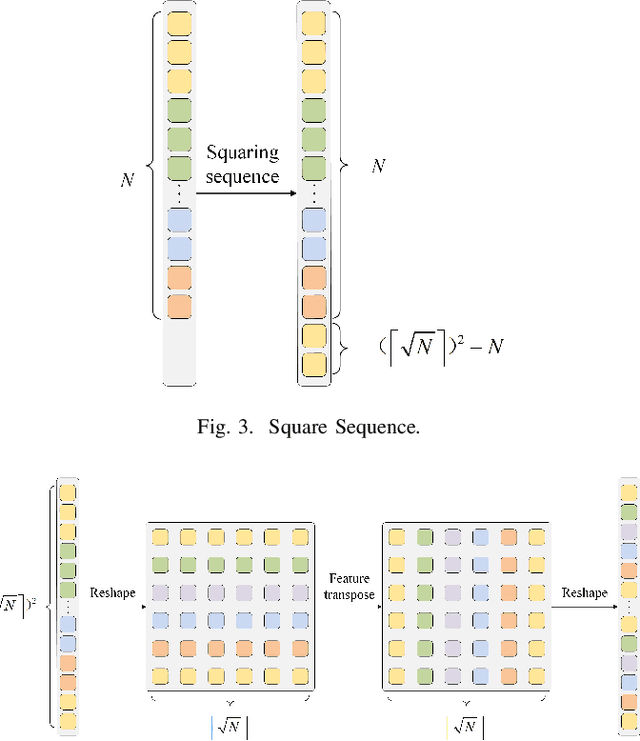

Computational pathology (CPath) has significantly advanced the clinical practice of pathology. Despite the progress made, Multiple Instance Learning (MIL), a promising paradigm within CPath, continues to face challenges, particularly related to incomplete information utilization. Existing frameworks, such as those based on Convolutional Neural Networks (CNNs), attention, and selective scan space state sequential model (SSM), lack sufficient flexibility and scalability in fusing diverse features, and cannot effectively fuse diverse features. Additionally, current approaches do not adequately exploit order-related and order-independent features, resulting in suboptimal utilization of sequence information. To address these limitations, we propose a novel MIL framework called Mamba2MIL. Our framework utilizes the state space duality model (SSD) to model long sequences of patches of whole slide images (WSIs), which, combined with weighted feature selection, supports the fusion processing of more branching features and can be extended according to specific application needs. Moreover, we introduce a sequence transformation method tailored to varying WSI sizes, which enhances sequence-independent features while preserving local sequence information, thereby improving sequence information utilization. Extensive experiments demonstrate that Mamba2MIL surpasses state-of-the-art MIL methods. We conducted extensive experiments across multiple datasets, achieving improvements in nearly all performance metrics. Specifically, on the NSCLC dataset, Mamba2MIL achieves a binary tumor classification AUC of 0.9533 and an accuracy of 0.8794. On the BRACS dataset, it achieves a multiclass classification AUC of 0.7986 and an accuracy of 0.4981. The code is available at https://github.com/YuqiZhang-Buaa/Mamba2MIL.
Learning Prototype via Placeholder for Zero-shot Recognition
Jul 29, 2022Zero-shot learning (ZSL) aims to recognize unseen classes by exploiting semantic descriptions shared between seen classes and unseen classes. Current methods show that it is effective to learn visual-semantic alignment by projecting semantic embeddings into the visual space as class prototypes. However, such a projection function is only concerned with seen classes. When applied to unseen classes, the prototypes often perform suboptimally due to domain shift. In this paper, we propose to learn prototypes via placeholders, termed LPL, to eliminate the domain shift between seen and unseen classes. Specifically, we combine seen classes to hallucinate new classes which play as placeholders of the unseen classes in the visual and semantic space. Placed between seen classes, the placeholders encourage prototypes of seen classes to be highly dispersed. And more space is spared for the insertion of well-separated unseen ones. Empirically, well-separated prototypes help counteract visual-semantic misalignment caused by domain shift. Furthermore, we exploit a novel semantic-oriented fine-tuning to guarantee the semantic reliability of placeholders. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of LPL over the state-of-the-art methods. Code is available at https://github.com/zaiquanyang/LPL.