 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Artificial Intelligence Models for Future Wireless Communications
Jan 11, 2026The anticipated integration of large artificial intelligence (AI) models with wireless communications is estimated to usher a transformative wave in the forthcoming information age. As wireless networks grow in complexity, the traditional methodologies employed for optimization and management face increasingly challenges. Large AI models have extensive parameter spaces and enhanced learning capabilities and can offer innovative solutions to these challenges. They are also capable of learning, adapting and optimizing in real-time. We introduce the potential and challenges of integrating large AI models into wireless communications, highlighting existing AIdriven applications and inherent challenges for future large AI models. In this paper, we propose the architecture of large AI models for future wireless communications, introduce their advantages in data analysis, resource allocation and real-time adaptation, discuss the potential challenges and corresponding solutions of energy, architecture design, privacy, security, ethical and regulatory. In addition, we explore the potential future directions of large AI models in wireless communications, laying the groundwork for forthcoming research in this area.
Semantic Transmission Framework in Direct Satellite Communications
Jan 01, 2026Insufficient link budget has become a bottleneck problem for direct access in current satellite communications. In this paper, we develop a semantic transmission framework for direct satellite communications as an effective and viable solution to tackle this problem. To measure the tradeoffs between communication, computation, and generation quality, we introduce a semantic efficiency metric with optimized weights. The optimization aims to maximize the average semantic efficiency metric by jointly optimizing transmission mode selection, satellite-user association, ISL task migration, denoising steps, and adaptive weights, which is a complex nonlinear integer programming problem. To maximize the average semantic efficiency metric, we propose a decision-assisted REINFORCE++ algorithm that utilizes feasibility-aware action space and a critic-free stabilized policy update. Numerical results show that the proposed algorithm achieves higher semantic efficiency than baselines.
Flexible Reconfigurable Intelligent Surface-Aided Covert Communications in UAV Networks
Dec 10, 2025



In recent years, unmanned aerial vehicles (UAVs) have become a key role in wireless communication networks due to their flexibility and dynamic adaptability. However, the openness of UAV-based communications leads to security and privacy concerns in wireless transmissions. This paper investigates a framework of UAV covert communications which introduces flexible reconfigurable intelligent surfaces (F-RIS) in UAV networks. Unlike traditional RIS, F-RIS provides advanced deployment flexibility by conforming to curved surfaces and dynamically reconfiguring its electromagnetic properties to enhance the covert communication performance. We establish an electromagnetic model for F-RIS and further develop a fitted model that describes the relationship between F-RIS reflection amplitude, reflection phase, and incident angle. To maximize the covert transmission rate among UAVs while meeting the covert constraint and public transmission constraint, we introduce a strategy of jointly optimizing UAV trajectories, F-RIS reflection vectors, F-RIS incident angles, and non-orthogonal multiple access (NOMA) power allocation. Considering this is a complicated non-convex optimization problem, we propose a deep reinforcement learning (DRL) algorithm-based optimization solution. Simulation results demonstrate that our proposed framework and optimization method significantly outperform traditional benchmarks, and highlight the advantages of F-RIS in enhancing covert communication performance within UAV networks.
QoE Optimization for Semantic Self-Correcting Video Transmission in Multi-UAV Networks
Jul 09, 2025
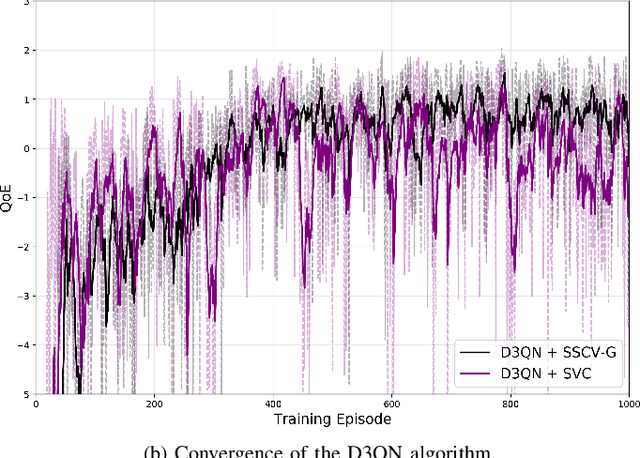
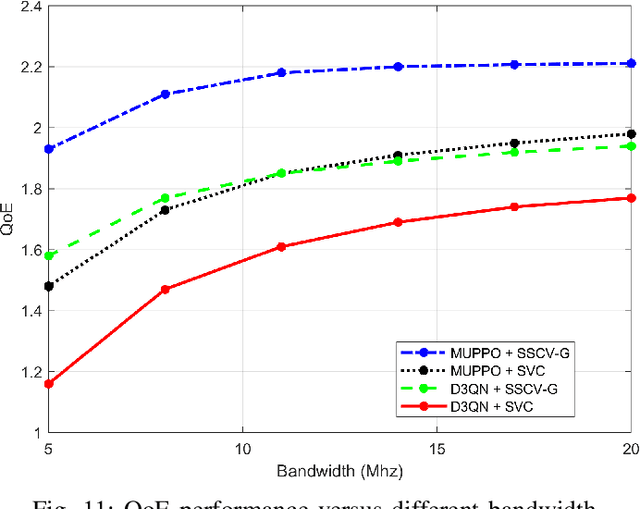
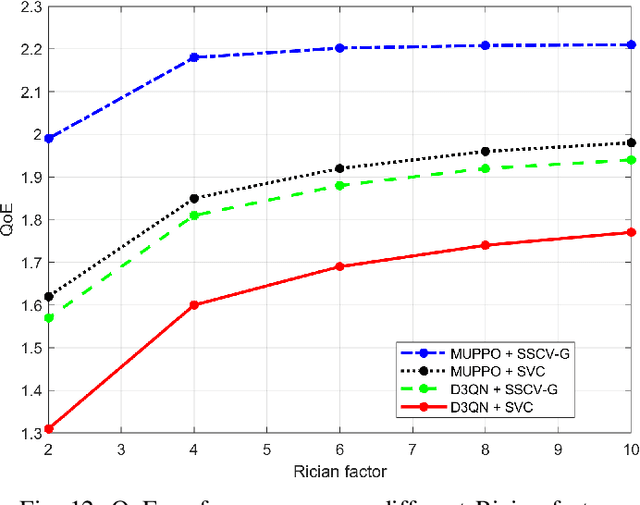
Real-time unmanned aerial vehicle (UAV) video streaming is essential for time-sensitive applications, including remote surveillance, emergency response, and environmental monitoring. However, it faces challenges such as limited bandwidth, latency fluctuations, and high packet loss. To address these issues, we propose a novel semantic self-correcting video transmission framework with ultra-fine bitrate granularity (SSCV-G). In SSCV-G, video frames are encoded into a compact semantic codebook space, and the transmitter adaptively sends a subset of semantic indices based on bandwidth availability, enabling fine-grained bitrate control for improved bandwidth efficiency. At the receiver, a spatio-temporal vision transformer (ST-ViT) performs multi-frame joint decoding to reconstruct dropped semantic indices by modeling intra- and inter-frame dependencies. To further improve performance under dynamic network conditions, we integrate a multi-user proximal policy optimization (MUPPO) reinforcement learning scheme that jointly optimizes communication resource allocation and semantic bitrate selection to maximize user Quality of Experience (QoE). Extensive experiments demonstrate that the proposed SSCV-G significantly outperforms state-of-the-art video codecs in coding efficiency, bandwidth adaptability, and packet loss robustness. Moreover, the proposed MUPPO-based QoE optimization consistently surpasses existing benchmarks.
Widely Linear Augmented Extreme Learning Machine Based Impairments Compensation for Satellite Communications
Jun 17, 2025Satellite communications are crucial for the evolution beyond fifth-generation networks. However, the dynamic nature of satellite channels and their inherent impairments present significant challenges. In this paper, a novel post-compensation scheme that combines the complex-valued extreme learning machine with augmented hidden layer (CELMAH) architecture and widely linear processing (WLP) is developed to address these issues by exploiting signal impropriety in satellite communications. Although CELMAH shares structural similarities with WLP, it employs a different core algorithm and does not fully exploit the signal impropriety. By incorporating WLP principles, we derive a tailored formulation suited to the network structure and propose the CELM augmented by widely linear least squares (CELM-WLLS) for post-distortion. The proposed approach offers enhanced communication robustness and is highly effective for satellite communication scenarios characterized by dynamic channel conditions and non-linear impairments. CELM-WLLS is designed to improve signal recovery performance and outperform traditional methods such as least square (LS) and minimum mean square error (MMSE). Compared to CELMAH, CELM-WLLS demonstrates approximately 0.8 dB gain in BER performance, and also achieves a two-thirds reduction in computational complexity, making it a more efficient solution.
The Communication and Computation Trade-off in Wireless Semantic Communications
Apr 14, 2025
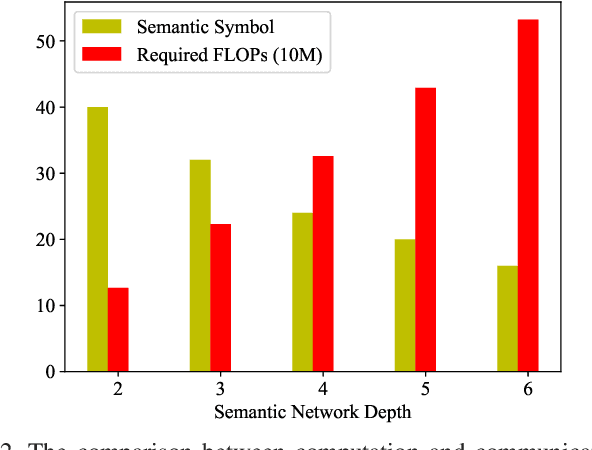
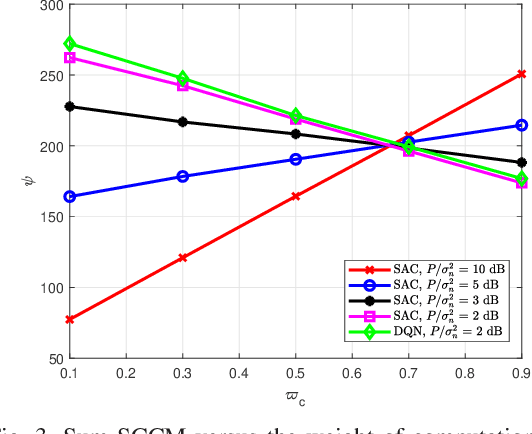
Semantic communications have emerged as a crucial research direction for future wireless communication networks. However, as wireless systems become increasingly complex, the demands for computation and communication resources in semantic communications continue to grow rapidly. This paper investigates the trade-off between computation and communication in wireless semantic communications, taking into consideration transmission task delay and performance constraints within the semantic communication framework. We propose a novel tradeoff metric to analyze the balance between computation and communication in semantic transmissions and employ the deep reinforcement learning (DRL) algorithm to minimize this metric, thereby reducing the cost associated with balancing computation and communication. Through simulations, we analyze the tradeoff between computation and communication and demonstrate the effectiveness of optimizing this trade-off metric.
Deep Learning-Based Traffic-Aware Base Station Sleep Mode and Cell Zooming Strategy in RIS-Aided Multi-Cell Networks
Dec 25, 2024



Advances in wireless technology have significantly increased the number of wireless connections, leading to higher energy consumption in networks. Among these, base stations (BSs) in radio access networks (RANs) account for over half of the total energy usage. To address this, we propose a multi-cell sleep strategy combined with adaptive cell zooming, user association, and reconfigurable intelligent surface (RIS) to minimize BS energy consumption. This approach allows BSs to enter sleep during low traffic, while adaptive cell zooming and user association dynamically adjust coverage to balance traffic load and enhance data rates through RIS, minimizing the number of active BSs. However, it is important to note that the proposed method may achieve energy-savings at the cost of increased delay, requiring a trade-off between these two factors. Moreover, minimizing BS energy consumption under the delay constraint is a complicated non-convex problem. To address this issue, we model the RIS-aided multi-cell network as a Markov decision process (MDP) and use the proximal policy optimization (PPO) algorithm to optimize sleep mode (SM), cell zooming, and user association. Besides, we utilize a double cascade correlation network (DCCN) algorithm to optimize the RIS reflection coefficients. Simulation results demonstrate that PPO balances energy-savings and delay, while DCCN-optimized RIS enhances BS energy-savings. Compared to systems optimised by the benchmark DQN algorithm, energy consumption is reduced by 49.61%
Fair Resource Allocation For Hierarchical Federated Edge Learning in Space-Air-Ground Integrated Networks via Deep Reinforcement Learning with Hybrid Control
Aug 05, 2024



The space-air-ground integrated network (SAGIN) has become a crucial research direction in future wireless communications due to its ubiquitous coverage, rapid and flexible deployment, and multi-layer cooperation capabilities. However, integrating hierarchical federated learning (HFL) with edge computing and SAGINs remains a complex open issue to be resolved. This paper proposes a novel framework for applying HFL in SAGINs, utilizing aerial platforms and low Earth orbit (LEO) satellites as edge servers and cloud servers, respectively, to provide multi-layer aggregation capabilities for HFL. The proposed system also considers the presence of inter-satellite links (ISLs), enabling satellites to exchange federated learning models with each other. Furthermore, we consider multiple different computational tasks that need to be completed within a limited satellite service time. To maximize the convergence performance of all tasks while ensuring fairness, we propose the use of the distributional soft-actor-critic (DSAC) algorithm to optimize resource allocation in the SAGIN and aggregation weights in HFL. Moreover, we address the efficiency issue of hybrid action spaces in deep reinforcement learning (DRL) through a decoupling and recoupling approach, and design a new dynamic adjusting reward function to ensure fairness among multiple tasks in federated learning. Simulation results demonstrate the superiority of our proposed algorithm, consistently outperforming baseline approaches and offering a promising solution for addressing highly complex optimization problems in SAGINs.
Learning Prototype via Placeholder for Zero-shot Recognition
Jul 29, 2022Zero-shot learning (ZSL) aims to recognize unseen classes by exploiting semantic descriptions shared between seen classes and unseen classes. Current methods show that it is effective to learn visual-semantic alignment by projecting semantic embeddings into the visual space as class prototypes. However, such a projection function is only concerned with seen classes. When applied to unseen classes, the prototypes often perform suboptimally due to domain shift. In this paper, we propose to learn prototypes via placeholders, termed LPL, to eliminate the domain shift between seen and unseen classes. Specifically, we combine seen classes to hallucinate new classes which play as placeholders of the unseen classes in the visual and semantic space. Placed between seen classes, the placeholders encourage prototypes of seen classes to be highly dispersed. And more space is spared for the insertion of well-separated unseen ones. Empirically, well-separated prototypes help counteract visual-semantic misalignment caused by domain shift. Furthermore, we exploit a novel semantic-oriented fine-tuning to guarantee the semantic reliability of placeholders. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of LPL over the state-of-the-art methods. Code is available at https://github.com/zaiquanyang/LPL.
Hidden Technical Debts for Fair Machine Learning in Financial Services
Mar 22, 2021
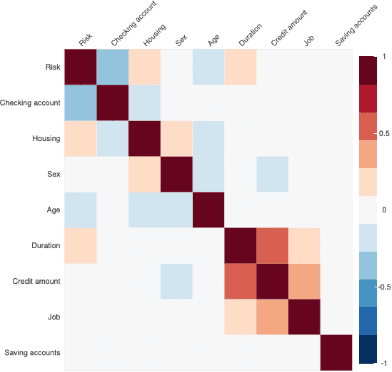
The recent advancements in machine learning (ML) have demonstrated the potential for providing a powerful solution to build complex prediction systems in a short time. However, in highly regulated industries, such as the financial technology (Fintech), people have raised concerns about the risk of ML systems discriminating against specific protected groups or individuals. To address these concerns, researchers have introduced various mathematical fairness metrics and bias mitigation algorithms. This paper discusses hidden technical debts and challenges of building fair ML systems in a production environment for Fintech. We explore various stages that require attention for fairness in the ML system development and deployment life cycle. To identify hidden technical debts that exist in building fair ML system for Fintech, we focus on key pipeline stages including data preparation, model development, system monitoring and integration in production. Our analysis shows that enforcing fairness for production-ready ML systems in Fintech requires specific engineering commitments at different stages of ML system life cycle. We also propose several initial starting points to mitigate these technical debts for deploying fair ML systems in production.