 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Hidden Technical Debts for Fair Machine Learning in Financial Services
Mar 22, 2021
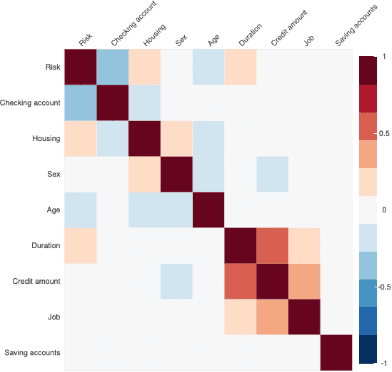
The recent advancements in machine learning (ML) have demonstrated the potential for providing a powerful solution to build complex prediction systems in a short time. However, in highly regulated industries, such as the financial technology (Fintech), people have raised concerns about the risk of ML systems discriminating against specific protected groups or individuals. To address these concerns, researchers have introduced various mathematical fairness metrics and bias mitigation algorithms. This paper discusses hidden technical debts and challenges of building fair ML systems in a production environment for Fintech. We explore various stages that require attention for fairness in the ML system development and deployment life cycle. To identify hidden technical debts that exist in building fair ML system for Fintech, we focus on key pipeline stages including data preparation, model development, system monitoring and integration in production. Our analysis shows that enforcing fairness for production-ready ML systems in Fintech requires specific engineering commitments at different stages of ML system life cycle. We also propose several initial starting points to mitigate these technical debts for deploying fair ML systems in production.